AMD muestra cómo conectará sus chiplets en GPU: llega Last Level Cache

No se puede clasificar ni como secreto, puesto que todo el mundo está a la que salta, pero AMD va a ir directamente a por el mercado gráfico en una o dos generaciones más, como muy tarde. Lo revelado hoy es del jueves pasado y muestra una patente registrada dicho día 1 donde los de Lisa Su ya tienen planificado cómo conectar chiplets: llega Unified Last Level Cache.
Los chiplets son el futuro tanto de CPUs como de GPUs, donde el problema como ya sabemos son las interconexiones entre estos y los recursos que AMD, Intel y NVIDIA dejen para compartir entre ellos. La patente intenta explicar cómo AMD lanzaría un recurso de memoria compartida de último nivel que a su vez estaría unificada para todos, un diseño muy similar a lo que vimos en Zen 3.
Una arquitectura unificada, compartida y modular: Unified Last Level Cache
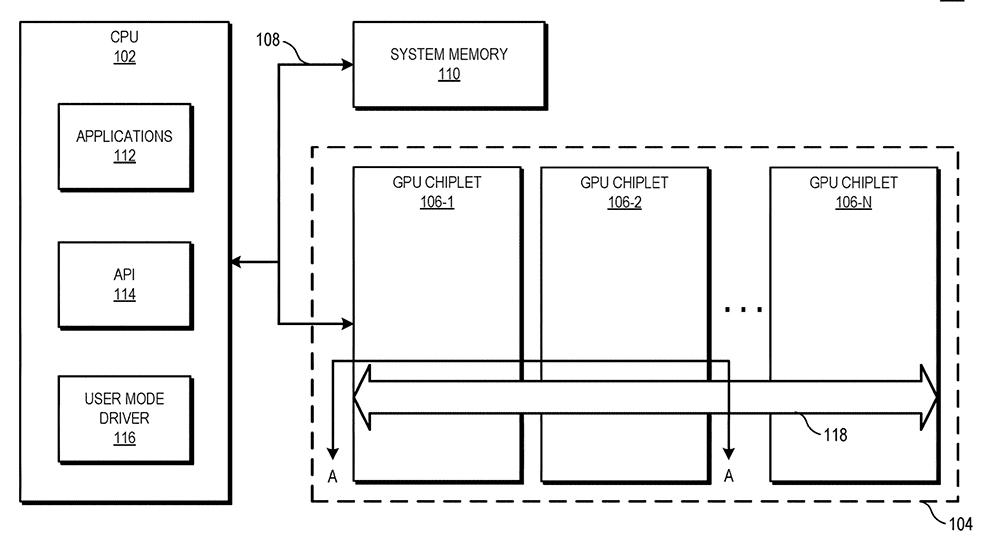
En los detalles está lo importante y aunque la explicación de arriba resume lo que los de Lisa Su planean, lo cierto es que si miramos bien la patente esta deja abierta la posibilidad a un número «N» de chiplets. Esto es importante, porque supone que esta nueva tecnología será la piedra angular de un proyecto de futuro que da por sentado que el número de chiplets irá en aumento conforme los nodos lo permitan.
Sin embargo, hay un concepto que no está totalmente definido: Primary GPU Chiplet. Según se ve en las diapositivas, serán los datos cacheados los que determinen y van al «Active Bridge Chiplet» o al «Caching Chiplet» dando a entender que al igual que pasa en las arquitecturas Zen tendríamos un supuesto I/O die llamado Bridge Active Chiplet.
Es este el que reparte las tareas para los chiplets de la GPU mediante sus canales de memoria y mediante la Unified Last Level Cache. Es decir, en vez de tener cachés de chiplets independientes como si de núcleos de CPU con su caché L1 y L2 se tratase, AMD con este chiplet específico actuaría como una caché monolítica.
Memoria direccionable, una única caché de último nivel y registros
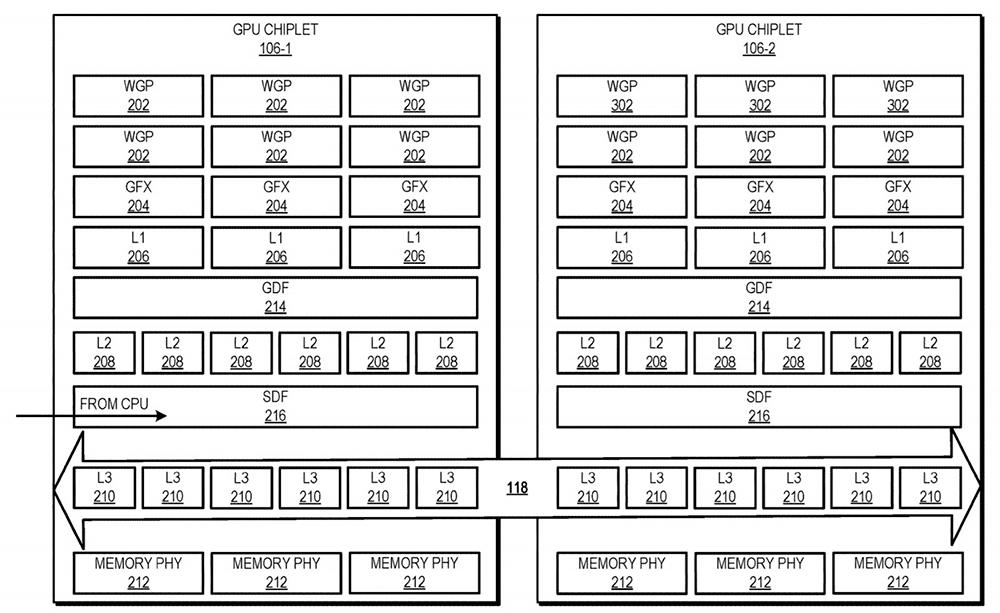
La jugada parece bien marcada: no hacer que los programadores tengan que cambiar todo su software y manera de trabajar para compilar las cargas a los chiplets de manera individual. Al contrario, con esto los desarrolladores no tienen que tener en cuenta si hablamos de 1, 2 o 20 chiplets, ya que es el Active Bridge Chiplet el encargado de repartir las cargas y el trabajo.
