
Una de las afirmaciones de NVIDIA respecto a sus RTX 3000 es que ellos han duplicado la potencia en coma flotante de sus GPUs, lo cual no se traduce en que la potencia y por lo tanto el rendimiento de toda la GPU haya aumentado respecto a las RTX 2000 en igualdad de condiciones sino solamente una parte de la GPU, pero lo mejor es daros una explicación del porqué sin entrar en detalles excesivamente técnicos y de tal manera que hasta el usuario más novel lo pueda entender.
Según NVIDIA, sus nuevas RTX 3000 Series son el doble de potentes (en cuanto al rendimiento en coma flotante) respecto a las RTX 3000, pero la realidad es que en los juegos esto no se traduce en que el rendimiento se haya duplicado, y para entender el motivo por lo que esto ocurre hemos de entender una serie de premisas para llegar a la conclusión que nos explique el motivo de ello.
¿A qué se refiere NVIDIA con rendimiento en coma flotante? Se trata de un tipo de dato numérico, cuya velocidad de cálculo es medida por una magnitud llamada FLOPS, operaciones en coma flotante por segundo, pero que es cuanto menos engañosa a la hora de comparar dispositivos por los siguientes motivos:
- No todas las instrucciones se resuelven en la misma cantidad de ciclos de reloj.
- Todo procesador independientemente de su naturaleza realiza una o varias operaciones en todos los ciclos.
- Cada instrucción, equivalente o equivalentes no se resuelven en todas las arquitecturas en la misma cantidad de ciclos.
Es decir, podemos tener dos sistemas con 10 TFLOPS de potencia y uno de ellos ser más rápido que el otro, ya que en el que es más potente se han incorporado cambios en la arquitectura que hacen que ese modelo rinda mucho mejor que el otro, aunque tengan la misma tasa en coma flotante e incluso inferior.
Las RTX 3000 como evolución de las RTX 2000
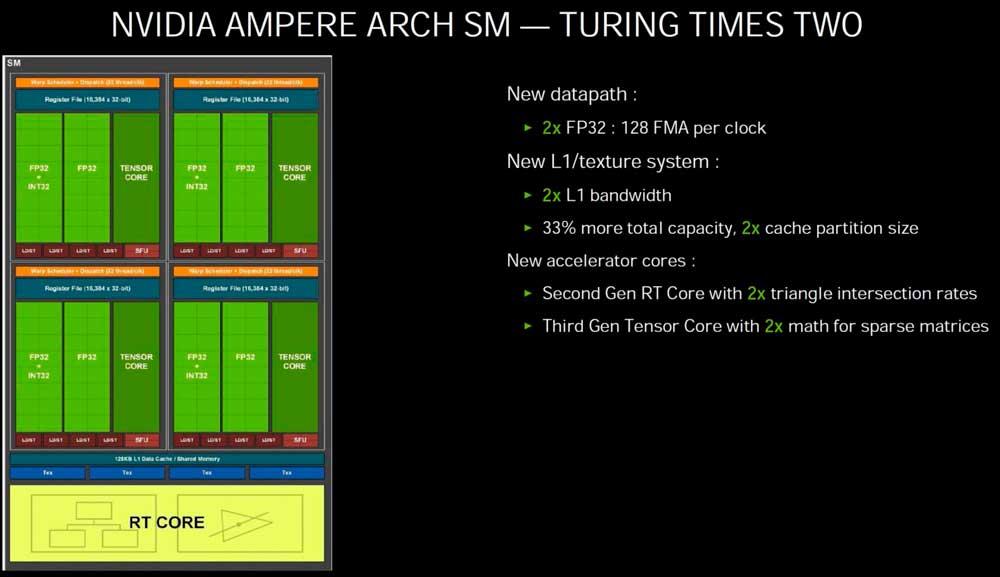
Para ir al punto que nos interesa tratar hemos de hacer un doble zoom sobre la arquitectura, empezando por las unidades SM de cada una de ambas arquitecturas:
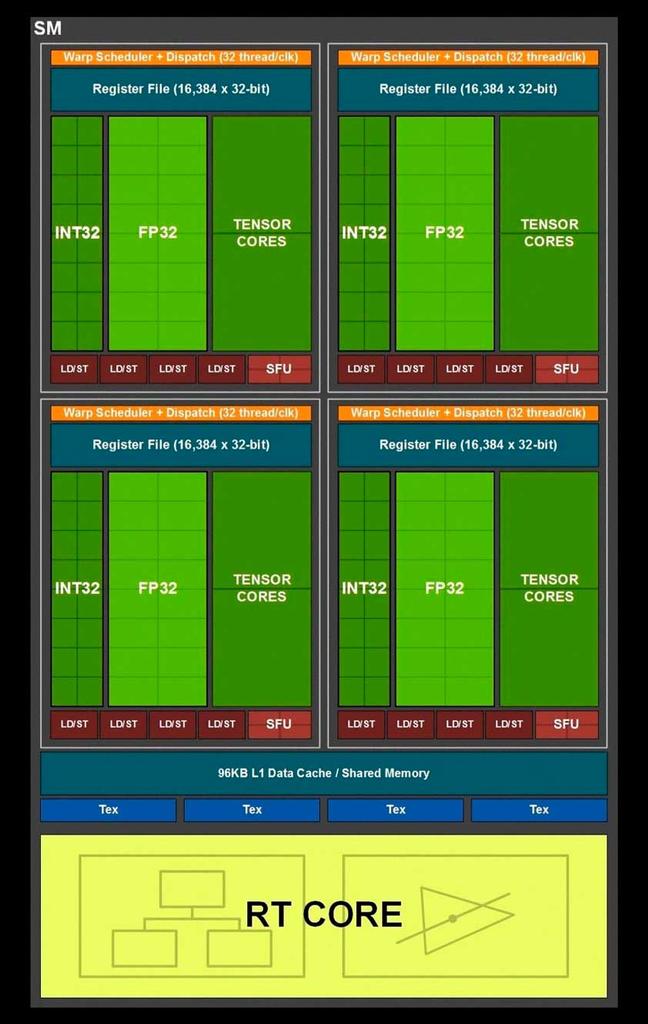
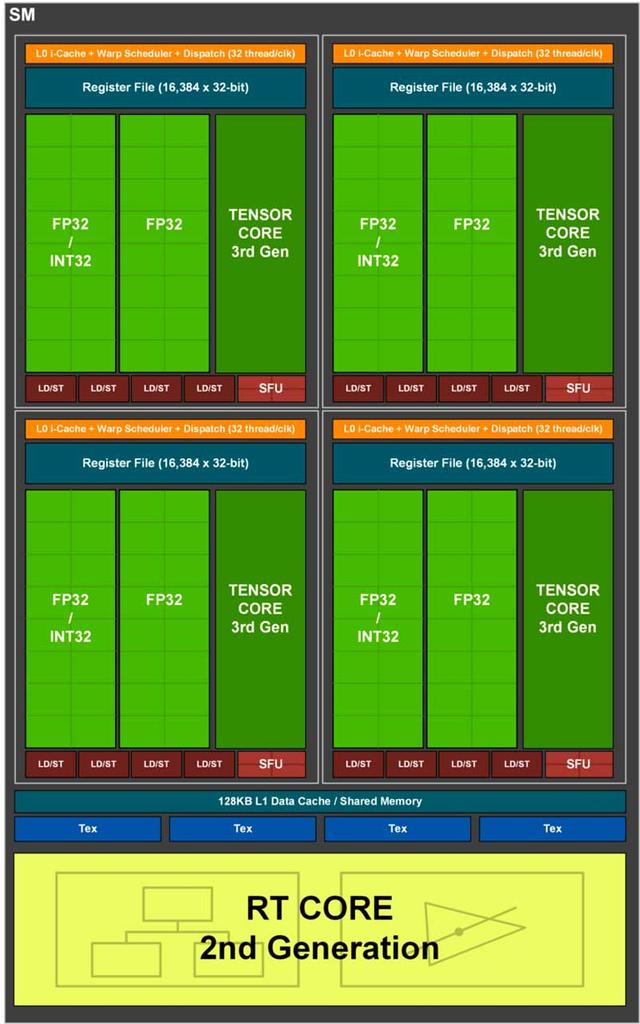
La parte que nos interesa dentro del SM es el «subcore» de cada arquitectura, ya que nos permitirá entender mucho mejor los cambios en cuanto a rendimiento en coma flotante que ha habido en las RTX 2000 respecto a las RTX 3000.
