
Seguro que los que nos seguís a diario sabéis de sobra lo que es el SMT, cómo funciona y cómo se integra en un procesador tanto actual como «antiguo», pero tanto si eres de estos usuarios como si acabas de llegar de nuevas, ¿sabes realmente lo que es SIMD y SIMT? pero sobre todo, ¿por qué se habla de ellas en los procesadores? La respuesta está en las instrucciones y en los cuellos de botella, así que vamos a conocerla.
Desde hace muchos años, Intel, AMD, NVIDIA e IBM han intentado optimizar las cargas de trabajo de sus procesadores con los sistemas donde van implementados.
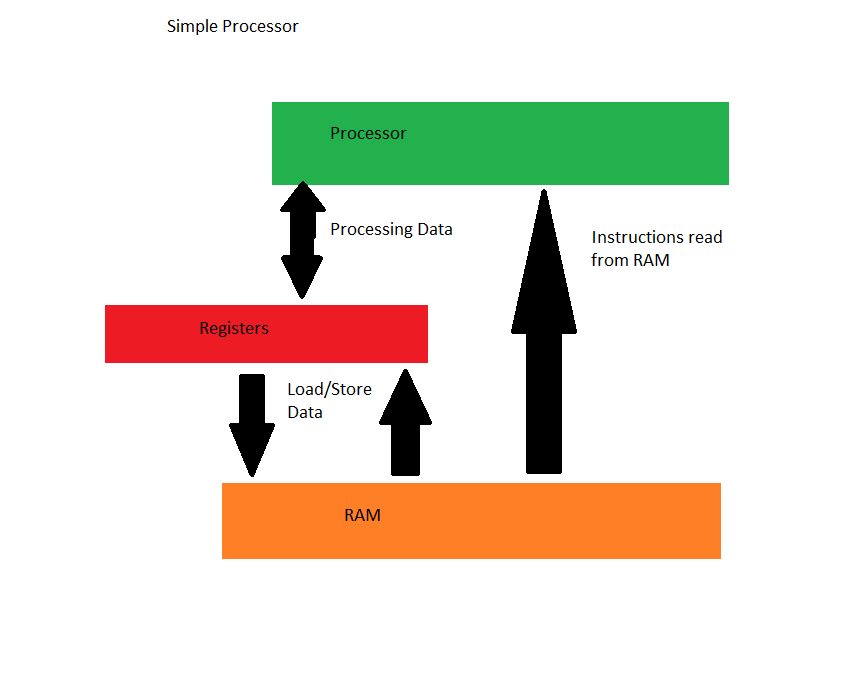
Como bien sabemos, las CPUs tienen varios tipos de unidades, como las ALU y las FPU, las cuales se han ido incrementando en número, potencia y capacidades.
Esto generó un problema clave en su momento, y era simplemente el nulo reparto de las intrucciones entre dichas ALU, donde en ocasiones se quedaban paradas sin ofrecer mayor rendimiento al procesador.
La distribución y optimización de las operaciones es fundamental
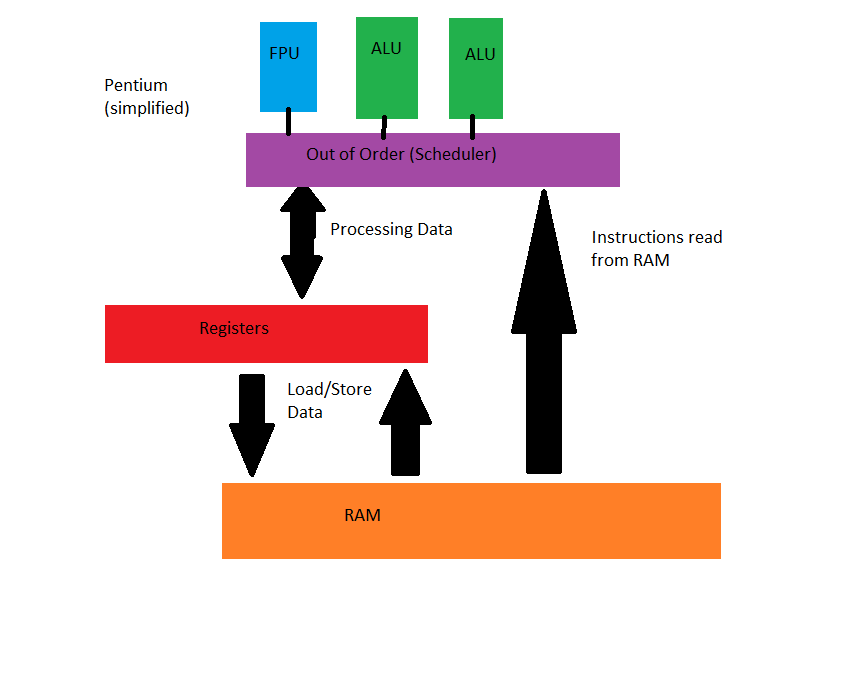
Los llamados Scheduler son los encargados de suministrar información, orden y lógica a las instrucciones por cada ciclo de reloj. Estos cogen los datos desde los registros, que a su vez cogen los que necesitan de la RAM, y juntos disponen las instrucciones con dicho Scheduler para las ALU y las FPU.
