
Uno de los detalles que más ha llamado la atención tras las presentaciones de las NVIDIA RTX 3000 ha sido el hecho de su rendimiento en FP32. Hasta ahora, la progresión en los llamados Shaders TFLOPS de NVIDIA había sido escalable en mayor o menor medida, pero con Ampere esos números se han duplicado, y han hecho saltar las alarmas de muchos usuarios que siguen con la idea de que el rendimiento FP32 es sinónimo de veracidad para comparar arquitecturas. ¿Por qué está ocurriendo esto?
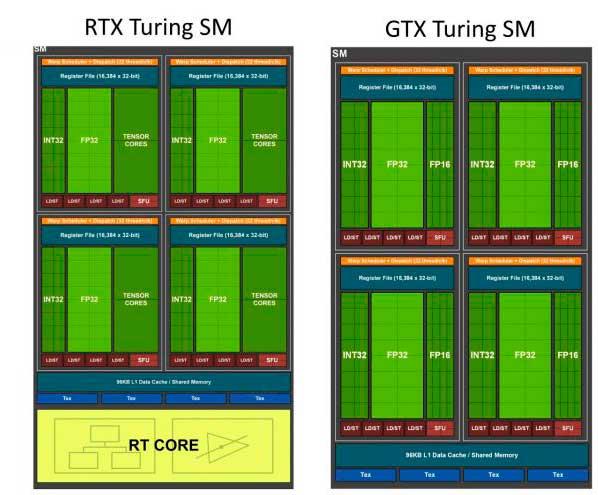
La explicación tiene mucho que ver con uno de los cambios fundamentales de la arquitectura y que NVIDIA ha denominado como 1/2 FP32 rate. Dicha denominación no viene de ahora, sino desde la arquitectura Turing y sus SM, donde como bien sabemos se separaron enteros de flotantes y esto dio como resultado la capacidad de incluir tres motores distintos, pero con algunos inconvenientes.
La tasa de FP32 Shaders TFLOPS está directamente relacionada con el recuento de CUDAs
De manera «mágica» (nótese la ironía) NVIDIA ha decidido de forma unilateral duplicar el conteo de Shaders en sus tarjetas gráficas Ampere. Una acción de marketing que aun así tiene un pequeño fundamento que enlaza inexorablemente con los datos de rendimiento en Shaders TFLOPS.
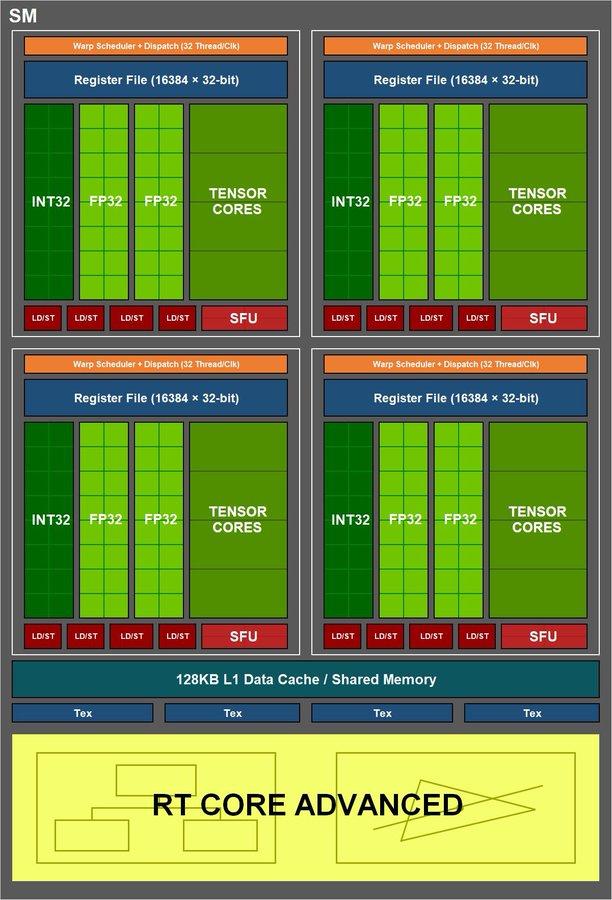
Para entender todo, hemos de partir de la base de Volta como arquitectura, ya que fue la pionera en el 1/2 FP32 del que habla NVIDIA y que arrastró a Turing al mismo cometido. En ambas arquitecturas cada SM era capaz de ejecutar 1 paquete de 32 instrucciones por clock, las cuales se tenían que dividir forzosamente en 16 operaciones para FP32 y 16 operaciones para INT32, o lo que es igual, 16 instrucciones para punto flotante y 16 para números enteros por cada ciclo de reloj.
¿Por qué hacerlo así? Pues porque en primer lugar a NVIDIA le rentaba como arquitectura general el hecho de que hubiese menos operaciones de FP32 si a cambio dividía el renderizado de cada frame en los comentados tres motores para poder trabajar con Ray Tracing o DLSS.
