
El momento que muchos estaban esperando llegó y NVIDIA levantó el velo de su arquitectura Ampere y sobre todo de la GPU que va a marcar un antes y un después en la era de la informática. La NVIDIA Ampere GA100 es el chip más grande creado hasta la fecha por la compañía que se ha implementado en un interposer y llega para destrozar a la competencia con sus mismas armas: un proceso litográfico de 7 nm fabricado por TSMC.
Enfocada a competir en el mercado de HPC, tal y como avisó NVIDIA esta GPU es la más grande diseñada hasta la fecha y como veremos a continuación, los números son realmente de vértigo y no tienen comparación posible.
Preparada como una tarjeta para investigación científica, para inteligencia artificial o redes neuronales por destacar algunas de las tareas donde será implementada, NVIDIA enfoca un campo con alta rentabilidad y deseoso de potencia con un gran optimismo.
NVIDIA Ampere GA100, la creación del monstruo que destroza a AMD

Aunque nada va a tener que ver esta versión con su esperada tarjeta para gaming, NVIDIA ha sacado de inicio todo el músculo que tenía y ha puesto de entrada toda la carne en el asador para sorprender al mundo y asustar a sus rivales. En primer lugar, esta Ampere GA100 siendo el chip de mayor tamaño y en su configuración máxima llegará al mercado en varios formatos: Mezzanine, PCIe 4.0 y posiblemente MXM.
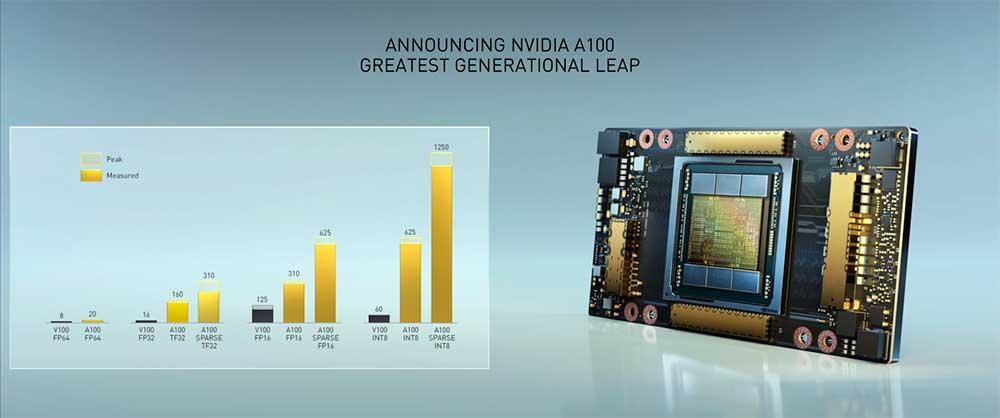
Esto no es realmente extraño, ya que NVIDIA lo hizo con Volta, pero si miramos su tamaño… sorprende. Tiene un área de 826 mm2 y supera a su predecesora por 11 mm2, algo que quizás no sea muy llamativo, pero en ese espacio de más que contiene para hacer su área total NVIDIA haya logrado incluir 54 mil millones de transistores.
