
La presentación de Ampere como arquitectura general dejó en el tintero todos los detalles de su chip estrella, el A100, una GPU que no veremos en gaming como tal, ya que está destinada a HPC e IA. Dicho monstruo dominaría el mercado presumiblemente en solitario, pero Graphcore ha llegado para dar un golpe en la mesa con su nuevo GC200, un chip igual de monstruoso con 8832 hilos y unas prestaciones de infarto. ¿Es más potente que el A100?
Estamos en la era de la inteligencia artificial, un sector que avanza a marchas forzadas para intentar satisfacer las necesidades de la industria y que por ahora no consigue. La demanda de sistemas inteligentes va muy por delante de la oferta y NVIDIA lo sabe, no en vano se califica como una empresa polivalente que también fabrica chips para el mercado del gaming.
Pero en esta ocasión el rival de NVIDIA no será AMD, sino Graphcore, los cuales acaban de presentar su chip masivo de 7 nm GC200, con unas prestaciones realmente de locura.
Graphcore Colossus MK2 GC200, Ampere no está sola
Desde el mundo gamer siempre tendemos a pensar que NVIDIA incluye los chips más avanzados de la industria, como así es, pero lo hace dentro del mundo gaming. Fuera de él la compañía tiene varios competidores que pueden plantarle cara, como es el caso de Graphcore.

Su chip Colossus MK2 GC200 también es fabricado por TSMC a 7 nm como el A100 de NVIDIA y logra un hito bastante importante que seguro no les gusta a los de Huang: en casi la misma área total (823 mm2 frente a 826 mm2) logra ser más denso en cuanto a millones de transistores. Para ser específicos, Graphcore ha logrado introducir 59,4 mil millones de transistores frente a los 54,2 mil millones de NVIDIA.
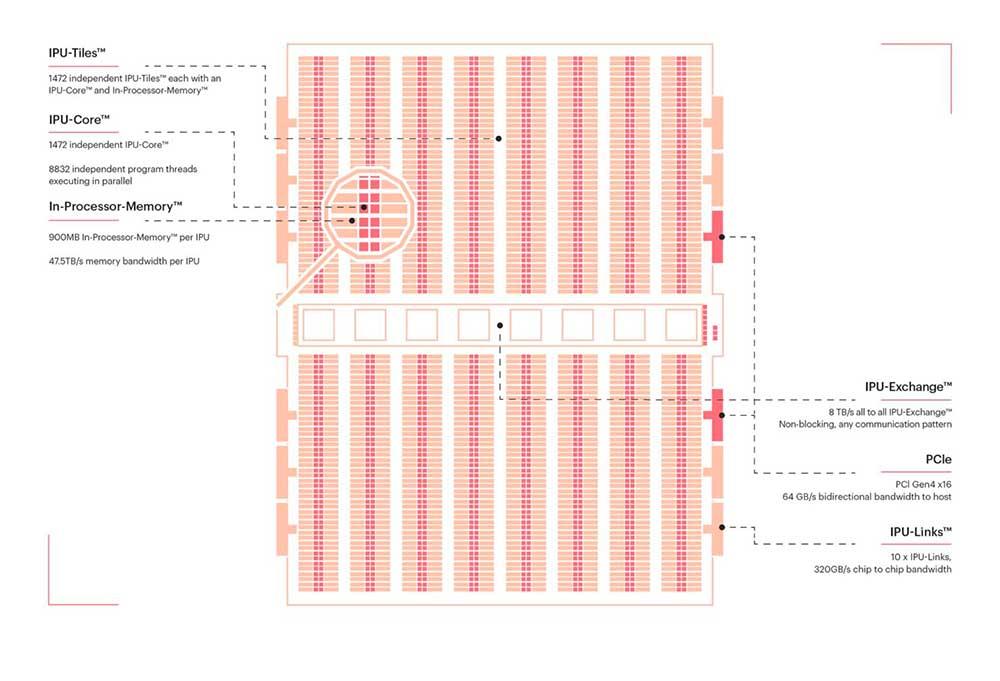

