
Uno de los temas que han aparecido en los últimos días es acerca del rendimiento de las AMD RX 6000 en comparación a las NVIDIA RTX 3000 en cuanto a Ray Tracing, donde la compañía del logo verde parece tener ventaja en rendimiento al hacer uso del trazado de rayos respecto a su rival directa. Pero, ¿existe otro motivo aparte de los ya conocidos?
El Ray Tracing se ha convertido en una de las novedades tecnológicas en cuanto a los gráficos se refiere, en especial desde que NVIDIA en la familia RTX 2000 añadió hardware para acelerar el llamado trazado de rayos a tiempo real, tendencia a la que se ha sumado hace poco AMD con su gama RX 6000 y de nuevo NVIDIA con sus RTX 3000.
Pero las cosas no están igualadas entre las NVIDIA RTX 3000 y las AMD Radeon RX 6000, ya que las segundas no están a la par en lo que al trazado de rayos se refiere, lo que en parte se puede explicar por la mayor cantidad de ALU del tipo FP32 que tienen los núcleos de las GPU de NVIDIA, pero eso solo es una porción de la historia.
¿Cuál es el problema del Ray Tracing en AMD RX 6000?
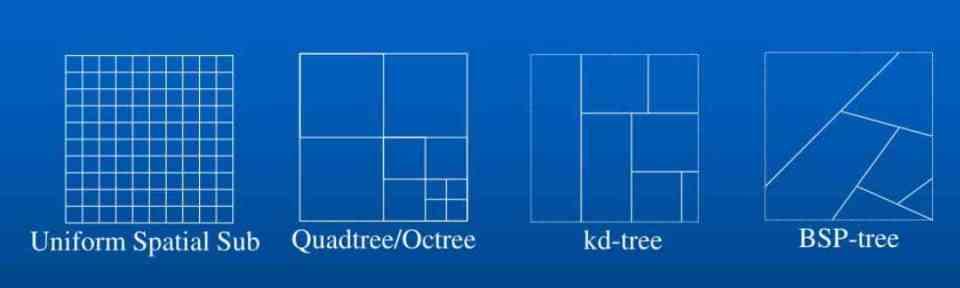
Uno de los puntos claves para hacer más rápido el Ray Tracing es el uso de estructuras de datos de aceleración, las cuales almacenan un mapa de la posición de los objetos en la escena.
¿Qué utilidad tienen? Sencillo, en el Ray Tracing evitan que se vayan lanzando rayos y testando hacía partes de la escena donde no hay nada, por lo que ahorran mucho tiempo y de ahí a que se llamen estructuras de aceleración, de las que no hay de un solo tipo, sino varios distintos.
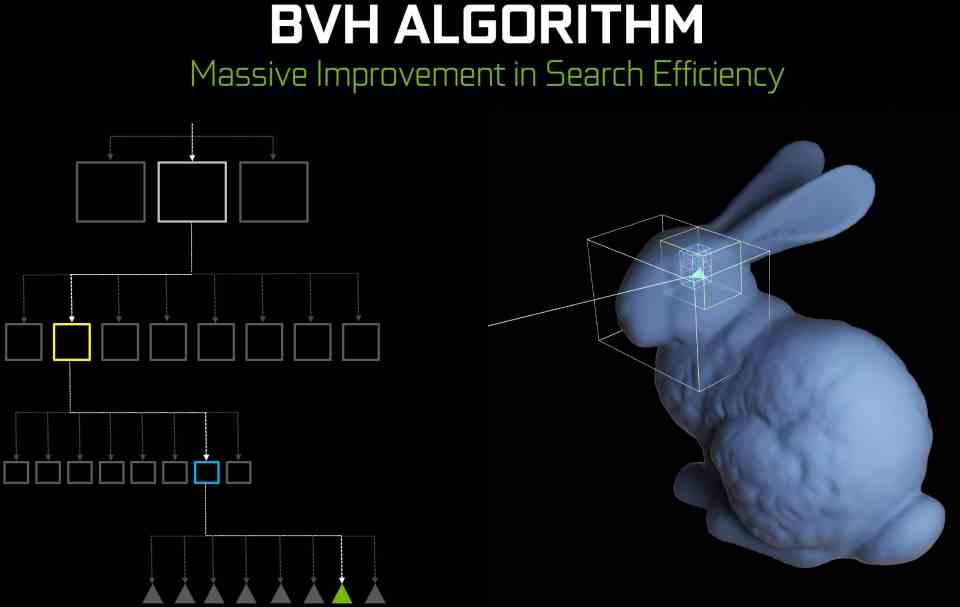
En el caso de NVIDIA decidieron añadir a sus RT Cores una unidad capaz de recorrer un tipo de estructura de datos: los árboles BVH. Esto significa que si utilizamos dicha estructura de datos a la hora de hacer trazado de rayos en nuestros juegos no tendremos que invocar un programa Compute Shader para hacer el recorrido.