Es decir, en 826 mm2 de silicio se albergan 54.000.000.000 de transistores, más del doble que en su predecesora. Por lo tanto, estamos hablando de la GPU más densa jamás diseñada y creada hasta el momento y por mucho.
Especificaciones técnicas
| GPU | Kepler GK110 | Maxwell GM200 | Pascal GP100 | Volta GV100 | Ampere GA100 |
|---|---|---|---|---|---|
| Capacidad de cálculo | 3.5 | 5.3 | 6.0 | 7.0 | 8.0 |
| Hilos / Warp | 32 | 32 | 32 | 32 | 32 |
| Max Warps / Multiprocesador | 64 | 64 | 64 | 64 | 64 |
| Max hilos / multiprocesador | 2048 | 2048 | 2048 | 2048 | 2048 |
| Max Thread Blocks / Multiprocesador | 16 | 32 | 32 | 32 | 32 |
| Max registros de 32 bits / SM | 65536 | 65536 | 65536 | 65536 | 65536 |
| Max registros / bloque | 65536 | 32768 | 65536 | 65536 | 65536 |
| Max registros / hilo | 255 | 255 | 255 | 255 | 255 |
| Tamaño máximo de bloque de hilo | 1024 | 1024 | 1024 | 1024 | 1024 |
| Núcleos CUDA / SM | 192 | 128 | 64 | 64 | 64 |
| Tamaño de memoria compartida / Configuraciones SM (bytes) | 16K / 32K / 48K | 96K | 64K | 96K | 164K |
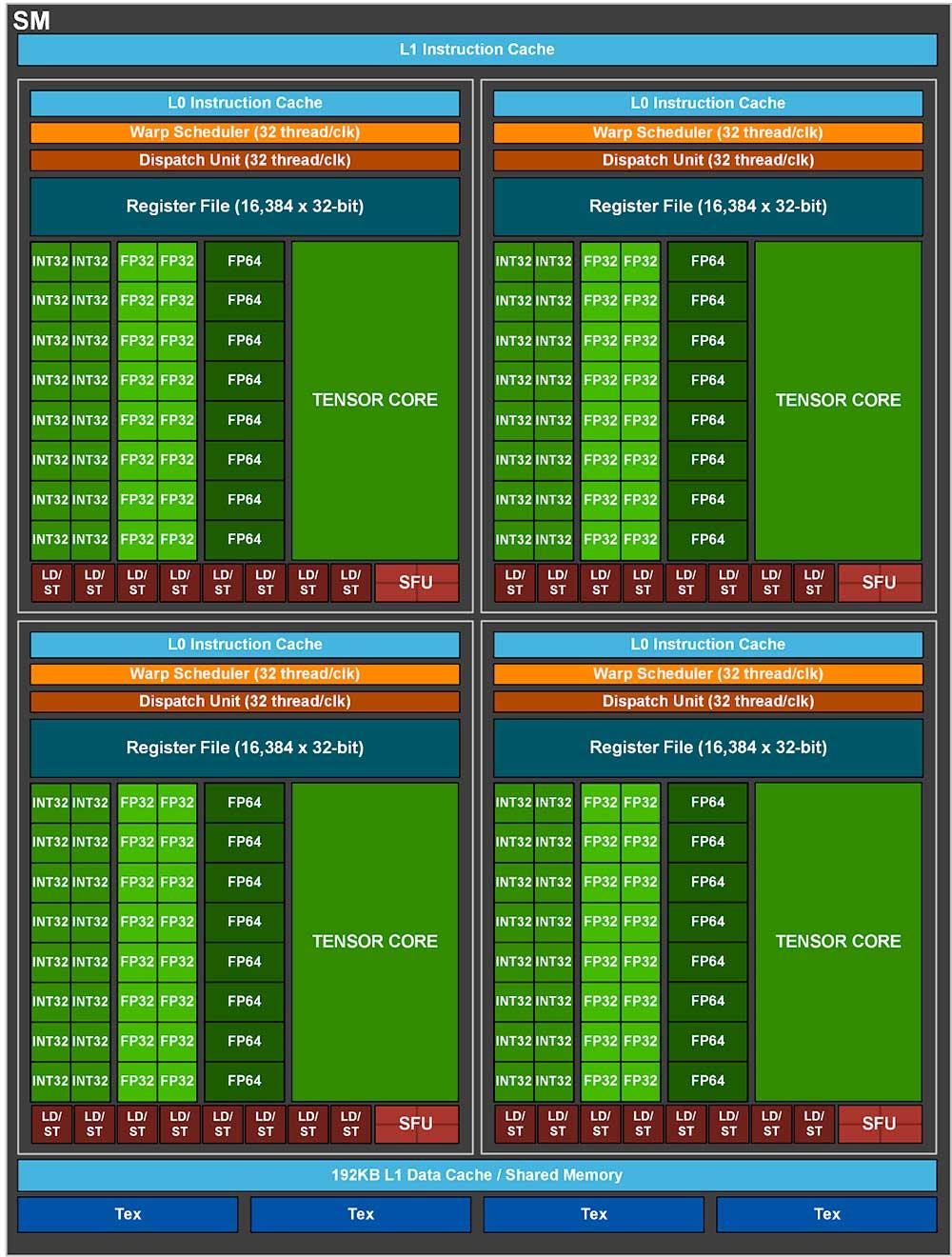
Si estos números ya marean, hay que tener en cuenta que contiene 128 SM con 8192 núcleos CUDA, los cuales se reparten en 8192 Shaders capaces de trabajar con FP32, 4096 capaces de trabajar en FP64 y además 512 Tensor Cores, todo en 8 GPC donde cada uno contiene 16 SM y 8 TPC.
Estos números tan impresionantes también se ven reflejados en su consumo, ya que NVIDIA ha revelado que cada Ampere GA100 llegará hasta los 400 vatios en su variante Tesla A100.



