
La inteligencia artificial (IA) es el futuro de cualquier sector. Desde el bancario, pasando por tiendas online, o criptomonedas, todo se adaptará para sacar provecho del aprendizaje profundo y de las redes neuronales DNN, las cuales hasta ahora estaban basadas en GPUs por su mayor número de unidades de cómputo. Pero un nuevo descubrimiento mediante un algoritmo puede poner este sector patas arriba, y es que promete hacer que las CPU rindan 15 veces más que las GPU, ¿es esto posible?
Si hay una carga de trabajo que en la actualidad exija al hardware actual es una red neuronal profunda. Los cálculos en el campo de la IA por norma general se consiguen con el uso de fuerza bruta, lo que supone que a cada nueva mejora de CPU o GPU se logra un escalado de rendimiento casi perfecto. Pero el sector hasta ahora se ha estado volcando en las tarjetas gráficas por su mayor potencia de cómputo para paralelizar tareas, ya que casi todos los algoritmos existentes se basan en multiplicaciones de matrices, pero ¿y si esto se acabase y las tornas se girasen?
AVX512 y AVX512_BF16, principales impulsoras del rendimiento en CPU
Ha sido desde la Escuela de Ingeniería Brown de Rice donde el profesor Anshumali Shrivastava y su equipo han presentado un nuevo algoritmo para redes neuronales profundas DNN mediante las instrucciones de nueva generación AVX512 y su derivada BF16.
Shrivastava dejó unas declaraciones más que interesantes:
Las empresas están gastando millones de dólares a la semana solo para entrenar y ajustar sus cargas de trabajo de IA. Toda la industria está obsesionada con un tipo de mejora: multiplicaciones de matrices más rápidas. Todos buscan hardware y arquitecturas especializadas para impulsar la multiplicación de matrices. La gente ahora incluso habla de tener pilas de hardware y software especializadas para tipos específicos de aprendizaje profundo. tomando un algoritmo [computacionalmente] caro, yo estoy diciendo: ‘Revisemos el algoritmo’
Para llevar esto a cabo los científicos usaron un motor C++ basado en OpenMP como SLIDE y trabajaron en él para las instrucciones AVX512 y AVX512-bfloat16 de Intel y los resultados fueron sorprendentes.
La multiplicación de matrices podría no ser el camino en SLIDE
El motor usa como base LSH, optimizando con ello los requisitos de rendimiento mediante la aceleración de tablas hash, lo que según el coautor del estudio, Shabnam Daghaghi, implica que una CPU puede superar el rendimiento de una GPU.
Para lograr un hash más rápido, los investigadores vectorizaron y cuantificaron el algoritmo para dichas instrucciones, sabedores de su potencial, y mejoraron la asignación en memoria de algunos puntos del algoritmo.
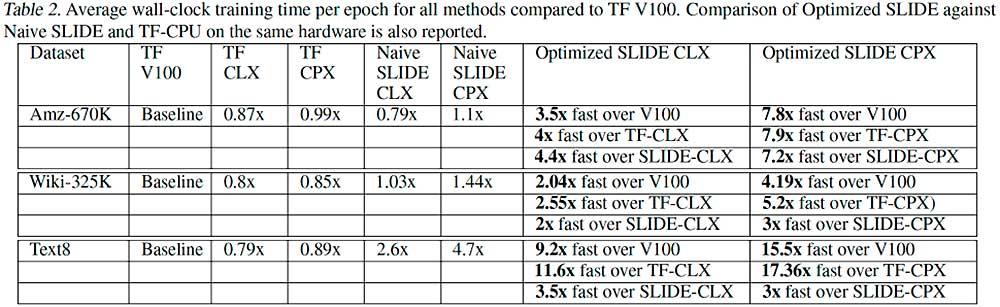
«Aprovechamos las innovaciones de CPU [AVX512 y AVX512_BF16] para llevar SLIDE aún más lejos, demostrando que si no se está obsesionado con las multiplicaciones de matrices, se puede aprovechar la potencia de las CPU modernas y entrenar modelos de IA de cuatro a 15 veces más rápido que el mejor hardware especializado como alternativa.»
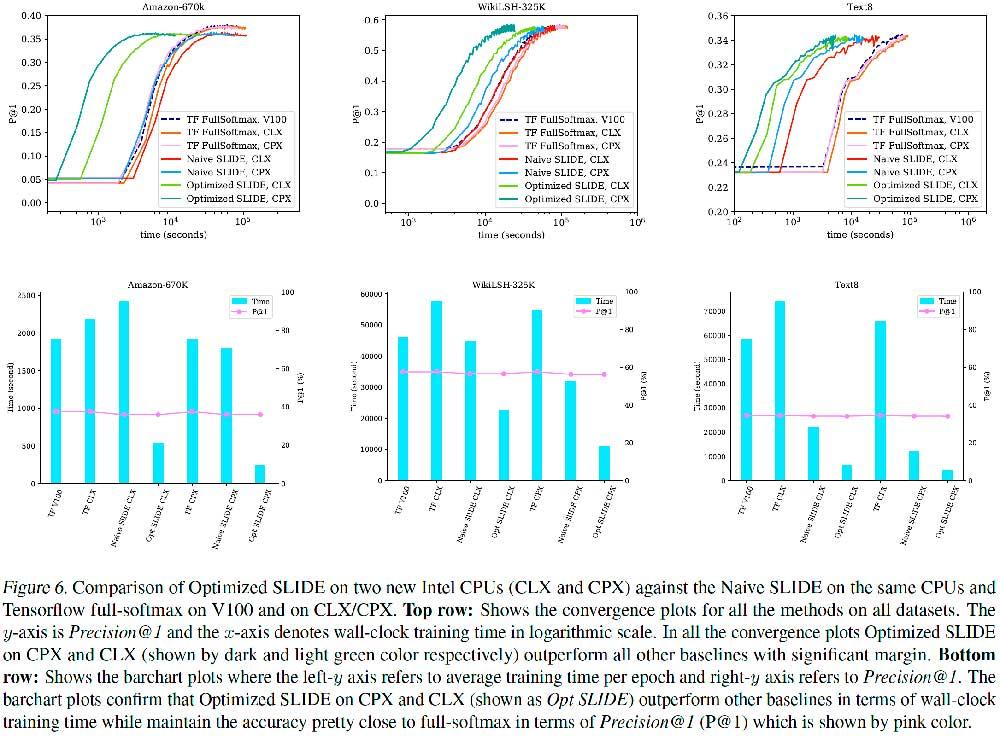
Ya entrando en datos comparativos y rendimientos, hablamos que un procesador Cooper Lake de Intel puede superar a toda una NVIDIA Tesla V100 en 7,8 veces con Amazon-670K, 5,2 veces frente a WikiLSHTC-325K y casi 15,5 veces con Text8.
Incluso una CPU Cascade Lake es capaz de superar por más del doble a la V100 de NVIDIA. Falta ver cuánto puede rendir una A100 frente a una CPU Intel Cooper Lake con SLIDE, pero es más que probable que siga por detrás, así que teniendo en cuenta que los procesadores están en todo equipo, podríamos estar ante un cambio de paradigma en el sector de la IA, un cambio de tendencia que afectaría a NVIDIA y AMD en favor (de momento) de Intel.