Al aumentar el número de registros e instrucciones por ciclo, se dio el caso de que las ALU se colapsaban por culpa del Scheduler, y cuando este último se mejoró lógicamente se necesitó aumentar el número de ALUs para maximizar el rendimiento del resto de áreas del procesador.
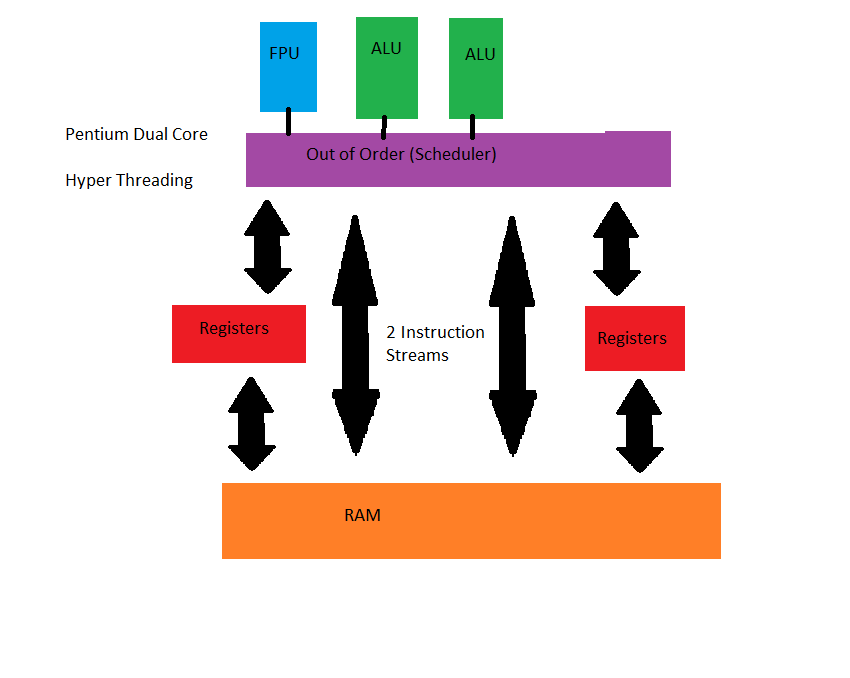
La solución pasó por incluir SMT a modo de HyperTraiding, donde el núcleo finge y simula tener múltiples hilos, dos en este caso, dando respuesta al problema vigente. El problema es que SMT o HT tienen un cuello de botella bastante particular: cuando el subproceso se llena se bloquea y deja al núcleo con una carga más baja de la habitual. Entonces, ¿cómo se solucionó este nuevo contratiempo?
En primer lugar incluyendo más núcleos, donde al poco tiempo volvieron los problemas, así que se desarrolló SIMT.
SIMT, el primer paso para la verdadera multi tarea y cálculo
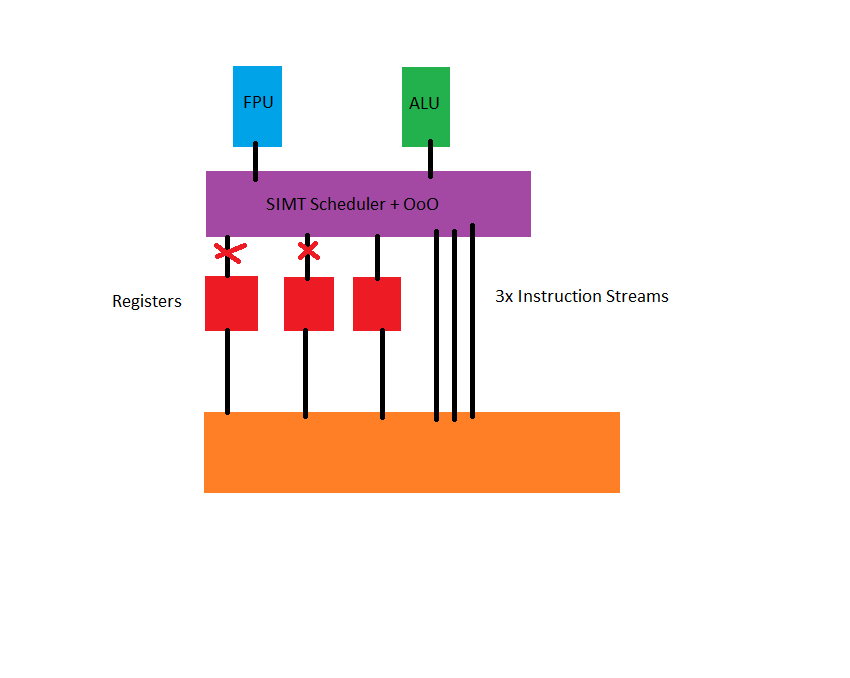
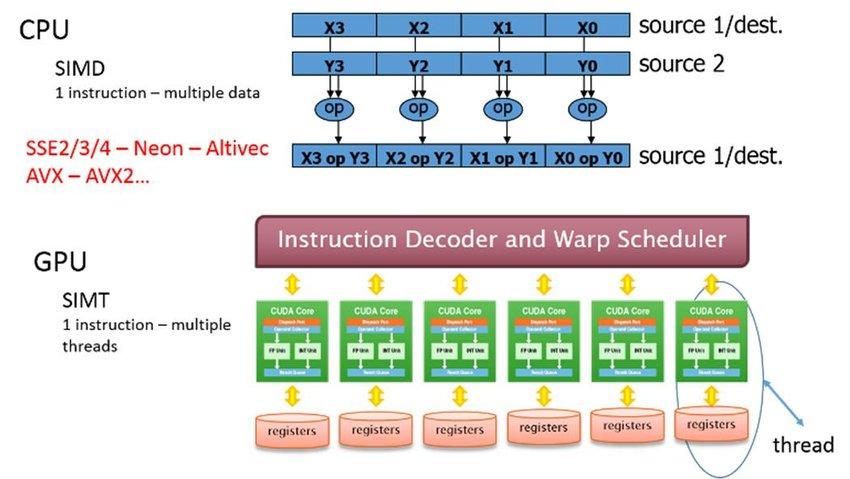
SIMT es el acrónimo de Single-Instruction Multiple Threads y su función básica es simplemente limitar la sobrecarga que el Scheduler es capaz de administrar, o dicho de otra manera, optimiza la ejecución de subprocesos cuando estos no están bloqueados en latencia o registros por los accesos a RAM o HDD/SSD (de ahí la importancia de estos últimos en la industria en los últimos años y cómo los fabricantes intentan empujar el rendimiento).