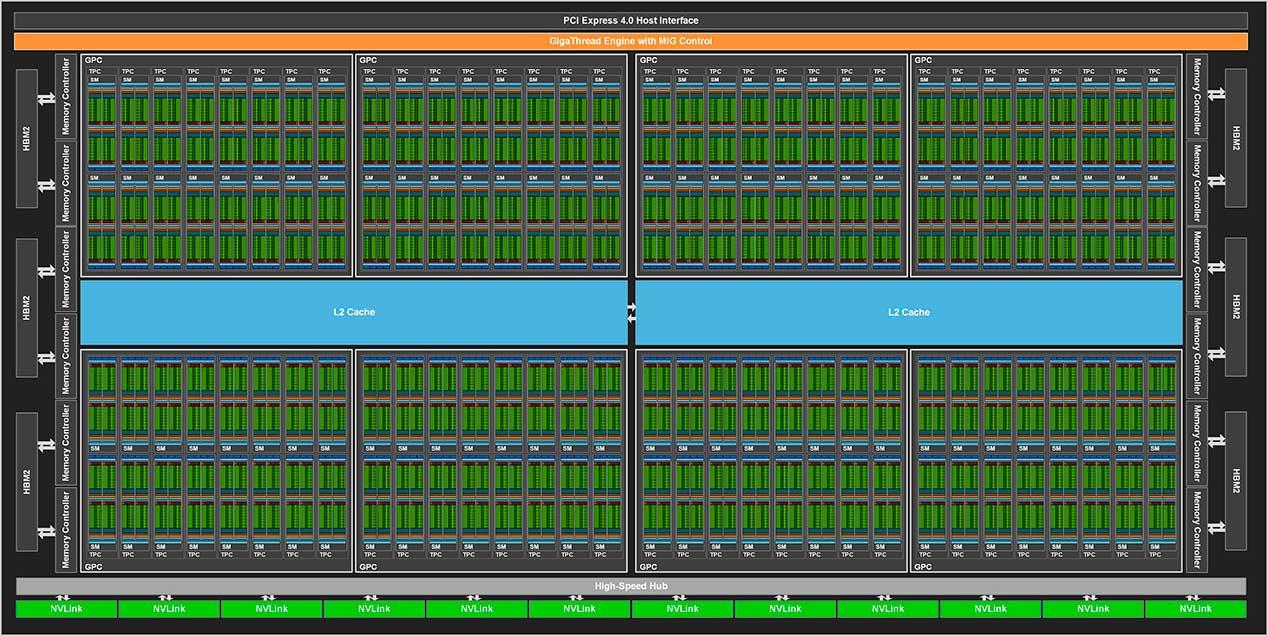
Si esto no nos ha parecido suficiente, esta GPU integrará un bus de 6144 bits al que le acompañarán 48 GB de memoria HBM2E mediante seis pilas, todo en un solo interposer.
Cada stack tiene una capacidad de 2 GB, por lo que cada die albergará 4 Hi con un total de 8 GB donde cada una de ellas tendrá una velocidad por pin de más de 2 Gbps. Esto nos dejaría una cifra total de auténtico vértigo para el ancho de banda: 1,6 Tbps.
La Ampere GA100 tendrá su versión recortada en la Tesla A100

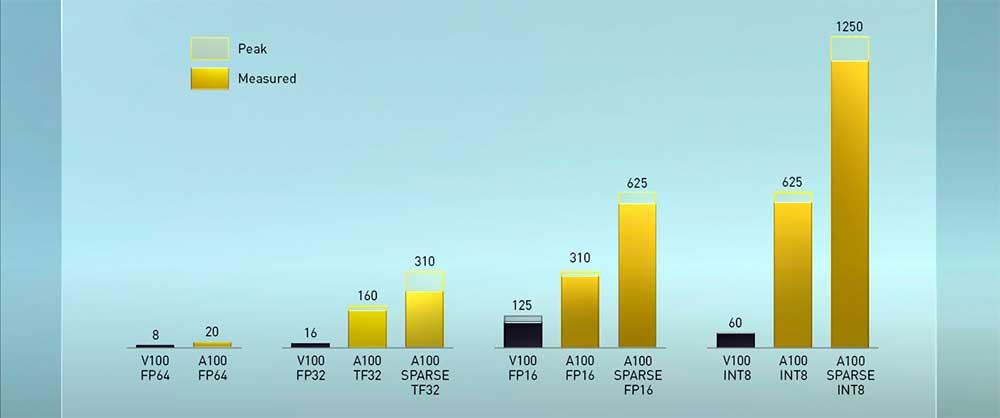


Como era de esperar, NVIDIA lanzará sus GPU Tesla con algunos recortes en las especificaciones del chip que, esta vez sí, pueden comenzar a darnos algunas pistas de si los rumores sobre el GA102 son ciertos o no.
Estas Tesla A100 llegarán con chips GA100 recortado, ofreciendo solo 108 SM con 6912 núcleos para FP32, 3456 núcleos que podrán trabajar con FP64 y 432 Tensor Cores. El bus por lo tanto también se verá reducido, en concreto a una cifra igualmente impresionante de 5120 bits que dará como resultado una cantidad de VRAM de 40 GB.
Los consumos variarán entre los 400 vatios y los 300 vatios, según el formato y la frecuencia que alberguen, algo que NVIDIA no ha dejado realmente claro.
Los equipos DGX volverán a usar las versiones Tesla V100, pero esta vez bajo Ampere


