NVIDIA cambiaría los núcleos de las gráficas RTX 40, ¿su arma secreta?

Luces y sombras en las RTX 40 que podrían sorprender a todos, o al menos a casi todos. Lo veníamos adelantando cuando dijimos que era muy precipitado para la marca y fabricantes lanzarse de cabeza al PCIe 5.0 cuando el ancho de banda en sus nuevas GPU no colmaría siquiera los requerimientos de la versión anterior, y así parece que será finalmente. Y es que las RTX 40 solo tendrán soporte para PCIe 4.0, donde las novedades podrían estar en sus núcleos.
El soporte de Intel con Alder Lake para PCIe 5.0 es meramente testimonial en estos momentos y tanto es así que no hay producto en el mercado que lo soporte. Muchos pensaban que las nuevas RTX 40 cambiarían esto, pero la realidad es que serán los SSD ya en 2023 los que tengan el protagonismo bajo esta versión del bus, porque los de Huang tiene otros planes muy diferentes.
NVIDIA RTX 40: solo PCIe 4.0, pero con conectores PCIe Gen 5
El giro de Intel posicionándose como la empresa más innovadora en el sentido de las nuevas DDR5 y PCIe 5.0 es simplemente un espejismo que al mismo tiempo está siendo su muerte. Las memorias están por las nubes y parece ser que ni AMD ni NVIDIA van a seguirle el ritmo en el bus más codiciado de todos.
Aunque los Ryzen 7000 se pondrán a la altura de los Core 12 en este apartado parece que las gráficas van a ser más conservadoras, empezando por los verdes.
kopite7kimi@kopite7kimiPCIe Gen424 de mayo, 2024 • 07:24
68
5
Y es que según informa uno de los mejores leakers en la actualidad las RTX 40 serán PCIe 4.0 y no 5.0 como tal.
Esto implica que el ancho de banda disponible para ellas pasa de 128 GB/s o 64 GB/s en cada canal a la mitad de esta velocidad, es decir, 64 GB/s y 32 GB/s bidireccional. Pero esto solo es un atisbo de lo que está por llegar y no debería sorprendernos como tal pese a la incongruencia de PCIe 4.0 para el slot y el conector Gen 5 de hasta 600 vatios, necesidades del guion podríamos decir en este caso.
Los tres caminos de NVIDIA para las RTX 40
Lo más importante no es esta filtración en sí misma, sino el hecho de que se describe que el chip AD102 (y entendemos que el resto de ellos también) no han sido preconcebidos para algo tan simple como aumentar el número de Shaders en FP32.
Dicho de otra manera, se deja la puerta abierta a la opción de que NVIDIA tenga muchas sorpresas guardas bajo la manga, pero ¿en qué sentido? Pues aquí comienza la especulación más pura que vamos a encauzar en tres opciones distintas y ya veremos si acertamos en alguna más adelante en el tiempo.
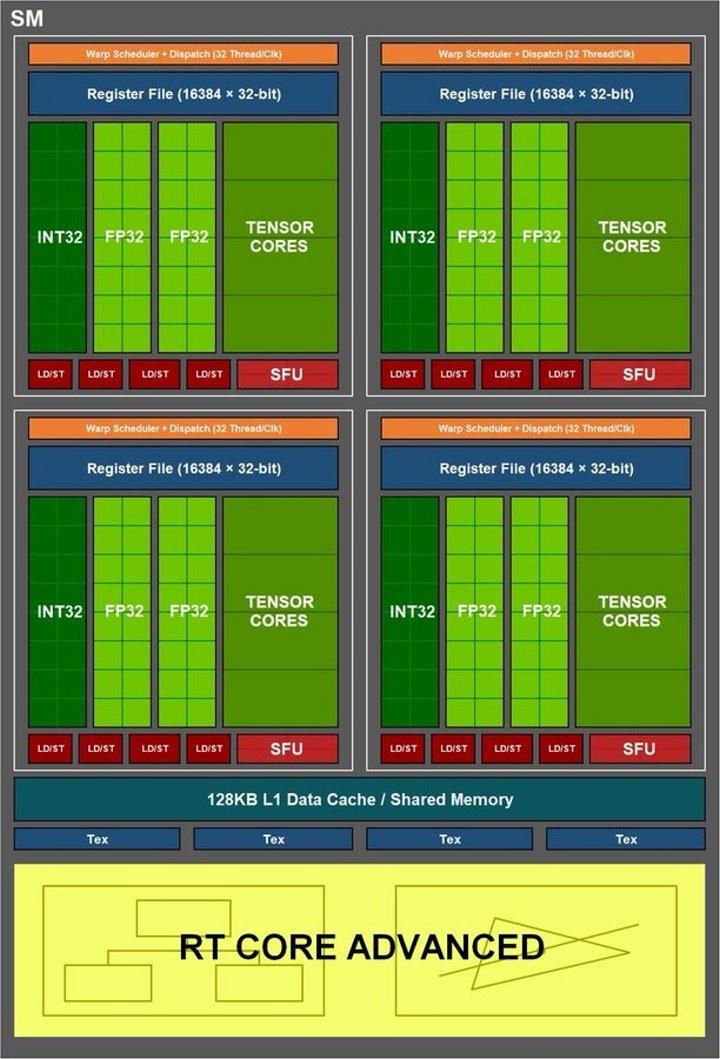
La primera podría definirse como un cambio generacional en los SM, modificaciones sustanciales que podrían indicar cambios en una o varias unidades inferiores como los RT Cores o Tensor Cores. En segundo lugar podría ser un cambio en el motor de los FP32 a secas, quizás aumentando el número de estos y con ello modificando el recuento total de Shaders.
