
Las instrucciones AVX-512 son uno de los elementos únicos de las arquitecturas de CPU x86 de Intel. Pero, ¿en qué consisten estas instrucciones y a que se debe su implementación en las CPU de Intel? Seguid leyendo para poder entender el motivo de la existencia de estas instrucciones, que variantes tiene y por qué no es utilizada por AMD en sus CPU.
Las instrucciones AVX fueron implementadas por primera vez en las CPU de Intel, reemplazando las viejas instrucciones SSE. Desde entonces se han convertido en las instrucciones SIMD estándar para las CPU x86 en sus dos variantes, la de 128 bits y la de 256 bits, siendo adoptadas también por AMD. En cambio si hablamos de las instrucciones AVX-512 la situación es distinta y solo son utilizadas en las CPU de Intel.
¿Qué es una unidad SIMD?
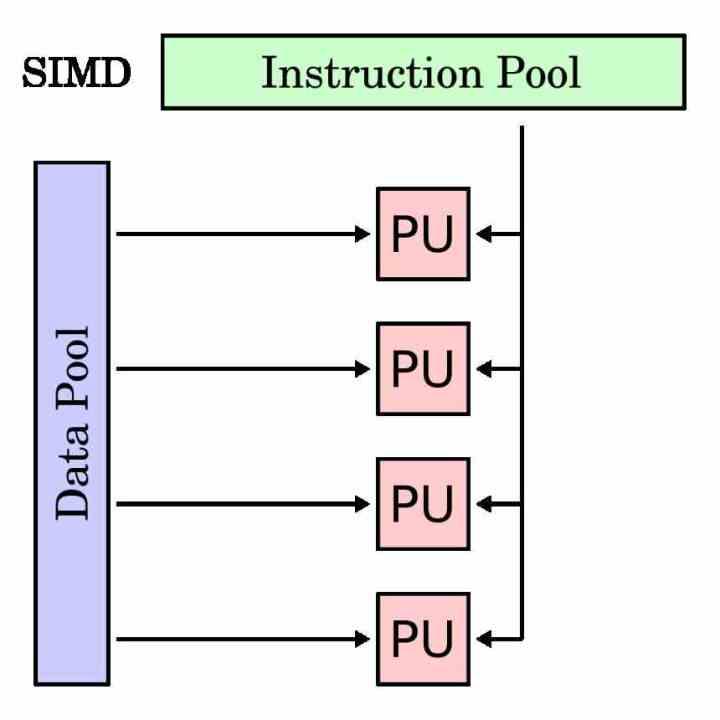
Una unidad SIMD es un tipo de unidad de ejecución que está pensada para ejecutar la misma instrucción a varios datos al mismo tiempo. Por lo que su registro acumulador es más largo que una instrucción tradicional, ya que tiene que agrupar los diferentes datos que ha de operar con esa misma instrucción.
Las unidades SIMD se han utilizado tradicionalmente para acelerar los llamados procesos multimedia en el que es necesario manipular varios datos bajo las mismas instrucciones. Las unidades SIMD permiten paralelizar la ejecución del programa en esas partes y acelerar el tiempo de ejecución.
En todo procesador con tal de separar las unidades de ejecución SIMD de las tradicionales, tienen su propio subconjunto de instrucciones que normalmente es un espejo de las instrucciones escalares o con un solo operando. Aunque hay casos que no son posibles de hacer con una unidad escalar y son exclusivos de las unidades SIMD.
La historia del AVX-512

