
Uno de los conceptos clave para entender la arquitectura y el rendimiento de las actuales CPU de Intel y AMD es el concepto de las microoperaciones, así como de unidades como la caché de las mismas. En este artículo os comentaremos de manera accesible que son y porque los procesadores en la actualidad basan todo su funcionamiento en ellas para alcanzar el máximo rendimiento posible.
En la actualidad una CPU puede ejecutar una gran cantidad de instrucciones distintas y lo hace a frecuencias que son hasta 5000 veces más altas que la de los primeros ordenadores personales. Solemos pensar y de forma completamente errónea que la mayor cantidad de MHz o GHz se debe a los nuevos de fabricación. La realidad es muy distinta, y es aquí donde entran las microoperaciones, las cuales son clave para alcanzar la enorme potencia de cálculo de los microprocesadores de la actualidad.
¿Qué son las microoperaciones?
Uno de los símiles con la realidad que se suelen utilizar para explicar lo que es un programa es el símil con una receta de cocina. En las cuales podemos ver asignados en un verbo una serie de acciones que hemos de realizar. Por ejemplo, yo puedo poner en una receta que frías un trozo de carne en la sartén, pero para ti va a resultar tener que buscar la sartén, hacer lo mismo con el aceite, poner este último en la sartén, esperar que esté caliente y echar el trozo de carne en la misma. Como se pueden ver hemos convertido algo que en principio se define por un solo verbo en una serie de acciones.
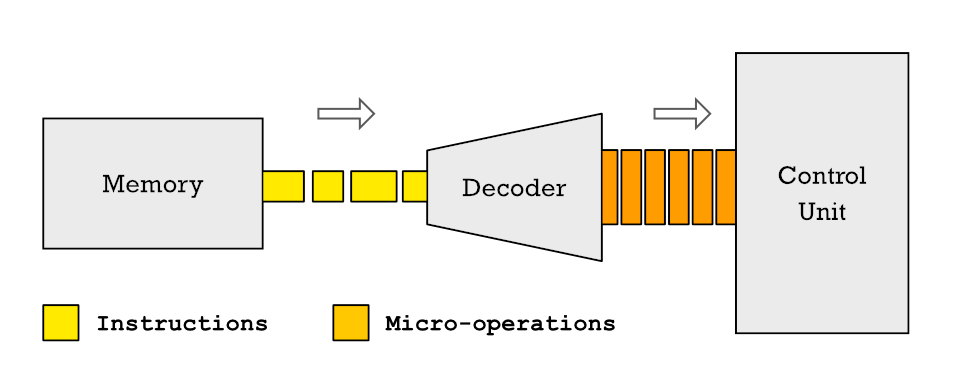
Pues bien, las instrucciones de una CPU se pueden descomponer en otras más pequeñas a las que llamamos microoperaciones. ¿Y por qué no microinstrucciones? Pues por el hecho de que una instrucción ya solo por la segmentación en varios ciclos para su ejecución tarda varios ciclos de reloj en resolverse. Una microoperación, en cambio, tarda un solo ciclo de reloj.