Esto fue una salvación para AMD e Intel, incluso para IBM, y más tarde para NVIDIA y ATI, ya que se optimizaba la carga en el OoO (Scheduler).
Con el paso de los años, estas unidades adquirieron más capacidad, de manera que ya los hilos no podían saturarlos por ciclo de reloj, así que curiosamente se obtuvo el antagonista al problema principal: se estaban dejando de usar los hilos de forma selectiva.
Aquí es donde precisamente entra en juego SIMD, ya que lo que se pretendió desde los fabricantes es no desperdiciar ciclos de reloj en espera de recursos, o un bloqueo por falta de los mismos.
El paralelismo llevado a las CPU y sobre todo, a las GPU gracias a SIMD
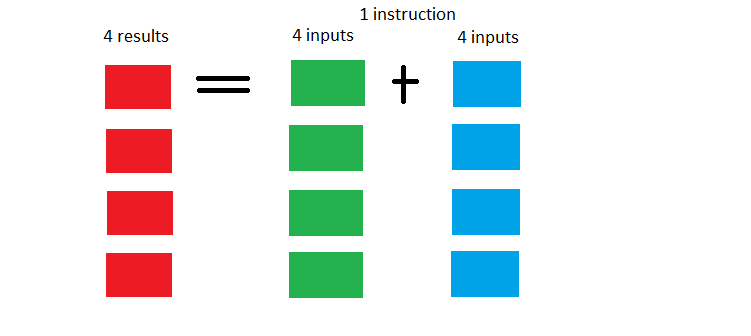
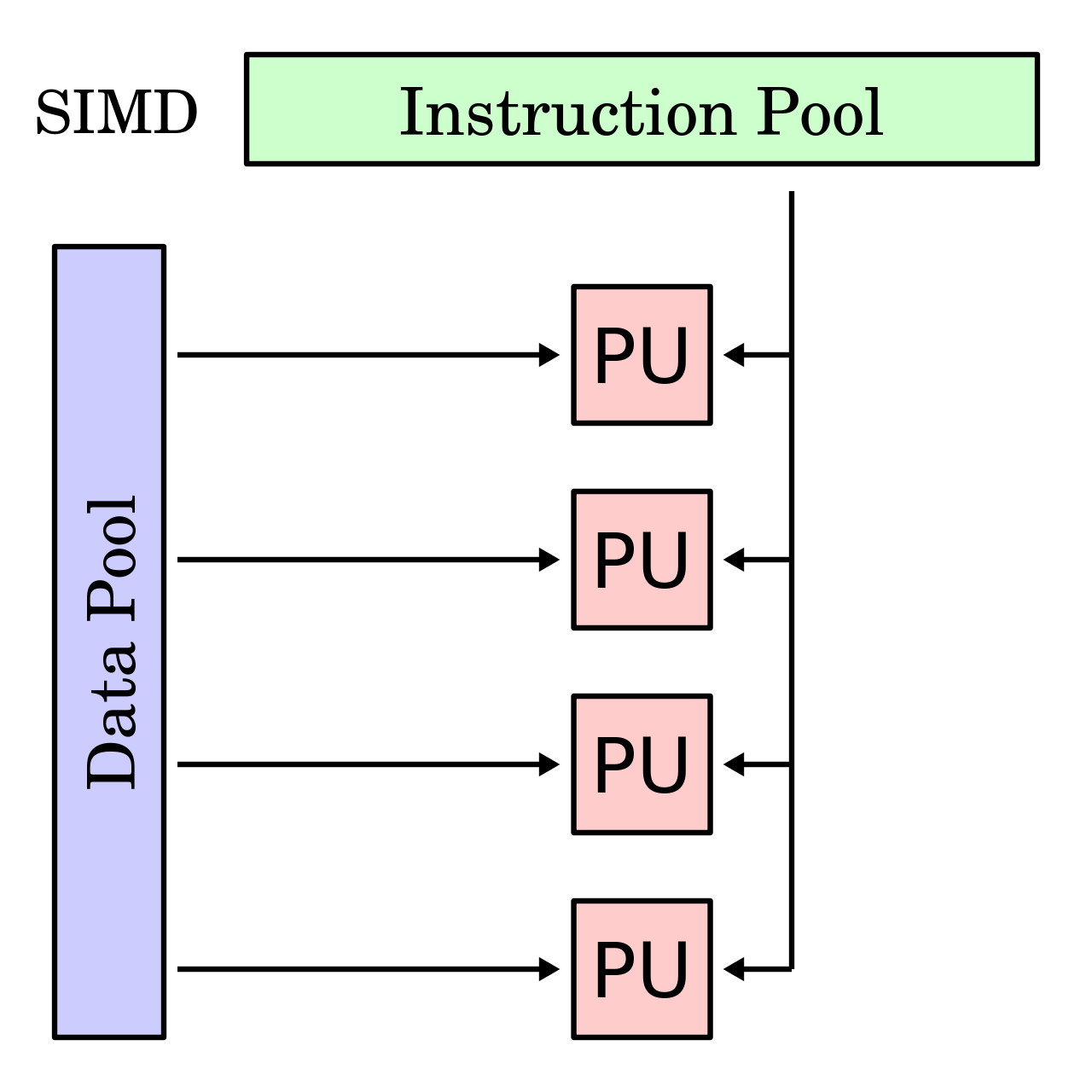
SIMD es el acrónimo de Single Instruction Multiple Data y como su propio nombre indica pretende conseguir con una sola instrucción trabajar con múltiples datos, o dicho de otra forma que seguro que nos suena mejor, busca paralelizar tareas.
Son por tanto unidades complementarias a las ALU, algo que en GPU se ha llevado al extremo y de ahí que sean mucho más óptimas para tareas de IA o HPC. En CPU hay un equilibrio más lógico por su propia naturaleza, pero en general SIMD lo que usa son vectores para permitir que una sola instrucción haga varias cosas al mismo tiempo.