Por último nos quedaría los cambios en el tercer motor con FP32 y INT32. Explicado esto vamos a entender hacia donde puede ir NVIDIA, porque es de lo más interesante. Cuando se presentó el SM de Ampere NVIDIA gráficamente lo sesgó en cuatro motores principales más los RT Cores, que son independientes dentro del renderizado aunque realmente en la pipeline de trabajo del Ray Tracing para mostrar los resultados del píxel y FPS al completo no es tal, pues es un renderizado de Ray Tracing y árbol BVH mixto y no individual.
kopite7kimi@kopite7kimiAttention, I never talked about the details of SM.
Don’t preconceived that AD102 has a simple 18432-FP32.24 de mayo, 2024 • 07:24
61
2
Aquí entran los tres argumentos enfocados de diferente manera. Los nuevos gráficos de los SM no muestran 4 motores independientes como tal, sino tres. Un motor unificado en FP32 e INT32, otro FP32 puro y los Tensor Cores para IA, más luego aparte los RT Cores que funcionan por separado como hemos explicado.
Reunificación de los SM
¿Y si NVIDIA reestructurase los SM? Es decir, podría unificar los FP32 y enteros aumentando con ello el conteo total hasta los rumoreados 18.432 Shaders (muy en el aire ahora mismo) y el espacio teórico que dejaría la unificación usarlo con los RT Cores y Tensor Cores como motores más cercanos dados los supuestos cambios en las cachés.
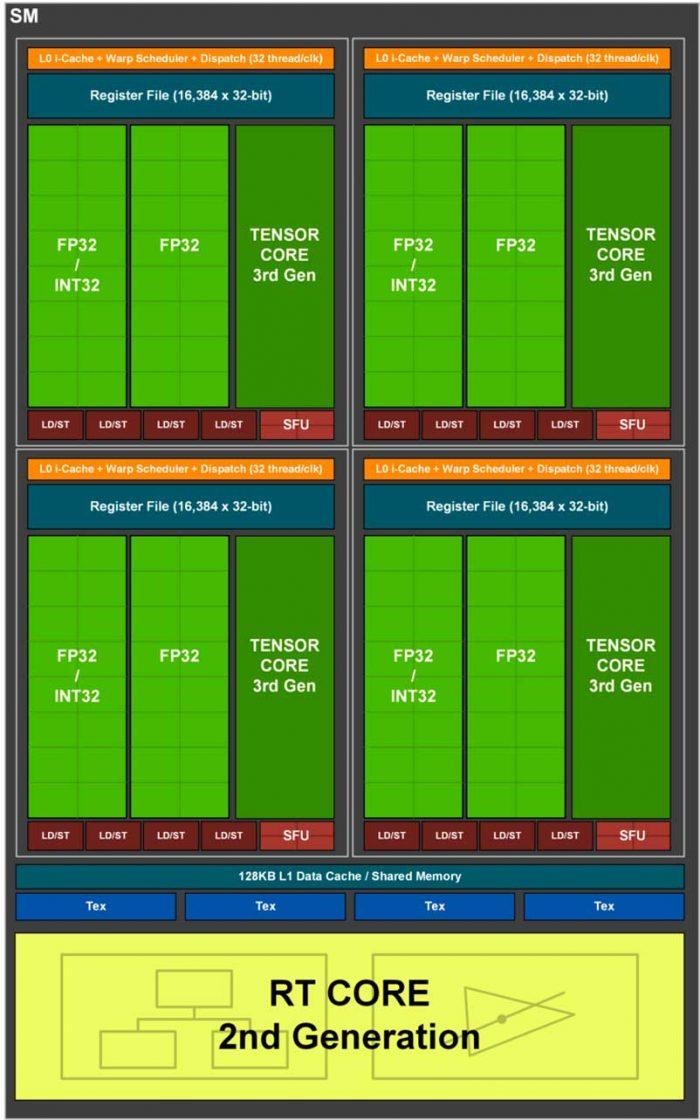
Esto supondría una mejora en Ray Tracing sorprendente y la acercaría a un renderizado puro que es lo que se busca, pero implica al mismo tiempo un cambio muy profundo en los SM que afectaría a los TMUs y posiblemente a los ROPs realmente, no tanto en número, sino en estructura, jerarquías y por supuesto a su rendimiento. Dado lo hermético que se ha vuelto NVIDIA, habrá que esperar casi a la presentación para ver si vamos bien enfocados en este tema.