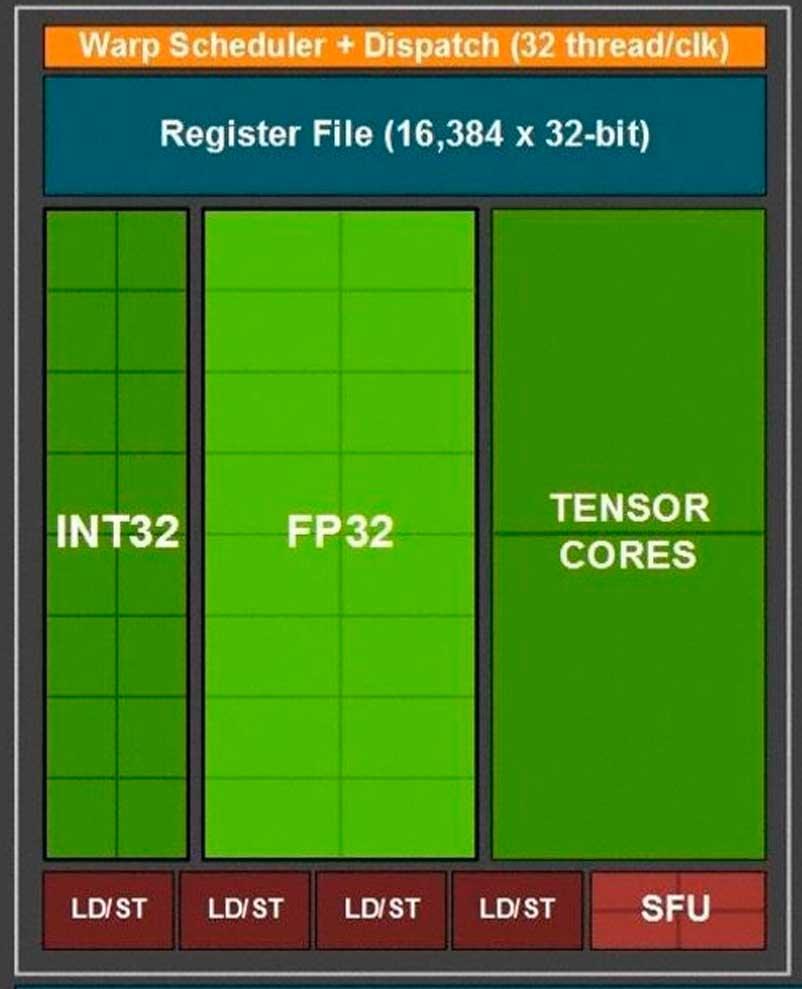
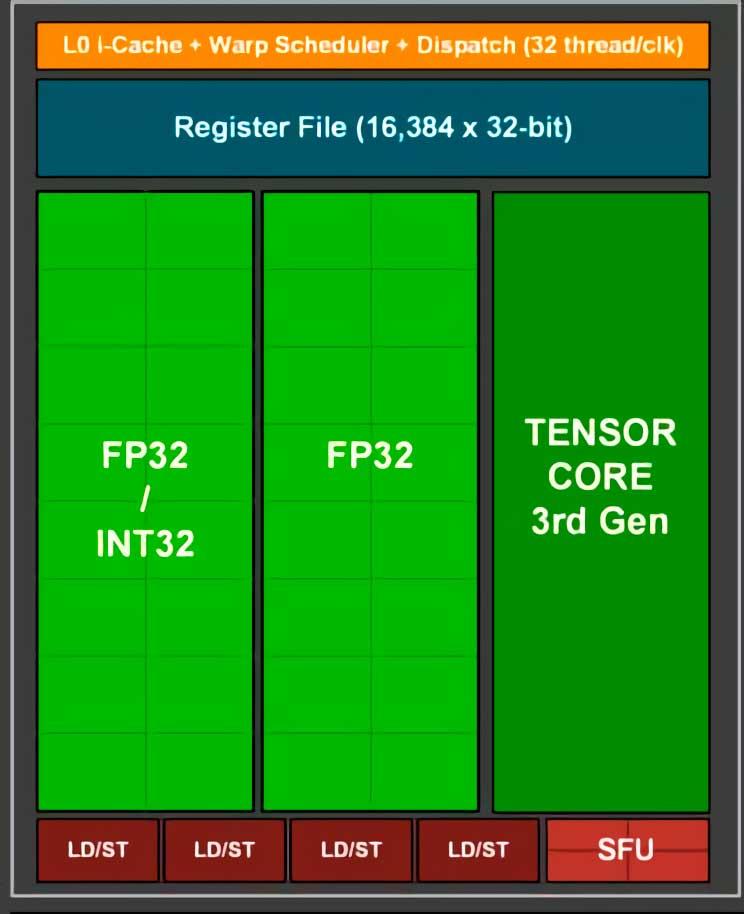
A los ingenieros de NVIDIA, a la hora de diseñar la arquitectura Ampere de las RTX 3000, se les encendió la bombilla y decidieron hacer un cambio cuanto menos interesante en los “subcores” para aumentar el rendimiento en coma flotante respecto a su antecesor modificando la menor cantidad de elementos posible.