Pero, en el caso de AMD han decidido no dar preferencia a ningún tipo de estructura de aceleración, lo que significa que el recorrido ha de ser controlado por un programa compute shader en el caso de que se utilicen las clásicas estructuras de datos en árbol como son los Octrees, árboles BVH, KD-Trees, etc.
Una simple explicación de lo que es un árbol

En informática, los árboles no son una estructura de datos ordenada y en lista, sino jerarquizada, esto significa que a la hora de recorrerlos el procesador va a tener que tomar varias iteraciones.
- El nodo en el que empieza el árbol se denomina raíz.
- Todo nodo que tiene uno o varios nodos por debajo el nodo padre.
- Todo nodo que tiene un nodo por encima en nodo hijo.
- Todo nodo que esta al final de la jerarquía se le llama hoja.
No hay que confundir los árboles con los saltos condicionales en el código. Los cuales se basan en saltar a una línea u otra cuando se da una condición concreta en el código. Los árboles en cambio suponen que cuando hay varios nodos lo mejor es que sean enfocados por varios hilos de ejecución distintos, uno por cada iteración.
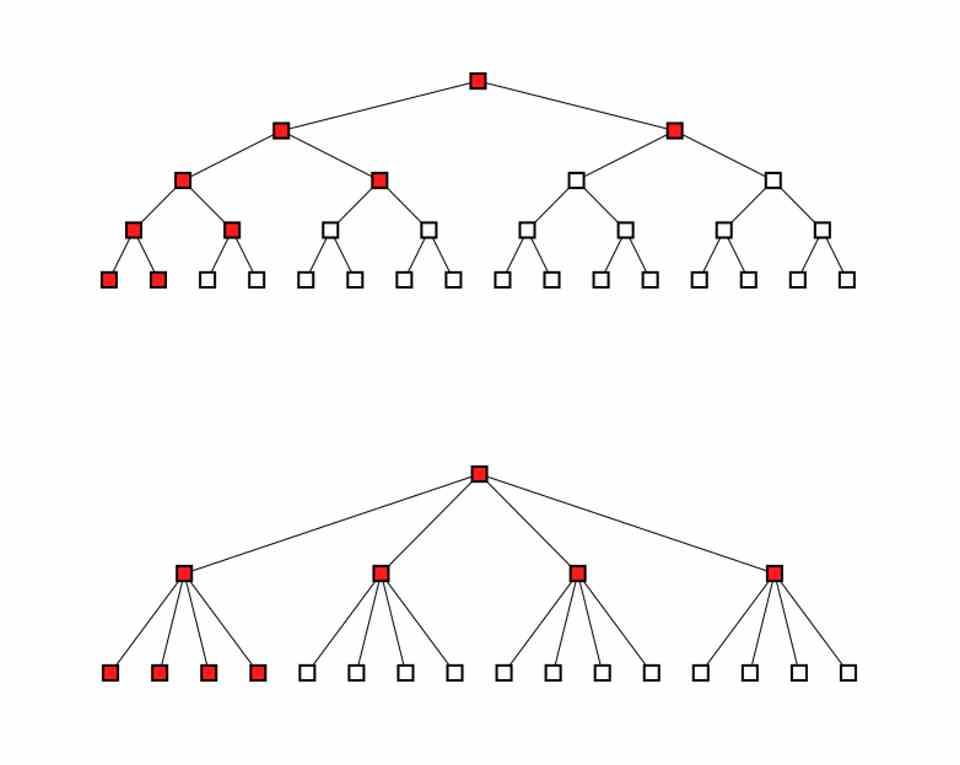
Las GPUs contemporáneas, suelen tener unidades shader compuestas por 4 ALU SIMD, donde cada una de ellas ejecuta un hilo de ejecución distinto. Por lo que pueden ejecutar sin problemas árboles de hasta 4 nodos. Claro está que cuando una Compute Unit empiece a recorrer un nodo entonces le saldrán más y más sub nodos por lo que la cantidad de hilos a ejecutar que saldrán será muy alta.
Es por ello que NVIDIA le añadió hardware especializado en recorrer árboles BVH a sus RT Cores. Para evitar no tener que utilizar las unidades shader para ello, no obstante, esta unidad solo funciona para dicho tipo de estructura de datos, pero a cambio se recorre dicha estructura de datos muy rápidamente.
