
Los Intel Xeon de cuarta generación son la apuesta de Intel para luchar de tú a tú tanto contra los AMD Zen 3D y Zen 4, bajo la arquitectura Sapphire Rapids estos incluyen una serie de mejoras importantes a nivel de arquitectura y una nueva forma de construir las CPU para servidor para Intel. Veamos que tal son.
La arquitectura Sapphire Rapids es la base de muchas tecnologías que vamos a ver en las CPU de la multinacional en estos momentos dirigida por Pat Gelsinger. Entre ellas está el uso de la tecnología AMX, pero especialmente la construcción de una CPU a través de tiles o chiplets por primera vez por parte de la multinacional azul.
Golden Cove, el núcleo de los próximos Xeon

Golden Cove es el nombre en clave de los núcleos principales del Xeon de cuarta generación bajo arquitectura Sapphire Rapids y tiene un ratio IPC sobre el 19% mayor que su antecesor, esto significa que resuelve a la misma velocidad de reloj un 19% más de instrucciones y por tanto es más rápido, todo ello es gracias a una serie de mejoras que Intel ha realizado en su nuevo procesador. Entre los cambios más importantes está el hecho que el decodificador de instrucciones en la unidad de control ha pasado de poder soportar 4 instrucciones a 6 instrucciones, lo que le permite alimentar las 12 unidades de ejecución.
Aunque su mayor novedad se encuentra en la unidad AMX, la cual es una unidad del tipo Tensorial como la de las GPU, pero con una diferencia, mientras que en el caso de las tarjetas gráficas el set de registros es compartido y por tanto su funcionamiento es conmutado con las unidades SIM, el AMX es una unidad de ejecución por sí misma que puede funcionar al mismo tiempo que el resto del procesador, ya que tiene su propio set de 1024 registros para uso exclusivo.
Diferencias con los Intel Core Gen 12

Lo primero que hemos de tener en cuenta es que la arquitectura Sapphire Rapids utiliza buena parte de las tecnologías que también se han implementado en Alder Lake al haber sido fabricados bajo el mismo nodo: Intel 7, antes conocido como 10 nm SuperFin.
Por lo que comparten núcleo principal, Golden Cove o llamado P-Core en el actual argot de la compañía. En cambio el Xeon Scalable Processor de cuarta generación no lleva en su interior los núcleos Gracemont o E-Core, pero las diferencias no terminan en este punto, ya que es muy posible que veamos modelos con hasta 20 núcleos por tile u 80 por procesador.
No obstante hay cambios importantes en los procesadores de Sapphire Rapids con respeto a su contrapartida para ordenadores domésticos, la primera de ellas es el hecho de tener la unidad AVX-512 activa y la segunda es el aumento de la caché L2 del procesador de los 1.25 a los 2 MB. Aunque la más grande es la cantidad de núcleos que hay en total el Sapphire Rapids, ya que al ser una CPU pensada para servidores y centros de datos se trata de una bestia que hace palidecer a Alder Lake con u
Aunque el cambio más importante no se encuentra en las unidades centrales de procesamiento, sino en un acelerador llamado Data Streaming Accelerator, el cual se trata de una unidad IOMMU que ha sido potenciada para el uso con hipervisores y por tanto sistemas operativos virtualizados, lo que hace que esté pensado para plataformas de computación en la nube desde el lado servidor.
¿A qué velocidad irán los Sapphire Rapids?

Por el momento desconocemos la velocidad de reloj de cada uno de los núcleos Golden Cove dentro de cada tile en Sapphire Rapids, pero sabemos que va a ser inferior que en Alder Lake y no por el hecho que lo hayan dicho desde Intel, sino por puro conocimiento del tema:
- Las instrucciones AVX-512 tienen un consumo energético más alto que el resto, para compensarlo al ejecutarlas se reduce la velocidad de reloj.