Es decir, con un -0,36% de área han logrado un 9,59% más de transistores. Pero, ¿qué incluye dicho chip? De entrada incluirá 1472 IPU, donde cada uno de ellos tendrá sus núcleos específicos y memoria destinada. En concreto, Graphcore asegura que cada chip porta 1472 Cores por procesador, donde cada IPU tiene hasta 6 subprocesos que se pueden ejecutar totalmente en paralelo, por lo que el número de hilos/procesos totales asciende hasta los 8832 por cada chip.
Como decimos, cada chip tiene una serie de memoria integrada en él, 900 MB en concreto, y aunque es una cifra pequeña, la compañía ha intentado centrar sus esfuerzos en el ancho de banda de la misma, ya que han logrado nada menos que 47,5 TB/s por chip. Como estos van a ir en distintos racks, el problema de la memoria se disipa por la escalabilidad que presentan.
NVIDIA quedaría por detrás en Sparsity

Sparsity en Deep Learning e IA es denominado como matrices que contienen principalmente valores cero. Por el contrario, las matrices que la mayoría de sus valores no son cero se denominan dense.
En estos escenarios los chips pierden mucho tiempo en los cálculos de los valores Sparsity, ya que les es costoso representar y trabajar con este tipo de matrices como si fuesen densas. Por ello, las compañías valoran el rendimiento en este tipo de matrices para compararse entre ellas, algo que debemos tener en cuenta para valorar los siguientes datos.


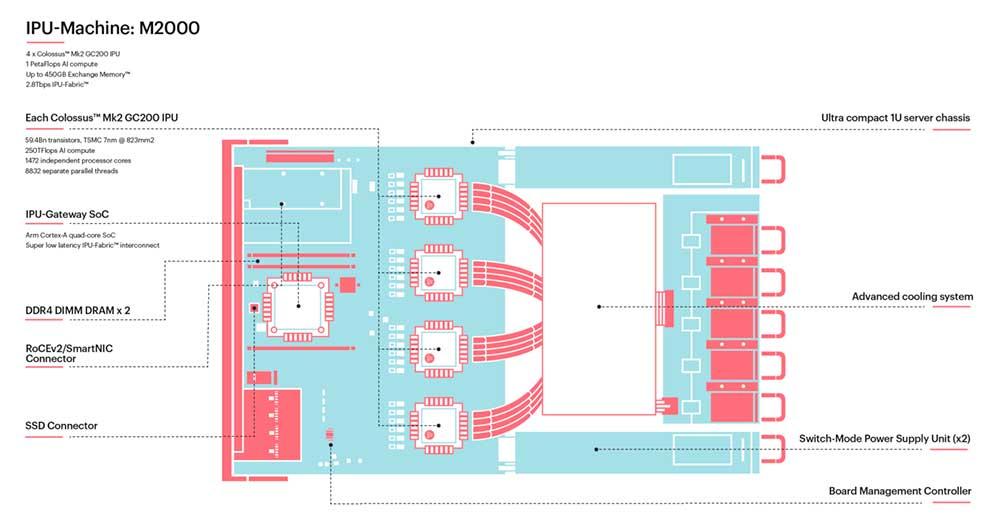
Los equipos DGX-A100 de NVIDIA se enfrentarán de tú a tú con los racks de Graphcore con 8 M2000, donde cada uno integra cuatro chips GC200. Según los datos de la compañía, NVIDIA lograría un rendimiento de 5 TFLOPS en FP16 bajo Sparsity, mientras que los M2000 conseguirían 8 TFLOPS.
En FP32 los datos van más allá, con 1,2 PFLOP en FP32 frente a los 2 PFLOP que lograrían los racks de Graphcore. Si miramos los precios, los equipos de NVIDIA se ofrecen por 199.000 dólares, mientras que los de su rival ascienden a 259.600 dólares por cada uno de ellos.




Esto determina que la opción de Graphcore es un 30% más cara, pero un 60% más potente. Por si fuese poco, los M2000 pueden apilarse hasta conseguir 64.000 chips en total, dando un rendimiento masivo de 16 exaflops, todo un exascale.
Por desgracia no se han facilitado datos de consumo, así que no se pueden establecer comparativas de eficiencia, ya que solo tenemos los 400 vatios del A100 de momento. Los envíos comenzarán a partir del 4T de este 2020, así que NVIDIA tiene trabajo que hacer si pretende competir contra Graphcore en Inteligencia Artificial.