Las instrucciones AVX, Advanced Vector eXtensions, llevan años dentro de los procesadores de Intel, pero el origen de las instrucciones AVX-512 es diferente al resto. ¿El motivo? Su origen es el proyecto Intel Larrabee, un intento de Intel de finales de los 2000 para crear una GPU que al final se convirtió en los aceleradores Xeon Phi. Una serie de procesadores pensados para la computación de alto rendimiento que Intel lanzo hace unos años.
La arquitectura Xeon Phi/Larrabee incluyeron una versión especial de las instrucciones AVX con un tamaño en su registro acumulador de 512 bits, lo que significa que pueden operar con hasta 16 datos de 32 bits. El motivo para esta cantidad tiene que ver con el hecho que el ratio operaciones por téxel habitual en una GPU suele ser de 16:1. No olvidemos que las instrucciones AVX-512 tienen su origen en el fallido proyecto Larrabee y fue llevado de ahí a los Xeon Phi.
A día de hoy, los Xeon Phi ya no existen, el motivo de ello es que se puede hacer lo mismo a través de una GPU tradicional por computación. Esto hizo que Intel las trasladará a su línea principal de CPUs dichas instrucciones.
El galimatías que son las instrucciones AVX-512
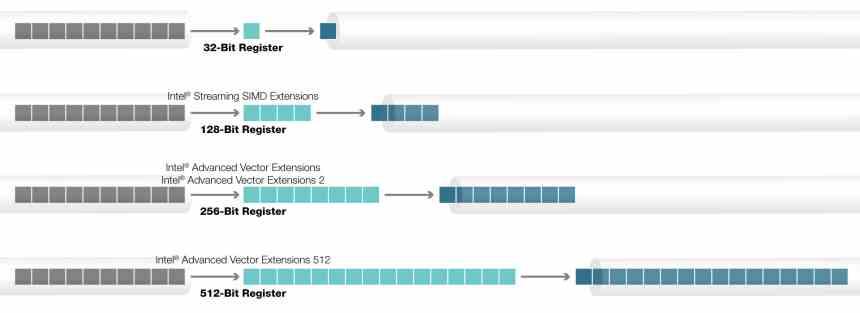
Las instrucciones AVX-512 no son un bloque homogéneo que este 100% implementado, sino que tiene diversas extensiones que según el tipo de procesador han sido añadidas o no. Todas las CPU tienen las llamadas AVX512F, pero hay instrucciones adicionales que no forman parte del set de instrucciones original y que Intel ha ido añadiendo con el tiempo.
Las extensiones AVX512 son las siguientes:
- AVX-512-CD: Conflict Detection, permite los bucles peudan ser vectorizados y por tanto vectorizado. Fueron añadidos por primera vez en Skylake-X o Skylake-SP.
- AVX-512-ER: Instrucciones reciprocas y exponenciales, las cuales están diseñadas para la implementación de operaciones trascendentales. Fueron añadidos en una gama de los Xeon Phi llamada Knights Landing.
- AVX-512-PF: Otra inclusión en Knights Landing, esta vez para aumentar las capacidades de precaptación o prefetech de las instrucciones.
- AVX-512-BW: Instrucciones a nivel de Byte (8 bits) y de palabra (16 bits). Esta extensión le permite trabajar con datos de 8 y 16 bits.
- AVX-512-DQ: Añade nuevas instrucciones con datos de 32 bits y las de 64 bits.
- AVX-512-VL: Le permite a las instrucciones AVX operar en los registros acumuladores XMM (128 bits) e YMM (256 bits)
- AVX-512-IFMA: Fused Multiply Add, lo que coloquialmente es una instrucción A*(B+C), con precisión de 52 bits en enteros.
- AVX-512-VBMI: Instrucciones de manipulación de vectores a nivel de byte, es una extensión al AVX-512-BW.
- AVX-512-VNNI: Las Vector Neural Network Instructions son una serie de instrucciones añadidas para acelerar los algoritmos de Deep Learning, utilizados en aplicaciones relacionadas con la inteligencia artificial.
¿Por qué AMD no la ha implementado aún en sus CPU?

El motivo de ello es muy simple, AMD apuesta por el uso combinado de sus CPU y GPU a la hora de acelerar cierto tipo de aplicaciones. No olvidemos el origen del AVX-512 en una fallida GPU de Intel y AMD gracias a sus GPU Radeon no les hace falta el uso de instrucciones AVX-512.
Es por ello que las instrucciones AVX-512 son exclusivas de los procesadores de Intel, no por una exclusividad total, sino porque AMD no tiene interés en utilizar este tipo de instrucciones en sus CPU, ya que su intención es la de vender sus GPU, especialmente las recién lanzadas en el mercado de computación de alto rendimiento AMD Instinct con arquitectura CDNA.
¿Tienen futuro las instrucciones AVX-512?

Pues no lo sabemos, depende del éxito que tengan los Intel Xe, en especial el Xe-HPC, los cuales le van a dar a Intel una arquitectura de GPU al nivel de la de AMD y NVIDIA. Esto significa un conflicto entre el Intel Xe y las instrucciones AVX-512 para solventar los mismos problemas.
El problema con el AVX-512 es que activar la parte de la CPU que hace uso del mismo acaba afectando a la velocidad de reloj de la CPU llegando a reducir esta cerca de un 25% en un programa que use dichas instrucciones para momentos puntuales. Además, sus instrucciones están pensadas para aplicaciones de computación de alto rendimiento y de la IA que no son importantes en lo que es una CPU doméstica y la aparición de unidades especializadas lo convierten en una perdida de transistores y espacio.
En realidad, los aceleradores o procesadores de dominio específico están reemplazando poco a poco en las CPU a las unidades SIMD, ya que pueden hacer lo mismo ocupando menos espacio y con un consumo energético minúsculo en comparación.