Dado que los “subcores” tanto de Turing como de Ampere utilizan el mismo planificador/»warp scheduler» y tienen la misma cantidad de registros, lo que han hecho ha sido aprovechar una pequeña «trampa» para poder duplicar la potencia en coma flotante de cada uno de los “subcores”. ¿Cuál es esa trampa? Bien, pues lo que ha hecho NVIDIA es añadir otras 16 ALUs en coma flotante de 32 bits.
Tanto en Turing como en Ampere podemos tener activas 16 ALUs Int32 y 16 ALUs FP32 dado que el planificador envía 32 hilos a los registros que posteriormente las ALUs correspondientes ejecutarán.
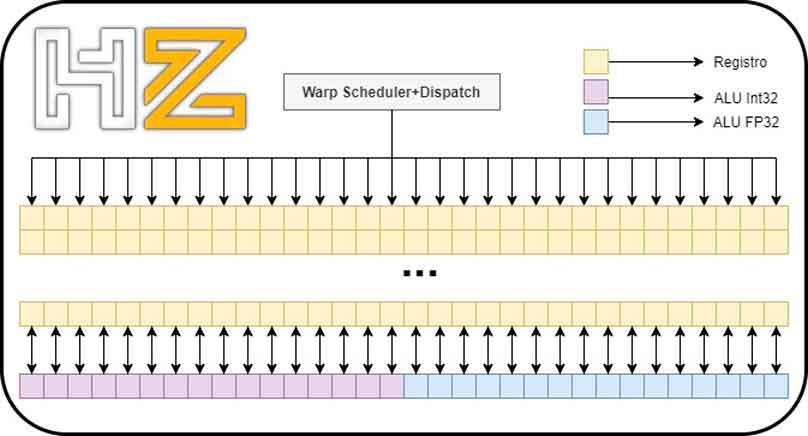
A esto NVIDIA lo llama ejecución concurrente, y se basa en hacer trabajar de manera conjunta las ALUs de enteros y coma flotante.
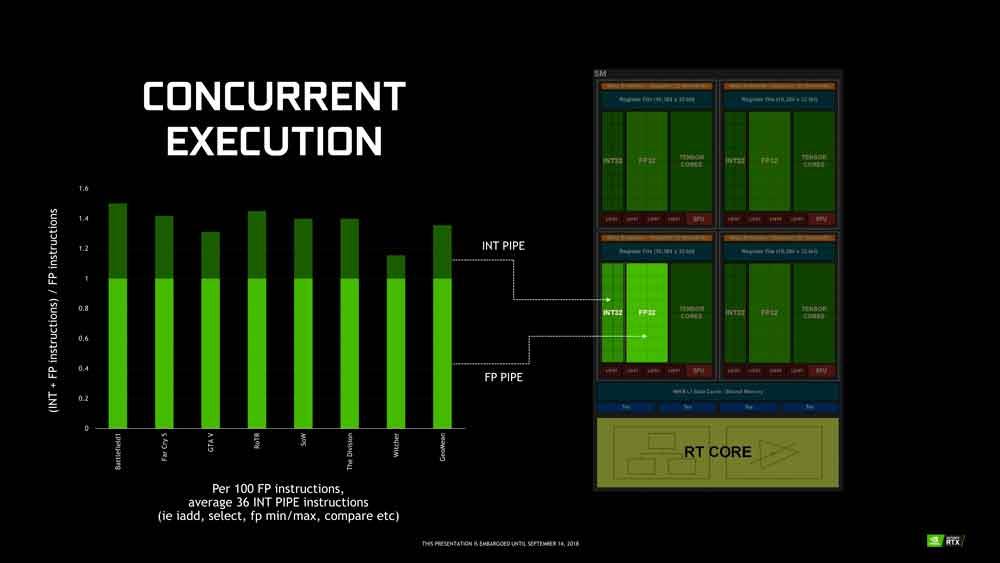
El problema en las RTX 2000 viene cuando tenemos una ola de 32 hilos en coma flotante: las ALUs de enteros no pueden ejecutar ese código por lo que si tenemos una ola de ese tipo esta va a necesitar resolverse en dos pasos en vez de en uno solo.
