
El primer procesador con ejecución fuera de orden fue el IBM POWER 1, el cual sería la base para los procesadores RISC de este mismo nombre y de los PowerPC. Intel adopto esta tecnología para los x86 en su Pentium Pro. Desde entonces todas las CPUs de PC hacen uso de la tecnología out-of-order como una de las bases para sacar el máximo rendimiento posible.
La mayor preocupación en el diseño de procesadores no es muchas veces sacar la mayor potencia, sino el mayor rendimiento a la hora de ejecutar las instrucciones. Entendemos como rendimiento al hecho de acercarnos al ideal teórico de funcionamiento de un procesador. No sirve de nada tener la CPU más potente si por limitaciones lo único que tiene es potencial de ser y no es.
Dos formas de tratar el paralelismo
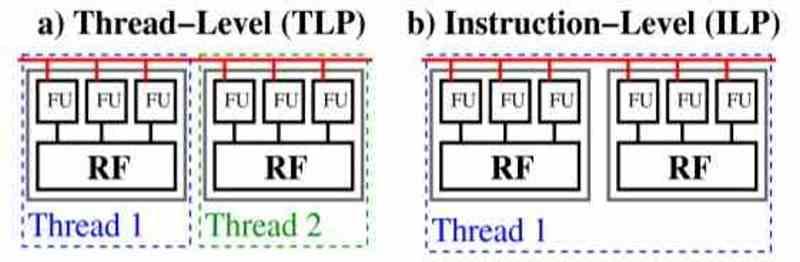
Existen dos formas de tratar el paralelismo en el código de un programa, estos son el paralelismo a nivel de hilo o ILP y el paralelismo a través de instrucción o TLP.
En el TLP el código está dividido en varios subprogramas, los cuales son independientes de los otros y funcionan de manera asíncrona, eso significa que cada uno de ellos no depende del código del resto. Cuando estamos en un procesador TLP la clave está en que si ocurre una parada en la ejecución por algún motivo entonces el procesador TLP coge otro de los hilos de ejecución y coloca el inactivo a la espera.
Los procesadores ILP son distintos, su paralelismo es nivel de instrucciones y por tanto en un mismo hilo de ejecución, por lo que no pueden hacer la trampa de poner el hilo principal a la espera. A día de hoy en las CPUs se combinan los dos tipos de ejecución, pero el ILP sigue siendo exclusivo de las CPUs y es donde consiguen una gran ventaja en lo que es el código en serial por encima del código totalmente paralelizable.
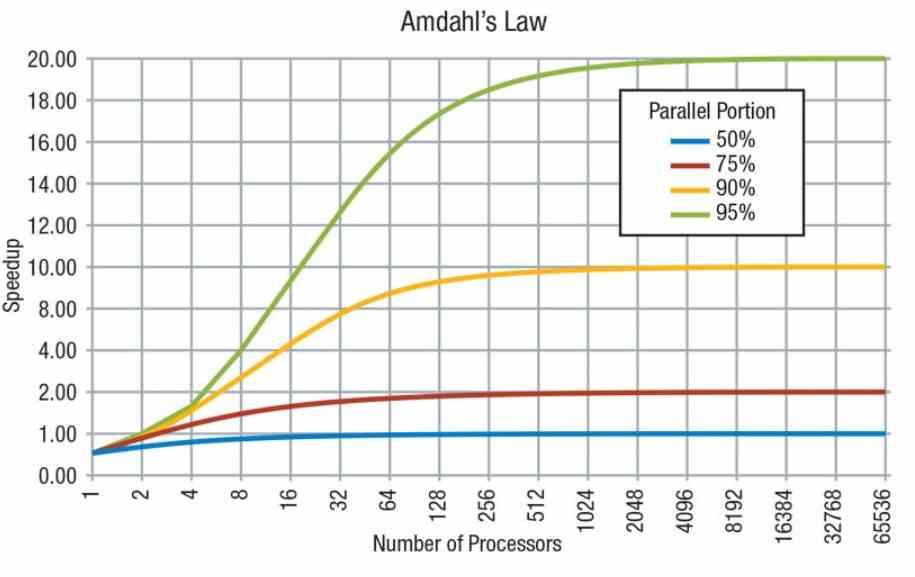
No podemos olvidar que según la Ley de Amdahl un código se compone de partes en serie, que solo pueden ser ejecutadas por un procesador, y en paralelo, las cuales pueden ser ejecutadas en varios procesadores. No obstante no todo se puede paralelizar y hay partes seriales del código que requieren funcionar en serie.