Esto se entiende desde el punto de vista de la repetitividad. Las SIMD son unidades muy óptimas para ejecutar instrucciones una y otra vez para calcular valores en base a esa instrucción. Por lo tanto pueden realizar en un solo ciclo muchas más operaciones, lo que acelera el trabajo.
En procesadores esto es limitado porque no se suelen dar tanto este tipo de operaciones, pero al igual que en las tarjetas gráficas se ha terminado por instaurar la premisa de Scheduler con SIMT más unidades SIMD para las instrucciones, ambas en diferentes cantidades lógicamente.
Por lo tanto y ya entrando en cómo funciona una CPU moderna, el Scheduler SIMT solo da paso a las instrucciones cuando una unidad SIMD puede ejecutarla, permitiendo a los ingenieros balancear el número de ellas según los resultados de rendimiento muestren de la necesidad de añadir o quitar.
Además, hay que tener en cuenta que el número de registros también va relacionado con las capacidades del Scheduler, la velocidad y latencia de la RAM y las unidades de carga y descarga. Si a esto le sumamos la capacidad del motor de predicción de los procesadores modernos, podremos acercarnos a entender cómo Intel y AMD gestionan sus recursos, cómo aumentan su IPC y por qué es tan importante el balance de las cargas dentro de una CPU.