Dicho de otra manera, sacrificó capacidad de FP32 por INT32 a cambio del mayor salto de arquitectura en 10 años, sabiendo que dicho cambio repercutía en una ligera ventaja de rendimiento por cada SM y a parte le daba la capacidad de trabajar con algoritmos BVH e IA para los juegos.
Ampere vuelve a poner las cosas en su sitio
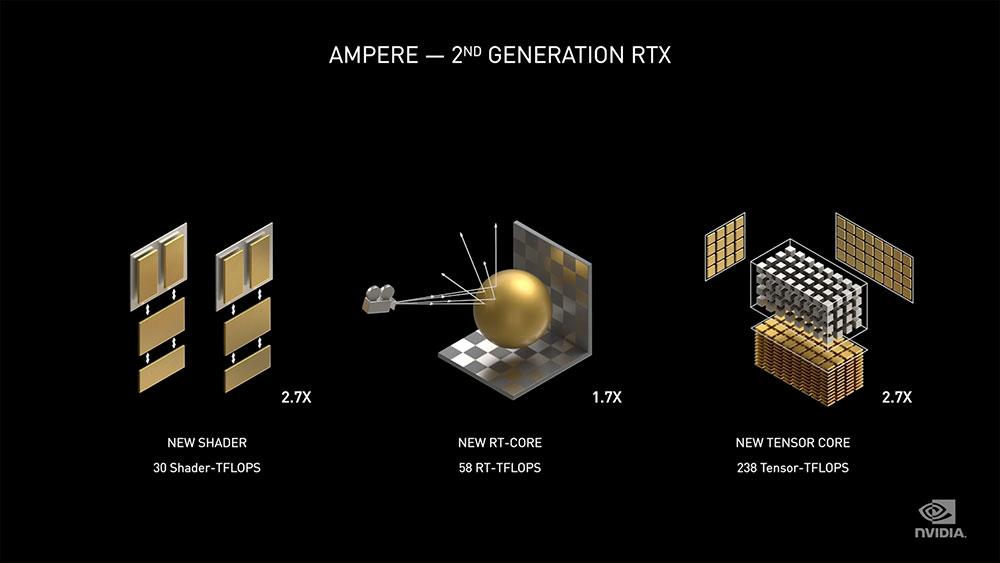
Con las RTX 3000 y la arquitectura Ampere, NVIDIA rompe con ese 1/2 FP32 y vuelve a ejecutar 32 operaciones FP32 por cada clock dentro de los SM (podríamos hablar de 4 motores en vez de tres, al menos de forma teórica), por lo que bajo la lupa y óptica de la compañía esto es «mágicamente» duplicar el número de Shaders totales en las especificaciones, pero la realidad es que esto no funciona realmente así, ni mucho menos, ya que NVIDIA solamente ha duplicado una parte de los motores, dejando al resto intacto, por lo que el rendimiento no será el equivalente a multiplicar por dos el número de shaders.
- RTX 3090-> 10496/2 = 5248
- RTX 3080 -> 8704/2 = 4352
- RTX 3070 -> 5888/2 = 2944
El número de Shaders real de las tres tarjetas de referencia a día de hoy de NVIDIA es justamente la mitad y esto influye a la hora de calcular lógicamente su rendimiento teórico en FP32. Incidimos en teórico, puesto que ya hemos visto la farsa que representa este valor a la hora de comparar rendimientos en especificaciones frente al rendimiento real.
Así que dicho esto, vamos a explicar cómo es posible que NVIDIA haya duplicado su rendimiento tan mágicamente.
De duplicar su rendimiento en FP32, a solo poder marcar un «pequeño» margen

Si miramos las especificaciones oficiales de NVIDIA, la RTX 3090 obtiene un rendimiento FP32 de 35,58 TFLOPS, o como ellos lo denominan: Shader TFLOPS. Esta cifra es muy fácil de calcular y evidencia el terrible error de comparar TFLOPS como medida estándar entre cualquier componente de hardware:
Shaders x frecuencia x 2 operaciones por ciclo x 1 GPU
En el caso de la RTX 3090 pues obtendremos 10.496 x 1.700 x 2 x 1 -> 35.686.400 FLOPS o 35,686 TFLOPS (suponiendo una eficiencia en la arquitectura del 100%, algo imposible en cualquier chip). Lógicamente este valor es totalmente irreal por lo comentado anteriormente, y ni mucho menos refleja una superioridad frente a una RTX 2080 Ti de casi tres veces su rendimiento.
El número correcto en TFLOPS sería 17,843 TFLOPS, o lo que es igual, un 32,66% más de rendimiento en punto flotante que una RTX 2080 Ti. Pero esta diferencia solo hace referencia a FP32 y deja de lado el rendimiento en INT32, por ejemplo.
Lo que hemos visto hasta ahora es que la diferencia de rendimiento está entre un 24% y un 29% aproximadamente y según la resolución escogida, pero como vemos está muy lejos del marketing que ha intentado instaurar la compañía y que por desgracia va a terminar imponiéndose con sus Shaders TFLOPS.