En los últimos 15 años se ha desarrollado el concepto en el que los algoritmos en paralelo se ejecutan en las GPUs, cuyos núcleos son del tipo TLP, mientras que el código en serie se ejecuta en las CPU que son del tipo ILP.
Ejecución in-order de las instrucciones
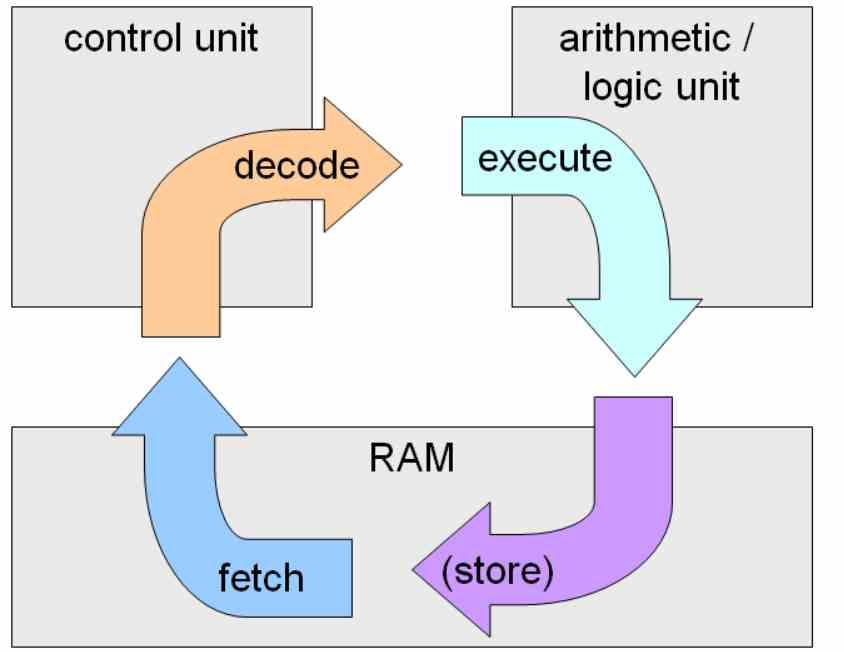
La ejecución in-order es la clásica ejecución de instrucciones, su nombre se debe a que las instrucciones se ejecutan en el orden que aparecen en el código y la siguiente instrucción no puede continuar hasta que no se ha resuelto la anterior.
La mayor dificultad de la ejecución in-order está en las instrucciones condicionales y de salto, ya que esta se va a ejecutar cuando se dé la condición, enlenteciendo enormemente la velocidad de ejecución del código. Esto es un problema enorme cuando la cantidad de etapas de un procesador es sumamente alta, que es lo que ocurre cuando una CPU funciona a altas velocidades de reloj.
La trampa para conseguir altas velocidades de reloj es segmentar al máximo con una gran cantidad de subetapas del ciclo de instrucción la resolución de instrucciones. Cuando se da un salto o una condición errónea entonces se pierde una considerable cantidad de ciclos de instrucción.
Out-of-order, acelerando el ILP

Out-of-order o ejecución fuera de orden es la forma en la que las CPUs más avanzadas ejecutan el código y esta pensado para evitar las paradas en la ejecución. Como su nombre indica consiste en ejecutar las instrucciones de un procesador en un orden diferente en las que vienen indicadas en el código.
