
Intel no puede seguir durmiéndose en el mercado de las CPU y aunque la respuesta está en camino, como vimos ayer no llegará en 2020. Será a partir de 2021 cuando la compañía ponga toda la carne en el asador con sus 10 nm++ para sus nuevas arquitecturas, de las cuales hoy conocemos otro dato muy relevante: incluirán mejoras en sus cachés (CLDEMOTE) que podrían incidir en la distancia de rendimiento que las separa de la memoria RAM, ¿serán necesarios módulos más rápidos?
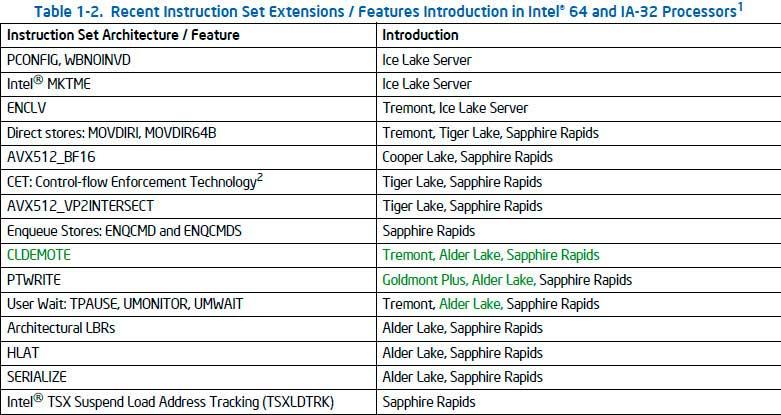
Lo revelado corresponde a documentación oficial de la propia Intel para la 39 edición de la referencia de las extensiones ISA, donde el usuario InstLatX64 ha sido el descubridor del hallazgo. En dichos documentos hay un apartado que hace referencia a los sets de instrucciones extendidas recientes así como características para los nuevos procesadores Intel 64 con IA-32, donde a cada set se le asignan una serie de arquitecturas dando a entender que las soportarán.
La novedad radica en un set concreto muy interesante que afecta a la caché y sus distintos niveles y que tendrá soporte para Tremont, Alder Lake y Sapphire Rapids, donde es posible que tengamos que aumentar la frecuencia de la RAM para conseguir mucho más rendimiento en la CPU.
Intel CLDEMOTE, nuevo conjunto de instrucciones para optimizar la caché
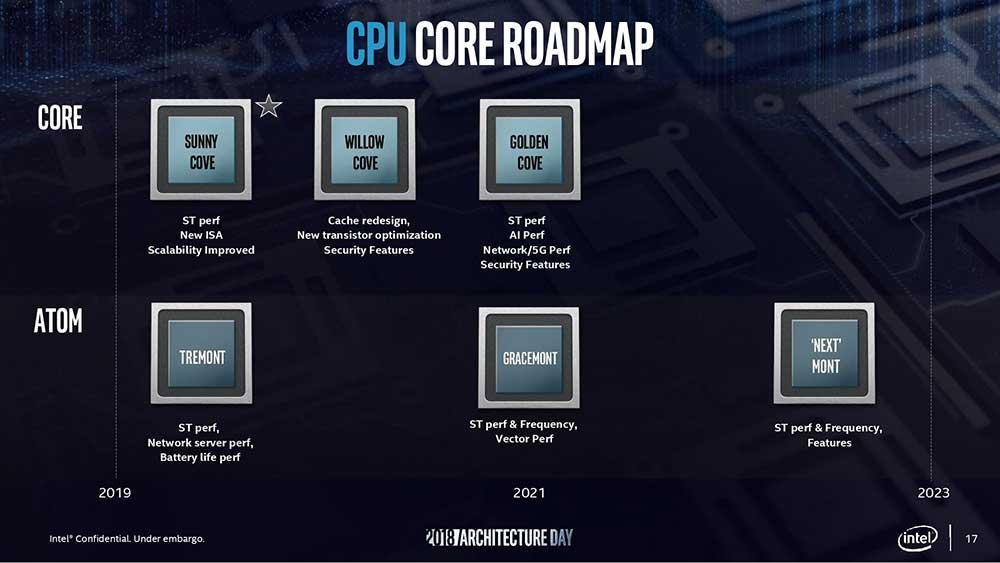
Como ya dejó entrever Intel, en sus nuevas arquitecturas tendríamos una serie de cambios que maximizarían el rendimiento y harían despegar el IPC de sus procesadores. Parece que una de estas características lleva tiempo lista y como está «oculta» entre cientos de Whitepaper apenas nadie se había percatado de su existencia, ya que los primeros datos parecen confirmar que ha estado a la vista de todos desde octubre de 2018.
En cualquier caso, hasta ahora no era posible asignarla a una o varias arquitecturas en concreto, por lo tanto ya sabemos cuando llegará al mercado según el último roadmap de la propia Intel. El set de instrucciones en concreto se hace llamar CLDEMOTE y llega como una mejora en lo que se denomina «instrucción de sugerencia de cachés».
Según parece, es un cambio bastante importante en la filosofía de Intel para el diseño de sus instrucciones y tendrá un impacto en el rendimiento considerable. Su función principal es extremadamente simple de comprender, pero muy complicado de ejecutar en la práctica: intentará mover ciertas líneas de caché de datos desde las cachés más cercanas de los núcleos hacia las más alejadas de los mismos.
Es decir, intentará optimizar el rendimiento de caché a caché mediante moviendo los datos a la L3 en vez de estar en L2 o L1, mejorando las intervenciones de estas dos últimas con los núcleos.
Control, pros y contras de este set de instrucciones
Como todo set de instrucciones se necesitan una serie de métodos que garanticen su funcionamiento:
- Se necesita una transacción de caché que garantice su corrección.
- Se tiene que garantizar la escritura de las cachés en la memoria volátil.
Esto al parecer va a crear un pequeño problema si queremos extraer el máximo rendimiento del set: aumenta la brecha de rendimiento que ya existe entre el procesador y la memoria, haciendo al primero más dependiente del rendimiento de su caché.
A cambio, al mover las líneas de caché menos óptimas de los niveles L1 y L2 a las L3 se consigue un mayor movimiento de carga entre núcleos y con ello se optimiza su rendimiento, ya que las L3 son compartidas.
Además, desde el punto de vista de la jerarquía de cachés se aumenta la complejidad y con ello el costo de los procesadores podría aumentar por sus mayores gastos en I+D. Por último, los tiempos de acceso de la memoria RAM así como su velocidad para incorporar datos a las cachés va a ser más determinante que nunca.
Es posible que veamos un salto de rendimiento similar a lo visto con los Ryzen, donde la frecuencia y la latencia de las memorias RAM es clave para impulsar al sistema. La ventaja es que no contaría con los problemas de tiempos de acceso de AMD, pero igualmente se podrían requerir memorias muy rápidas para potenciar las ventajas de este set de instrucciones, lo cual podría desembocar en un salto de rendimiento del IMC bastante importante por parte de Intel.