- Estamos ante una CPU de servidor, la cual va a funcionar en muchos casos 24 horas al día y 7 días a la semanas sin interrupción, no se puede permitir acelerones ni funcionar a altas velocidades de reloj.
- Siempre ha ocurrido que si se aumenta el número de núcleos de una CPU con la misma arquitectura la velocidad de reloj va bajando progresivamente, esto es debido a que es necesario reducir el coste de la comunicación.
Si comparamos con los actuales Ice Lake-SP basados en Cypress Cove veremos que su velocidad de reloj máxima es de 4.1 GHz, por lo que aún con desconocimiento sobre la especificación final podemos asegurar que no estará muy alejada dado que hacen uso de un proceso de fabricación muy similar.
Superando el límite de la retícula

El título os puede parecer confuso, pero hay que tener en cuenta que cuando se diseña un procesador existe un límite en cuanto a su tamaño, el cual es lo grande en área que puede ser. El motivo es que a más superficie tiene un chip no solo caben menos por oblea haciendo que sean más caros, sino también la cantidad de fallos que pueden aparecer es más grande. Por lo que al final no sale rentable hacerlos de ese tamaño.
La solución a la que ha llegado la industria son los chiplets, los cuales consisten en dividir un chip muy grande en varios más pequeños que trabajan como uno solo. La ventaja de esto es que podemos superar el límite de la retícula que tendríamos con un único chip a través de usar varios, lo que supone tener a la práctica el equivalente a un procesador más grande, con más transistores y por tanto con mayor complejidad.
Claro esta, que aquí entra el problema del coste de la comunicación en la conectividad. Al separar los chips lo que hacemos es aumentar la distancia del cableado y con ello acabamos incrementando el consumo energético de la comunicación. Veamos como lo ha hecho Intel en Sapphire Rapids.
EMIB en los Xeon de nueva generación
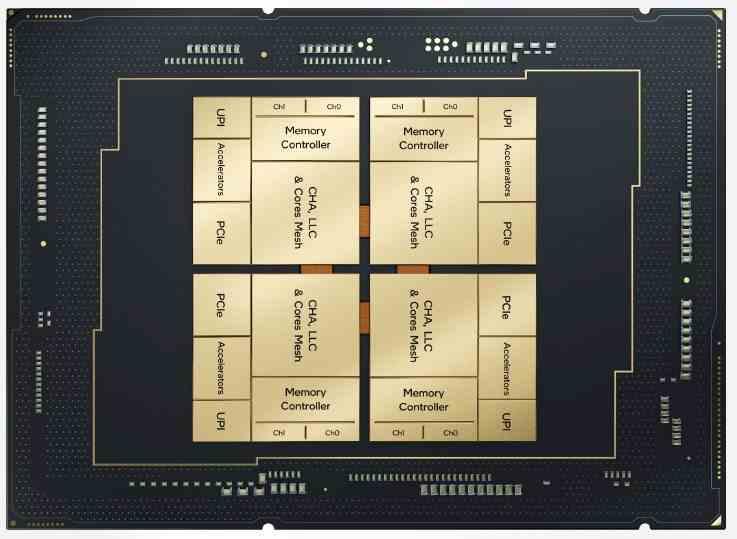
La solución más clara pasa por acortar los caminos, y para ello se hace uso de un interposer por debajo, el cual es una estructura de comunicación encargada de comunicarse en vertical con los procesadores y memorias que tiene en la parte superior. En la actualidad hay dos formas de hacerlo, a través de vías de silicio o puentes de idem, siendo la tecnología EMIB de Intel del segundo tipo y es la encargada de que los cuatro tiles se comuniquen entre ellos.
Mientras que en la arquitectura Zen 2 y Zen 3 de AMD la caché de último nivel o LLC se encuentra en chiplet CCD, en el caso de Sapphire Rapids está dividida entre los diferentes tiles. ¿Qué tiene de especial dicha caché en todo procesador? Debido a que desde el primero hasta el último de los núcleos hacen uso del mismo pozo de memoria RAM, la caché de mayor nivel se comparte para todos ellos, es global y no local y por tanto cada tile en la arquitectura Sapphire Rapids ha de tener acceso a la parte de la LLC que se encuentra en los otros a la misma velocidad que accedería a la suya propia.