El motivo por el cual se hace esto es porque cada tipo de instrucción tiene un tipo de unidad de ejecución asignada. Según el tipo de instrucción la CPU utiliza un tipo de unidad de ejecución u otra, pero estas son limitadas. Esto puede provocar una parada en la ejecución, por lo que lo que se hace es adelantar la siguiente instrucción en su ejecución, apuntando en una memoria o registro interno cual es el orden real de las instrucciones, una vez han sido ejecutadas estas son enviadas de vuelta en el orden original que estaban en el código.
El uso del out-of-order permite ampliar la cantidad media de instrucciones resueltas por ciclo y acercarlo al ideal de rendimiento. Por ejemplo el primer Intel Pentium disponía de ejecución in-order y era una CPU capaz de trabajar con dos instrucciones en contra del 486 que solo podía trabajar con una, pero pese a ello su rendimiento por culpa de las paradas era solo de un 40% adicional.
Etapas adicionales para el out-of-order
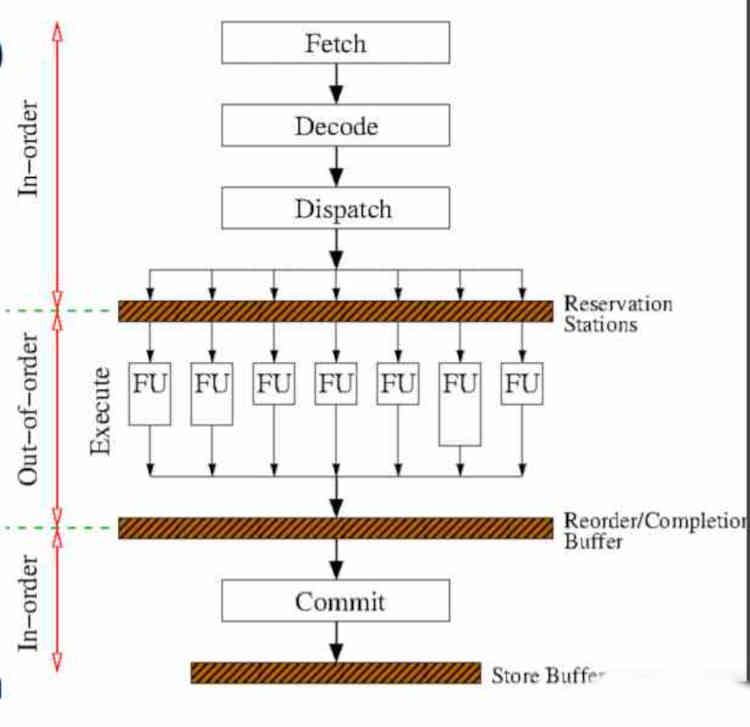
La implementación de la ejecución out-of-order añade etapas adicionales al ciclo de instrucción, sobre el cual ya os hablamos en el artículo titulado Así es como tu CPU ejecuta las instrucciones que le da el software, el cual podéis encontrar en HardZone.
En realidad solo la parte central de la ejecución de la instrucción varía respecto a la ejecución in-order, dichos cambios ocurren antes de la etapa de ejecución, por lo que las dos primeras que son la de captación (fetch) y descodificación (decode) no se ven afectadas, pero si que se añaden dos nuevas etapas, las cuales ocurren antes y después de la ejecución de instrucciones.
La primera etapa son las estaciones de reserva, en ella el hardware espera que las unidades de ejecución estén libres. Su implementación es compleja, ya que se basa en un mecanismo que no solo vigila cuando una unidad de ejecución esta libre, sino que cuenta la duración media en ciclos de reloj de cada instrucción que se está ejecutando para saber cómo tiene que reordenar las instrucciones.
La segunda etapa es el búfer de reordenamiento, el cual se encarga de ordenar las instrucciones en orden de salida. Hay que tener en cuenta que con tal de acelerar la salida de las instrucciones en la ejecución out-of-order se ejecuta todas las ramas de instrucción especulativa en el código. La instrucción especulativa es la que se da cuando hay un salto condicional independientemente de si se cumple la condición o no. Por lo que es en esta etapa donde se descartan las ramas de ejecución no confirmadas.