
Las unidades SIMD o también conocidas como unidades vectoriales empezaron a utilizarse en CPU a partir de finales de los 90 y son también la base para la enorme potencia de cálculo de las GPU al permitir trabajar con grandes cantidades de datos en paralelo. No obstante pese a la enorme potencia de cálculo que otorgan tienen una serie de limitaciones de cara al rendimiento. ¿Cuáles son las limitaciones de las unidades SIMD?
Las siglas SIMD significan Single Instruction Multiple Data, son un tipo de unidad que realiza la misma instrucción, sea del tipo que sea, sobre diferentes datos al mismo tiempo. Estos suelen estar empaquetados en una sucesión de valores de datos presentados como si fuese un vector, de ahí que sean conocidas también como unidades vectoriales.
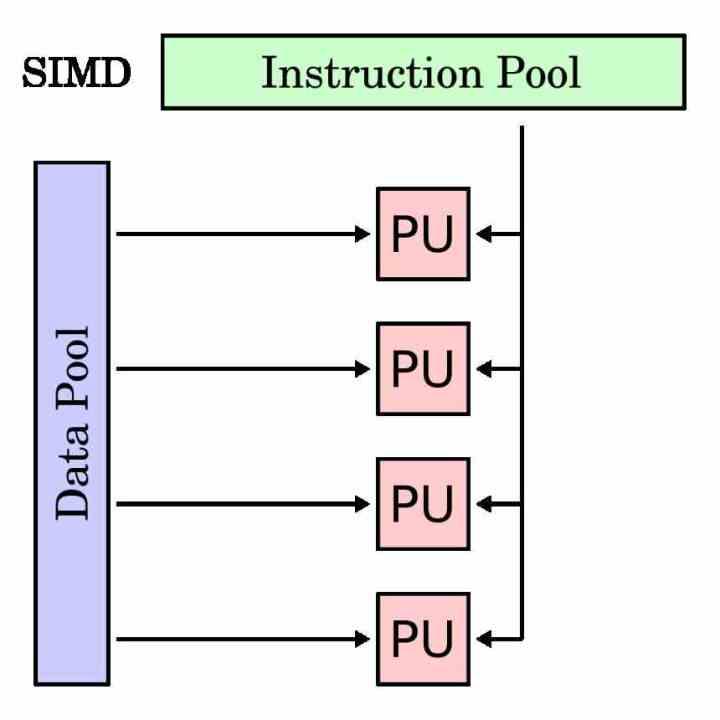
Debido a que todo lo relacionado con imagen y sonido tiene la característica de trabajar con grandes cantidades de datos, pero con instrucciones altamente recursivas. Se empezaron a implementar las unidades SIMD en las CPU junto a extensiones de los sets de registros e instrucciones. Lo cual ocurrió a finales de los 90 y desde entonces ha habido una evolución clara en este tipo de unidades en las CPU.
Las unidades SIMD también se utilizan en las GPU. Por ejemplo tenemos el caso de los «Stream Processors» de AMD y los mal llamados «CUDA Cores» de NVIDIA. Los cuales no son más que ALU colocadas en unidades SIMD. Por los que todos ellos reciben la misma instrucción al unísono y trabajan con ella, pese a estar manipulando datos distintos.
Las limitaciones o cuellos de botella de las unidades SIMD
Debido a que las unidades SIMD pueden operar varios datos al mismo tiempo multiplican, por tanto, la capacidad de cálculo de un procesador. No obstante tienen una serie de limitaciones asociadas que hace que su rendimiento se aleje del ideal teórico que deberían tener, en concreto son tres de ellas, la cuales os vamos a describir a continuación.
Limitaciones en el tamaño de las instrucciones en unidades SIMD
El primero de ellos es de cara al diseño de chips, el tamaño de los datos con los que trabajan las unidades SIMD está fijo, de tal manera que es necesario aumentar el set de instrucciones para que puedan trabajar con datos de mayor o menor precisión. Esto supone una sobrecomplicación a la hora de diseñar nuevas CPU y GPU y se ha convertido en una pesadilla con los diferentes tipos de formato de datos que han aparecido en los últimos años. En especial con la inteligencia artificial que ha introducido nuevos formatos de datos de baja precisión.
El problema se agrava en las ISA con instrucciones de tamaño fijo y que, por tanto, utilizan la misma cantidad de bits como es el caso de ARM. Si por ejemplo en el futuro es necesario que el tamaño de la instrucción SIMD sea más grande entonces quedarán menos bits para el opcode y, por tanto, para la cantidad de instrucciones. Esto está forzando a ciertos diseños RISC a tener que tirar de aceleradores o co-procesadores para que trabajen con instrucciones SIMD de gran tamaño.
En cambio, no da como resultado una desventaja para procesadores x86, donde el tamaño de las instrucciones no es fijo, pero como contrapartida sobrecomplica el tamaño de la unidad de control.
Saltos y bucles afectan al rendimiento
Otro de los cuellos de botella o limitaciones de las unidades SIMD es de cara a las instrucciones de bucle o de salto, ya que puede que un valor concreto entre la multitud de operandos de una unidad SIMD puede hacer que la instrucción continúe de manera distinta. No olvidemos que la velocidad de todo procesador es siempre la de su componente más lento y puede que una ALU entre un bucle o un salto mucho más largo. Es por ello que las GPU que basan toda su ejecución en unidades SIMD tienen unidades de predicción de saltos funcionando aparte y su rendimiento baja en picado cuando hay una de estas instrucciones.
Si debido a un bucle o un salto una de las operaciones de la unidad SIMD no ha sido terminada, entonces no es posible hacer el salto a la siguiente instrucción para este tipo de unidades. Es por ello que se utiliza una técnica llamada Loop Unrolling, la cual consiste en convertir un código en bucle o salto en una sucesión de instrucciones en serie que obtienen el mismo resultado. Para hacerlo se hace uso del compilador del código fuente a código máquina o dependiendo de la arquitectura se ha de realizar a mano, pero tiene como contrapartida el aumento del tamaño del programa.
Desaprovechamiento de las ALUs en instrucciones SIMD

No siempre una instrucción para una unidad SIMD hace uso de todas las ALU que esta tiene, haciendo que muchas veces una parte de la unidad esté sin hacer nada al no tener un operando en el que trabajar. Lo ideal sería que las ALU que no se utilizan se asignen a la siguiente instrucción, pero esto no es posible y es por ello que es sumamente importante aprovechar al máximo los recursos en este aspecto.
Donde esto se ve mucho es en las GPUs, donde muchas veces las olas de datos e instrucciones que llegan a las unidades shader no ocupan todos los huecos y se traduce en un recorte importante del rendimiento a la hora de utilizar este tipo de unidades, pero no es el caso. Se ha de tener en cuenta que las unidades SIMD suelen tener configuraciones donde las ALUs son una potencia de 2, por lo que si la cantidad de datos a trabajar no un multiple de 2 se acaba produciendo un desaprovechamiento de la capacidad de cálculo de las unidades SIMD.