
Las GPUs al igual que las CPU son un tipo de procesador, pero están optimizadas para el cálculo en paralelo y la generación de gráficos en tiempo real. No obstante, pese a que tenemos diferentes tipos de arquitecturas, todas y cada una de las GPU tienen una organización en y que por tanto comparten. La cual os vamos a explicar en este artículo de manera detallada y pormenorizada.
En este artículo no vamos a tratar una arquitectura de GPU en concreto, sino la de todas en general y por tanto que a la hora de ver el diagrama que suelen lanzar los fabricantes sobre la organización de su siguiente GPU podáis entenderlo sin problemas. Independientemente de si esta es una GPU integrada o dedicada y del grado de potencia que estas tienen.
Organización de una GPU contemporánea

Para entender cómo se organiza una GPU hemos de pensar en una muñeca rusa o matrioshka, la cual está compuesta por varias muñecas en su interior. Lo cual también lo podríamos hablar de un conjunto almacenando una serie de subconjuntos de manera progresiva. Dicho de otra manera, las GPUs están organizadas de tal manera que los diferentes conjuntos que las componen se encuentran en muchos casos unos dentro de otros.
Gracias a esta división vamos a entender mucho mejor algo tan complejo como es una GPU, ya que a partir de lo simple podemos construir lo complejo. Dicho esto, empecemos por el primer componente.
Conjunto A en la organización de una GPU: las unidades shader
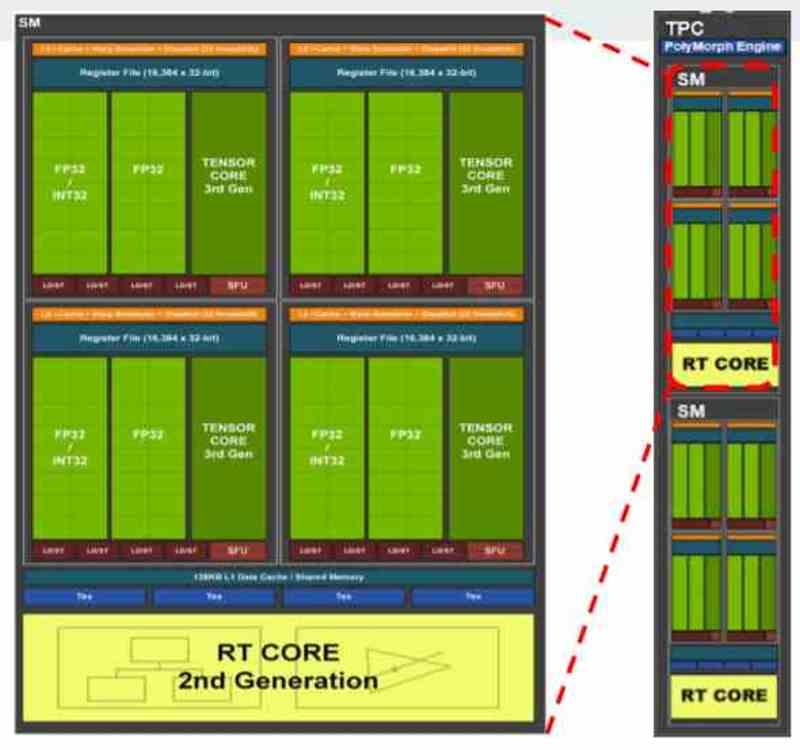
El primero de los conjuntos son las unidades shader. Por ellas mismas son procesadores, pero al contrario que las CPU no están pensadas para el paralelismo a partir de las instrucciones, ILP, sino a partir de los hilos de ejecución, TLP. Independientemente de si estamos hablando de las GPU de AMD, NVIDIA, Intel o cualquier otra marca, toda GPU contemporánea se compone de:
- Unidades SIMD y sus registros
- Unidades Escalares y sus registros.
- Planificador
- Memoria Local Compartida
- Unidad de Filtrado de Texturas
- Caché de datos y/o texturas de primer nivel
- Unidades Load/Store para mover datos desde y hacia la caché y la memoria compartida.
- Unidad de Intersección de Rayos.
- Arrays Sistólicos o unidades tensor
- Export Bus que exporta datos hacia fuera del Conjunto A y hacía los diferentes componentes del Conjunto B.
Conjunto B en la organización de una GPU: Shader Array/Shader Engine/GPC
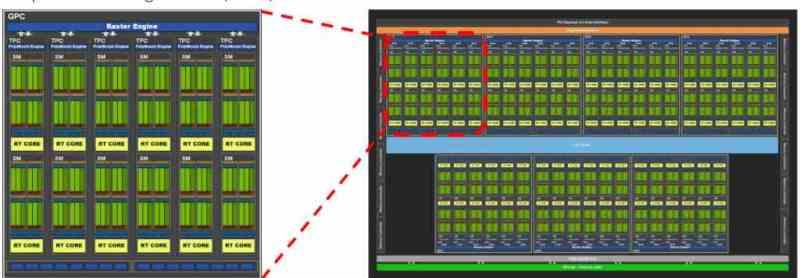
El Conjunto B incluye en su interior al conjunto A en su interior, pero de entrada añade las cachés de instrucciones y de constantes. En las GPU al igual que las CPU la caché de primer nivel se encuentran divididas en dos partes, una para datos y la otra para instrucciones. La diferencia es que en el caso de las GPU la caché de instrucciones se encuentra fuera de las unidades shader y por tanto se encuentran en el conjunto B.