Por lo tanto LLC sería como una especie de L3 al más puro estilo Infinity Cache, así que no sabemos si esta se mantendrá o cambiará su función o simplemente adopta un nuevo enfoque manteniendo su esencia.
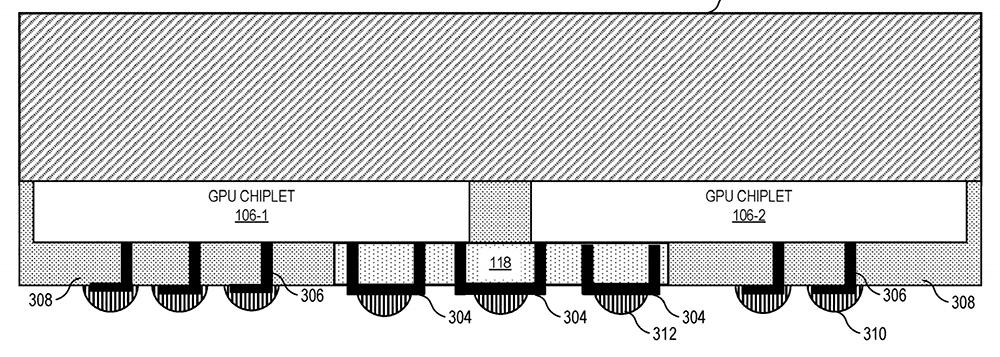
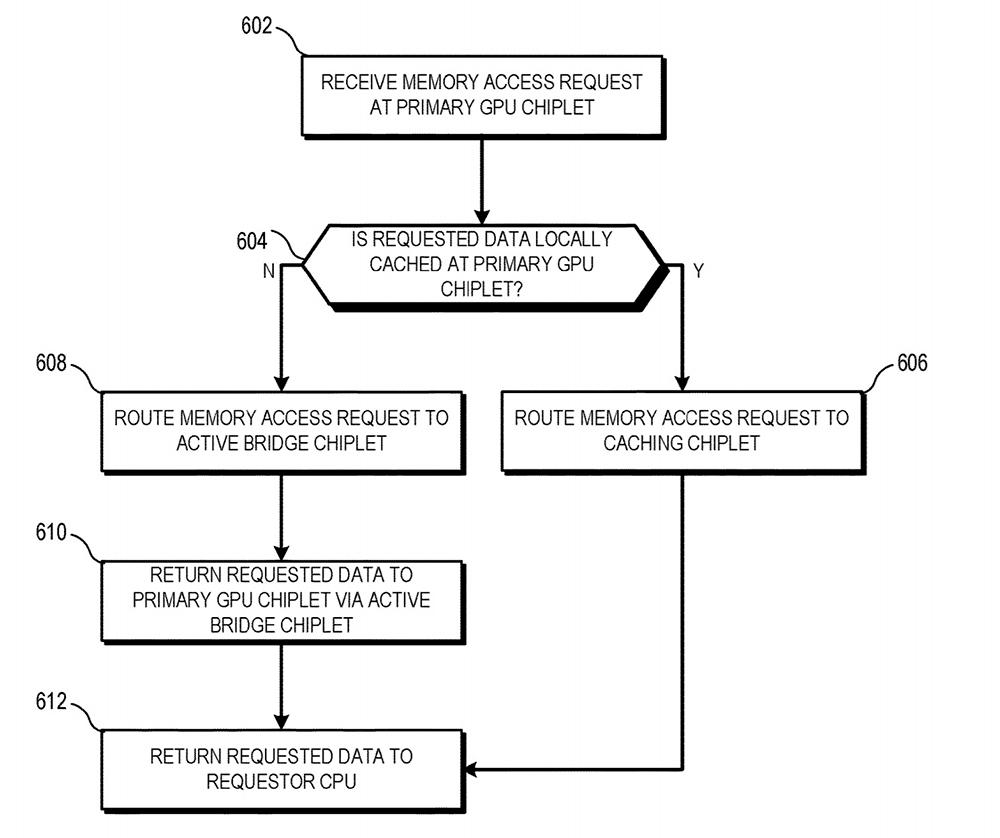
En cualquier caso, AMD va a por el mercado de tarjetas gráficas, ahora falta saber si estamos ante un golpe para los centros de datos e IA, para las GPUs gaming o para ambos como pieza fundamental del diseño de chiplets dentro de la compañía.
Lo que sí sabemos vistas las patentes de enero es que el diseño está muy avanzado y aunque estas patentes sean simples diagramas, el trabajo en la mesa de diseño está finalizado, así que no deberían tardar demasiado en comenzar con las pruebas reales para estos diseños, si no están ya en ello …