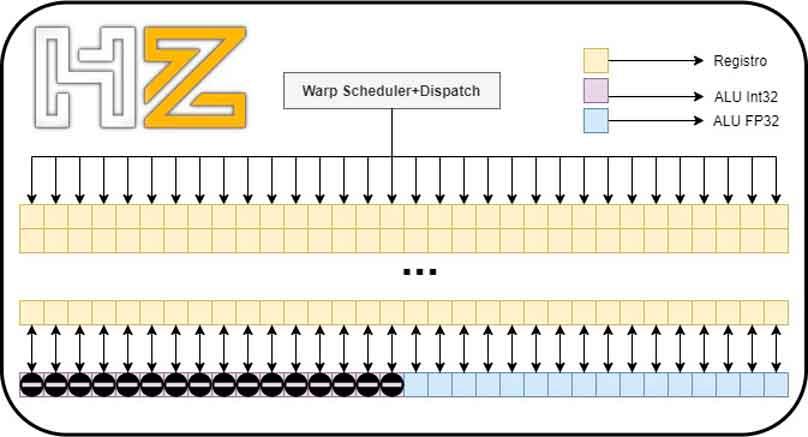
Lo que ha hecho NVIDIA en la arquitectura Ampere al duplicar las ALUs en FP32 es que se pueda resolver una ola 32 hilos en coma flotante en la mitad de tiempo que Turing, duplicando con ello la velocidad (en el sentido de que necesita solo un ciclo para resolverlo en lugar de dos).
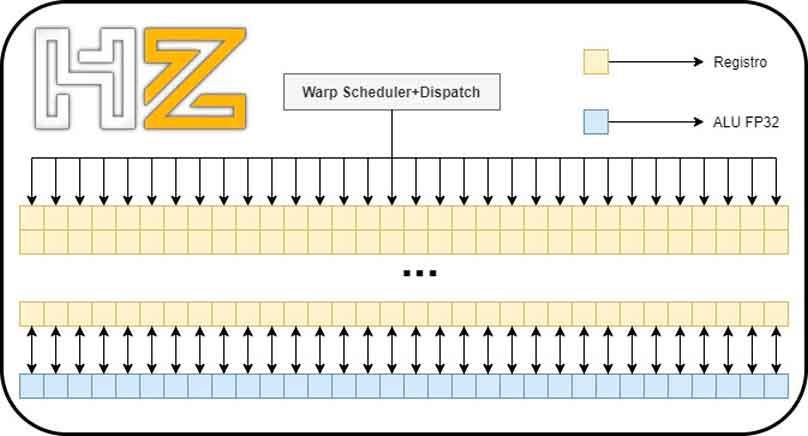
Así pues, entre el modo concurrente entre enteros y coma flotante no hay diferencia entre las RTX 3000 y las RTX 2000, y la ventaja de cara a coma flotante en las tarjetas gráficas de arquitectura Ampere solo se dará cuando estos estén ejecutando una ola de hasta 32 hilos en coma flotante.
Las especificaciones técnicas vienen de un contexto que no coincide con la realidad

Una vez que hemos visto en qué situaciones las RTX 3000 son el doble de rápidas que las RTX 2000 hemos de añadir otro elemento a la ecuación y es que cuando hablamos de la tasa de FLOPS estamos hablando de una tasa teórica que no se da en los escenarios reales, y el problema de los TFLOPS en las GPUs es que los números que dan los fabricantes son tasas basadas en:
- La GPU ejecutando el tipo de instrucción más rápida, es decir, la que tarda menos ciclos. Lo habitual es utilizar la FMADD/FMA porque es una instrucción aritmética compuesta por una suma y una multiplicación que se resuelve en un mismo ciclo.
- Siempre se ejecuta la misma instrucción de manera reiterativa, no hay saltos de línea en el código ni otro tipo de instrucción.
- Los datos se encuentran en los registros, no hay búsqueda de datos en las cachés ni en la memoria VRAM, así que dicha instrucción se ejecuta con la latencia más baja posible.