El conjunto B en la organización de una GPU por lo tanto incluye una serie de unidades shader, que se comunican entre sí a través de la interfaz de comunicación en común entre ellas, lo que les permite comunicarse entre sí. Por otro lado las diferentes unidades shader no están solas en el Conjunto B, ya que es aquí donde hay varias unidades de función fija para el renderizado de los gráficos, como ahora.
- Unidad de Primitivas: Esta es invocada durante el World Space Pipeline o Pipeline Geométrico, se encarga de realizar la teselación de la geometría de la escena.
- Unidad de Rasterizado: Realiza el rasterizado de las primitivas, convirtiendo los triángulos en fragmentos de pixeles y siendo su etapa la que empieza el llamado Screen Space Pipeline o Fase de Rasterización.
- ROPS: Unidades que escriben los búferes de imagen, actúan durante dos etapas. En la fase de rasterizado previa a la de texturizado generan el búfer de profundidad (Z-Buffer) mientras que en la fase posterior al texturizado reciben el resultado de esta etapa para generar el Color Buffer o los diferentes Render Targets (renderizado en diferido).
Conjunto C en la arquitectura de una GPU:
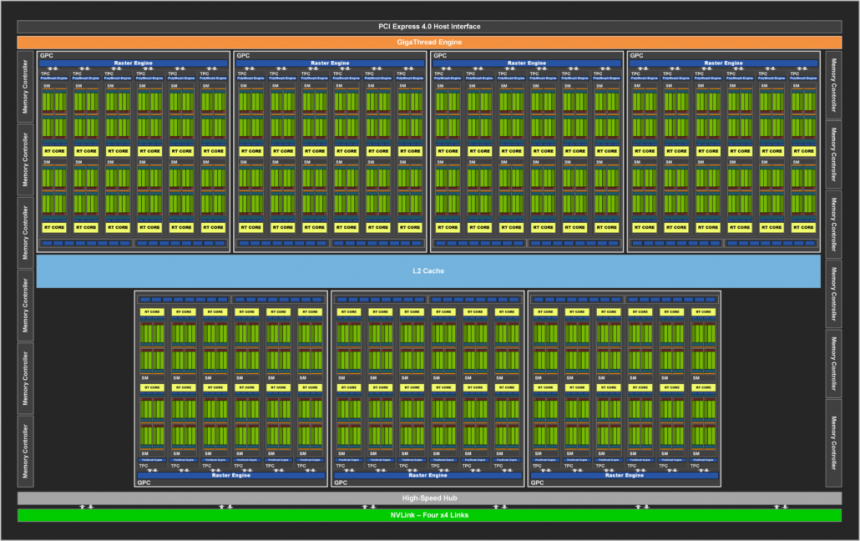
Ya tenemos casi la GPU completa o la GPU sin los aceleradores, se compone de los siguientes componentes:
- Varios Conjuntos B en su interior.
- Memoria Global Compartida: Un Scratchpad y por tanto fuera de la jerarquía de caches para comunicar los Conjuntos B entre si.
- Unidad Geométrica: Tiene la capacidad de leer los punteros a la RAM que apuntan a la geometría de la escena, con ello es posible eliminar geometría no visible o superflua para que no se renderice inútilmente en el fotograma.
- Procesadores de Comandos (Gráficos y Computación)
- Caché de Último Nivel: Todos los elementos de la GPU son clientes de esta caché por lo que tiene que tener un anillo de comunicación inmenso, todos los componentes del Conjunto B tienen contacto directo con la caché L2 así como todos los componentes del propio Conjunto C.
La caché de Último Nivel o Last Level Cache (LLC) es importante ya que es la cache que nos da coherencia entre todos los elementos del Conjunto C entre si incluyendo obviamente los Conjuntos B dentro del mismo. No solo eso sino que permite no sobre-saturar el controlador de memoria externa ya que con esto es la propia LLC junto a la o las unidades MMU de la GPU las que se encargan de hacer la captación de instrucciones y datos desde la RAM. Pensad en la Last Level Cache como una especie de almacén de logística en la que todos los elementos del Conjunto C envían y/o reciben sus paquetes y la logística de los mismos está controlada por la MMU que es la unidad encargada de hacerlo.
Conjunto final, la GPU al completo

Con todo esto ya tenemos la GPU al completo, el conjunto D incluye la unidad principal que es la GPU encargada de renderizar los gráficos de nuestros juegos favoritos, pero no es el nivel más alto de una GPU, ya que nos faltan una serie de coprocesadores de apoyo. Estos no actúan para renderizar los gráficos de manera directa, pero sin ellos la GPU no podría funcionar. Por lo general estos elementos son:
- La Unidad GFX incluyendo su caché de último nivel
- El puente Norte o Northbridge de la GPU, si esta se encuentra en un SoC heterogéneo (con una CPU) pero con un pozo de memoria compartido entonces utilizarán un Northbridge común. Todos los elementos del Conjunto D se encuentran conectados al Northbridge
- Aceleradores: Codificadores de Vídeo, Adaptadores de Pantalla, se encuentran conectados al Northbridge. En el caso del Adaptador de Pantalla es el que envía la señal de video al puerto DisplayPort o al HDMI
- Unidades DMA: Si hay dos espacios de direccionamiento de La RAM (incluso con un mismo pozo físico) la unidad DMA permite pasar datos de un espacio de la RAM a otra. En el caso de que sea una GPU aparte las unidades DMA sirven como comunicación con la CPU u otras GPUs.
- Controlador e interfaz de memoria: Permite Comunicar los elementos de Conjunto D con la RAM externa. Se encuentran conectados al Northbridge y es el único camino de entrada a la RAM exterior.
Con todo esto ya tenéis la organización completa de una GPU, con lo cual podréis leer mucho mejor el diagrama de una GPU y entender cómo se organiza internamente.