Los puentes de silicio lo que hacen es comunicar las diferentes partes de la caché de último nivel que se encuentra en cada uno de los tiles de tal manera que solo no exista latencia adicional. También lo que hace es reducir el coste energético de comunicación, al final el efecto es el mismo que tener un solo chip a efectos prácticos, pero sin un límite de tamaño en cuánto a su área.
Soporte CXL 1.1 en Sapphire Rapids
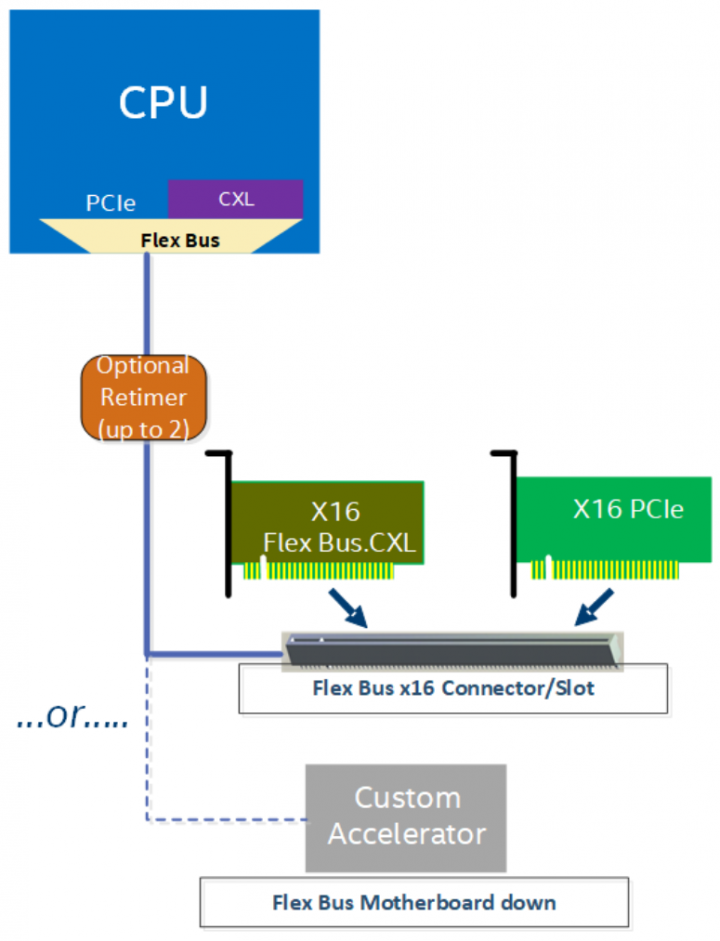
El CXL va a ser uno de los estándares más importantes en los próximos años, desgraciadamente Sapphire Rapids no soporta todo el estándar al completo. ¿Y de qué trata dicha tecnología? Se trata de una mejora sobre la interfaz PCI Express que otorga coherencia de caché a los procesadores, expansiones de memoria y dispositivos. Lo que hace que todos ellos compartan el mismo direccionamiento.
El estándar tiene CXL tiene tres protocolos que son CXL-IO, CXL-CACHE y CXL-MEMORY. ¿Su limitación? No soporta el último protocolo y esto significa que no solo las expansiones de RAM vía PCIe con coherencia no están soportadas, sino también la memoria HBM2e de ciertos modelos del procesador no estarían en el mismo espacio de direccionamiento, aunque esto no sería así incluso con el soporte completo para el Compute Express Link dado que la comunicación con las memorias High Bandwidth Memory se realiza a través de cuatro puentes EMIB adicionales, por lo que no comparten el mismo espacio de memoria.