No hay sorpresas aquí y mucho menos desde que Huang lanzó el ya famoso vídeo del horno. Sus equipos DGX y HGX de la compañía se centrarán en IA y cargas HPC, por un lado, y computación en la nube y centros de datos por otro.
Serán en cualquier caso equipos de tercera generación que podrán ser configurables en hasta 10U, una auténtica locura en la actualidad. Cada servidor tendrá 8 de estas placas V100 que NVIDIA presentó y utilizarán los ya sabidos enlaces mediante PCIe 4.0 para maximizar su rendimiento.
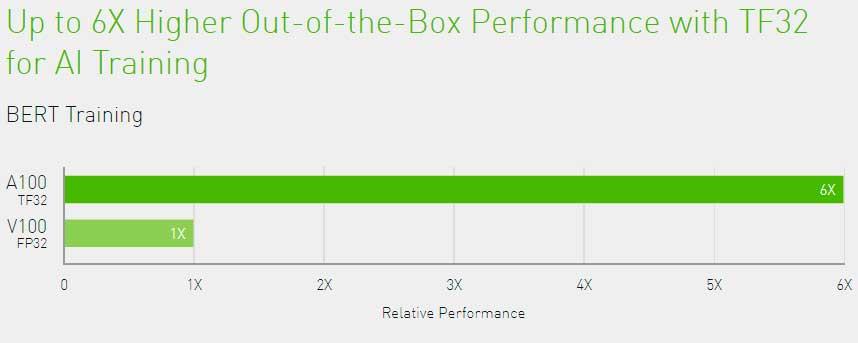

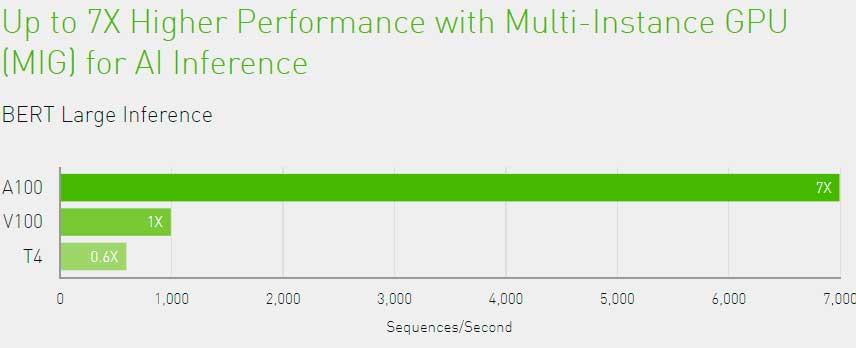

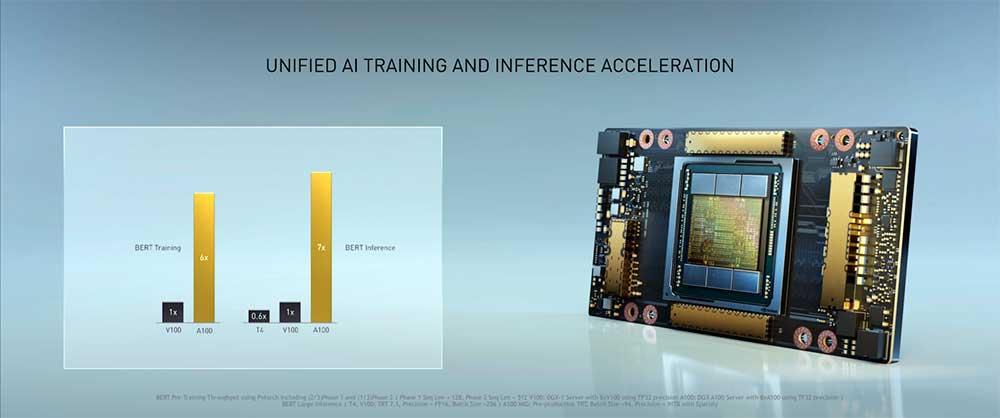
Huang ofreció cifras más concretas de potencia, en concreto, afirmó que el DGX-A100 llegará hasta los 5 Petaflops mediante sus 8 GPUs Tesla A100 Ampere, una cifra que supera por 20 el rendimiento de su anterior versión basada en Volta.
Los sistemas comienzan en un precio de 199.000 dólares y están disponibles a partir de hoy mediante la red de distribuidores de NVIDIA. Como supondréis esto no es algo diseñado para el usuario de a pie.