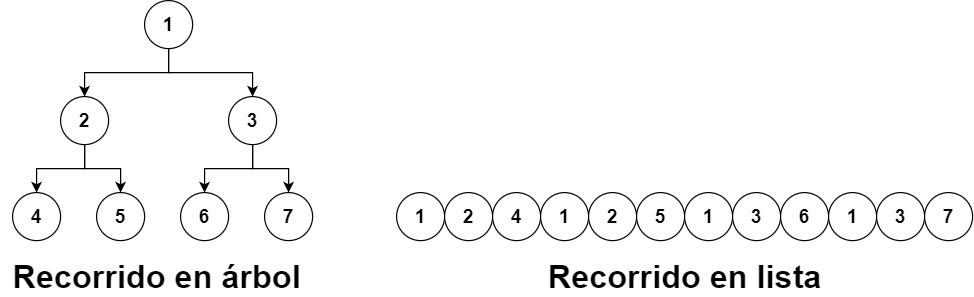
Pero, existe una forma en la que se pueden presentar los datos de un nodo y es presentar los diferentes recorridos de manera línea, esto permite enviar los datos en un array unidimensional que es lo que es una textura 1D, lo cual es la mejor manera de enviar los datos a las GPUs de AMD.
La solución por parte de AMD, es que los desarrolladores presenten la estructura de datos para la aceleración en forma de textura. Claro está, que esto viene de la decisión que han tomado de no añadir un hardware especializado en recorrer un tipo de estructura en árbol concreto, dando preferencia a una mayor versatilidad en vez de hacerlo a una mayor velocidad.
Esto hace que los desarrolladores por el momento tengan que adoptar medidas especializadas para cada marca de tarjetas gráficas a la hora de implementar el Ray Tracing.
¿De dónde viene la discrepancia?

Algunos os preguntaréis el motivo por el cual AMD ha decidido no incluir hardware para recorrer la estructura de datos y este es bien simple, no forma parte de la especificación mínima de DirectX Ray Tracing.
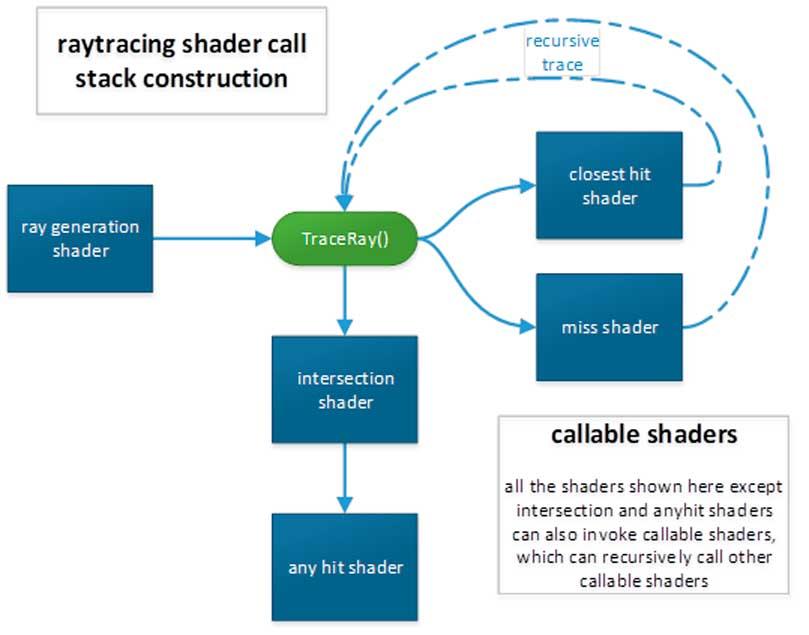
Es más, en DXR podemos realizar el Ray Tracing reemplazando las unidades de intersección por unidades Shader, que ejecuten un tipo de shader llamado Intersection Shader. Pero, las unidades de intersección especializadas que han incluido AMD y NVIDIA en sus GPUs, son mucho más eficientes porque hacen el mismo trabajo varias veces más rápido ocupando solo una porción de la GPU.
A lo que nos referimos, es que Microsoft a la hora de crear su API no puso bajo la mesa la forma en la que el hardware tenía que funcionar y esto le ha dado margen a AMD para prescindir de un hardware especializado para recorrer estructuras de datos en árbol, lo que ha afectado al rendimiento de sus tarjetas gráficas.

Aunque en la patente del Ray Tracing de AMD se hablaba de la inclusión de una unidad capaz de recorrer árboles de 4 nodos, BVH-4. También avisaba que era algo opcional y por la información que se puede sacar de la ISA RDNA 2 recién publicada no hay referencias a la unidad encargada de atravesar los árboles, solo a las instrucciones de intersección.