Es como si compráramos un coche deportivo por su rendimiento en una recta donde pudiese acelerar sin obstáculos hasta el límite. La realidad es que las carreteras son mucho más complejas que simples rectas y lo mismo ocurre con el código gráfico de los juegos; esto significa que esas tasas tan impresionantes que dan todos los fabricantes no se dan nunca y no tienen correlación con los escenarios reales.
¿Entonces las NVIDIA RTX 3000 no son el doble de potentes que las RTX 2000?

No, no lo son y es algo que a estas alturas del artículo os debería haber quedado claro. Hemos de entender que los gráficos en 3D a tiempo real siguen un pipeline dividido en varias etapas, en una buena parte de ellas las RTX 3000 no serán más rápidas que una RTX 2000 equivalentes, pero en otras donde la potencia en coma flotante es importante será cuando las gráficas Ampere tomarán la ventaja y acelerarán la ejecución en esa parte del pipeline gráfico, si bien el incremento de rendimiento nunca será el doble.
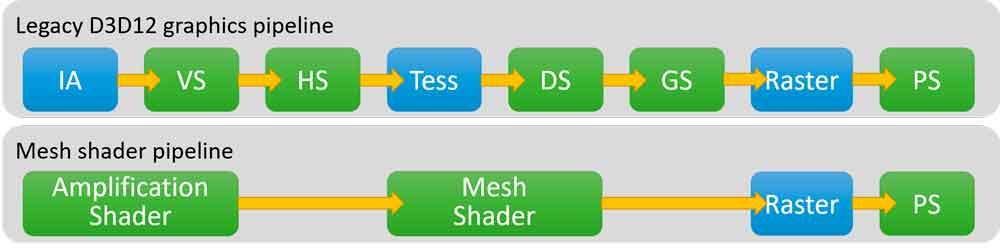
El pipeline se divide en partes que son ejecutadas por los SM (Compute Units en la jerga de AMD), las etapas shader y están en verde en el diagrama, mientras que las partes en azul son de función fija. Estas son ejecutadas por unidades cableadas y no programadas y en este caso no ha habido mejoras desde las RTX 2000 a las RTX 3000 (excepto en el RT Core, pero no forma parte del pipeline de rasterización).
Para entender mejor la situación lo mejor es utilizar un símil: imaginad que tenemos dos coches distintos, el coche A y el coche B que en recta pueden ir a la misma velocidad, pero el coche B tiene la particularidad de tomar las curvas el doble de rápido que el coche A. Supongamos que los hemos probado en un circuito dividido en 7 segmentos: 4 rectas y 3 curvas.
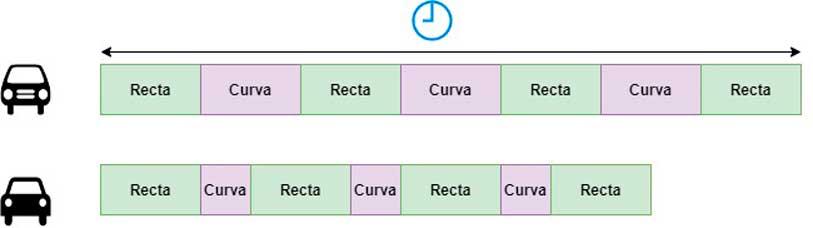
Como se puede ver el coche B tardará menos tiempo en recorrer cada vuelta del circuito que su rival, y sin ser el doble de rápido sí que toma una ventaja considerable al ser más rápido en curva. Lo mismo ocurre entre las RTX 3000 y las RTX 2000, su rendimiento no se duplicará siempre, pero sí en situaciones concretas.
¿Dónde tienen ventajas las RTX 3000 sobre las RTX 2000?

Especialmente en todo aquello que no dependa de las unidades de función fija, como es el pipeline de computación utilizado hoy en día en efectos de post-procesado y en la etapa de Ray Tracing del renderizado híbrido. Este es el motivo por el cual en aplicaciones como Quake 2 RTX el rendimiento de las RTX 3000 duplica a las RTX 2000, por el hecho que es un juego que explota enormemente la ejecución en coma flotante y no utiliza casi para nada las unidades de función fija de la rasterización.
Con todo esto podéis entender los motivos por los cuales la RTX 3000 pese a duplicar los FLOPS no duplica el rendimiento respecto a su antecesora.