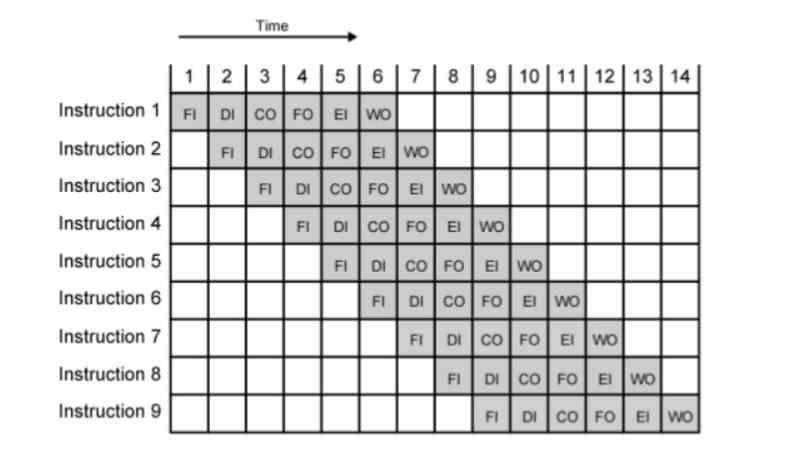
Una manera de conseguir la mayor cantidad de MHz o GHz es la segmentación o pipeline, donde cada instrucción es ejecutada en varias etapas que duran cada una un ciclo de reloj. Dado que la frecuencia es la inversa al tiempo, con tal de conseguir más frecuencia hemos de acortar el tiempo. El problema es que se llega al punto en que una instrucción no se puede descomponer más, la cantidad de etapas del pipeline se hace corta y con ello la velocidad de reloj que se puede alcanzar es baja.
En realidad, estas nacieron con la aparición de la ejecución fuera de orden de la arquitectura Intel P6 y sus CPU derivadas como los Pentium II y III. El motivo de ello es que la segmentación del P5 o Pentium solo les permitía llegar a poco más de los 200 MHz. Con las microoperaciones al alargar el número de etapas de cada instrucción aún más superaron la barrera del GHz con el Pentium 3 y pudieron tener velocidades de reloj 16 veces más altas con el Pentium 4. Desde entonces se han utilizado en todas las CPU con ejecución fuera de orden, independientemente de la marca y el set de registros e instrucciones.
Tus CPU no son ni x86, ni RISC-V, ni ARM
En las CPU actuales cuando las instrucciones llegan a la unidad de control de la CPU para ser descodificadas y asignadas a la unidad de control primero se descomponen en varias microoperaciones distintas. Esto significa que cada instrucción que ejecuta el procesador se compone por una serie de micro operaciones básicas y el conjunto de ellas en un flujo ordenado de las mismas se llama microcódigo.

La descomposición de las instrucciones en microoperaciones y la transformación de los programas que se encuentran almacenados en la RAM en microcódigo se encuentra a día de hoy en todos los procesadores. Por lo que cuando la CPU con ISA ARM de tu teléfono o el x86 de tu PC están ejecutando programas sus unidades de ejecución no están resolviendo instrucciones con esos sets de registros e instrucciones.
Este proceso no solo tiene las ventajas que os hemos explicado en la sección anterior, sino que nos podemos encontrar instrucciones que incluso dentro de una misma arquitectura y bajo el mismo set de registros e instrucciones se descompongan de manera distinta y ser los programas totalmente compatibles. La idea muchas veces es reducir la cantidad de ciclos de reloj necesarios, pero la mayoría de veces es para evitar la contención que se produce cuando hay varias peticiones a un mismo recurso dentro del procesador.
¿Qué es la caché de microoperaciones?
El otro elemento importante para conseguir el máximo rendimiento posible es la caché de microoperaciones, la cual es posterior a las micro operaciones y, por tanto, más cercana en el tiempo. Su origen lo podemos encontrar en la caché de trazado que Intel implemento en el Pentium 4. Se trata de una extensión de la caché de primer nivel para instrucciones que almacena la correlación entre las diferentes instrucciones y las microoperaciones en las que se han desmontado previamente por la unidad de control.

No obstante, la ISA x86 ha tenido siempre un problema respecto a las del tipo RISC, mientras que estos últimos tienen una longitud por instrucción fija en el código, en el caso de los x86 cada una de ellas puede medir entre 1 y 15 bytes. Hemos de tener en cuenta que cada instrucción se capta y descodifica en varías microoperaciones. Para realizar esto aún a día de hoy se necesitan una unidad de control sumamente compleja que puede llegar a consumir hasta un tercio de la potencia energética del mismo sin las optimizaciones necesarias.
La caché de microoperaciones es, por tanto, una evolución de la caché de trazado, pero que no forma parte de la caché de instrucciones, sino que es una entidad independiente del hardware. En una caché de microoperaciones el tamaño de cada una de ellas es fijo en cuanto al número de bytes, permitiendo por ejemplo a una CPU con ISA x86 operar lo más cercano posible a una del tipo RISC y reducir la complejidad de la unidad de control y con ello el consumo. La diferencia con la caché de trazado del Pentium 4 es que la actual caché de microoperaciones almacena todas las pertenecientes a una instrucción en una sola línea.
¿Cómo funciona?
Lo que hace la caché de microoperaciones es evitar el trabajo de descodificación de las instrucciones, por lo que cuando el descodificador acaba de efectuar dicha tarea lo que hace es almacenar el resultado de su trabajo en dicha caché. De esta manera cuando es necesario descodificar la siguiente instrucción lo que se hace es buscar si las microoperaciones que la forman se encuentran en dicha caché. La motivación de hacer esto no es otra que el hecho de que se tarda menos en consultar dicha caché que no descomponer una instrucción compleja.
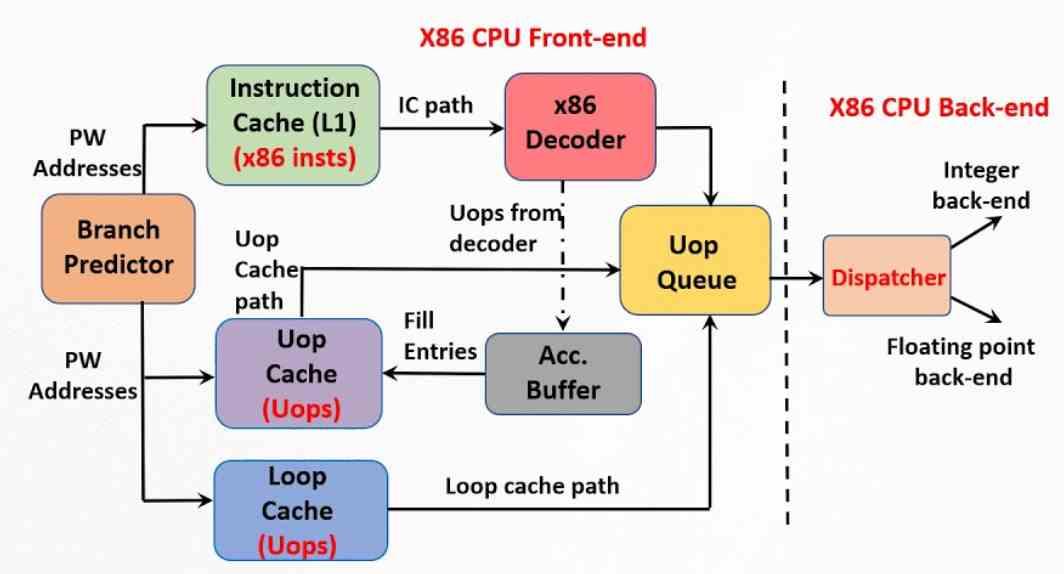
No obstante, esta funciona como una caché y su contenido se va desplazando con el tiempo a medida que van llegando nuevas instrucciones. Cuando hay una nueva instrucción en la caché de instrucciones de primer nivel, se busca en la caché de microoperaciones si ya se encuentra descodificada. Si no es así, entonces se procede de manera habitual.
Las instrucciones más comunes una vez descompuestas suelen formar parte de la caché de microoperaciones. Lo que provoca que se descarten menos, en cambio, sí que lo serán más a menudo aquellos cuyo uso es esporádico, con tal de dejar espacio a nuevas instrucciones. Lo ideal sería que el tamaño de la caché de microoperaciones fuese de un tamaño suficiente para almacenarlas todas, pero se está ha de tener un tamaño lo suficientemente pequeño como para que la búsqueda en la misma no acabe afectando al rendimiento de la CPU.