
La entrada de la marca azul al mercado de las tarjetas gráficas es algo que es un hecho y no para una sola generación, sino para varias distintas. Es decir, existe un Roadmap de GPU Intel, el cual consiste en una serie de arquitecturas gráficas que aparecerán durante los años siguientes para competir contra NVIDIA y AMD. Veamos, por tanto, que es lo que sabemos y que podemos esperar.
Por el momento Intel ha anunciado ni más ni menos que cuatro generaciones distintas de tarjetas gráficas o al menos cuatro gamas de productos sucesivas para los próximos años. Las cuales son Alchemist, Battlemage, Celestial y Druid. De todas ellas de las que conocemos más datos por el hecho que su lanzamiento debería producirse en algún punto de 2022 es de Alchemist, pero del resto sabemos más bien poco, excepto que son el nombre de la arquitectura que viene a continuación.

Lo que sí que sabemos es la nomenclatura de cada generación, por ejemplo todos los modelos Alchemist recibirán el nombre de ARC Axx como por ejemplo ARC A380, mientras que los modelos con arquitectura Battlemage serán Bxx y los Celestial Cxx. Cómo se puede ver es una forma lógica de darle nombre a cada gama de productos que pese a ser poco imaginativa difiere de lo habitual en la forma de nombrar los productos.
Sin embargo, los mapas de ruta suelen ser en parte engañosos o sufrir cambios a mitad de los mismos, ya sea en modo de cancelaciones de productos y adelantamientos de otros. Es por ello que hemos decidido hacerle un repaso no solo al roadmap de Intel en GPU, sino que lo hemos intentado cuadrar con las diferentes informaciones que nos van llegando.
El Roadmap de las GPU Intel ARC y su arquitectura

La arquitectura ARC Alchemist de Intel no difiere mucho de lo ofrecido por la competencia. Simplemente, al igual que también ocurre con AMD y NVIDIA tenemos el uso de significantes distintos para unidades con la misma funcionalidad o similar. Por lo que vamos a ser escuetos en esto nos vamos a centrar en lo importante.
El objetivo de Intel es llegar a capturar la mayor cuota de mercado posible y para ello no van a ir a la yugular de su rival en CPU, lo que quieren es ir en contra de NVIDIA y es por ello que sus Alchemist están pensadas para competir de tú a tú con las RTX 30. Por lo que si comparamos unidad por unidad nos encontraremos cosas cómo una unidad Ray Tracing muy similar y superior a la de AMD con capacidad para recorrer el árbol BVH por hardware. El equivalente a los Tensor Core que no se encuentra en las Radeon sí que se encuentra en las ARC Alchemist y el número de ALU por unidad shader es de 128 en vez de 64.
Por lo que la primera generación de las Intel ARC es más bien una primera entrada que poco o nada dice la ambición de Intel y sus futuros planes. Una simple carta de presentación en un mercado dominado hasta el momento por el duopolio AMD y NVIDIA.
El desarrollo de Ponte Vecchio es clave

De la GPU para computación de alto rendimiento llamada Ponte Vecchio sabemos dos cosas: la primera de ellas es que no aparecerá en PC, puesto que se trata de un diseño para superordenadores y sistemas de computación de alto rendimiento. No obstante hay varios conceptos que vamos a ver en el Roadmap de las GPU de Intel. Aunque el más importante es que el conocimiento acumulado para el desarrollo del mismo es lo que les va a permitir desplegar las próximas generaciones de manera muy rápida en comparación con la competencia. En palabras del arquitecto en jefe, Raja Koduri, nos podemos esperar el uso de la misma unidad tanto en CPU como en GPU.
Meteor Lake será una nueva arquitectura que permitirá que las GPU por tiles (o chiplets) sean integradas en empaquetado 3D. Esto es algo muy excitante que nos permitirá ofrecer rendimiento de tarjeta gráfica dedicada con la eficiencia de gráficos integrados.
Una de las cosas que utiliza Ponte Vecchio son las nuevas tecnologías de empaquetado 3D y de puentes de silicio de Intel. Estamos hablando de Foveros y EMIB, los cuales serán claves para hacer realidad el roadmap de las GPU Intel ARC usando varios tiles o chiplets en vez de un chip monolítico o de una sola pieza. No serán los únicos, pero tienen más camino hecho que la competencia.
La importancia del nodo de 3 nm de TSMC en el roadmap de Intel

El acuerdo entre Intel y TSMC donde la segunda construirá las Tile GPU tanto para sus gráficas cómo para sus procesadores les va a permitir a los de Pat Gelsinger aprovechar el nodo de 3 nm de los taiwaneses mucho antes de que lo hagan NVIDIA o AMD. ¿El motivo? El pequeño tamaño de cada tile es clave para poder desplegar rápidamente las diferentes generaciones de las GPU ARC. No obstante la Tile GPU desarrollada para Ponte Vecchio no es lo suficientemente potente como para hacer frente a la RTX 4090 en cuanto al número de ALU en FP32.
Por lo que Intel ha decidido aprovecharás su acceso privilegiado al nodo de 3 nm para crear una Tile GPU de mayor potencia de cálculo que la de Ponte Vecchio con el objetivo de ofrecer una GPU tope de gama con una potencia mucho más alta que la que puede obtener NVIDIA con la RTX 4090 Ti. Para ello lo que harán será montar las mismas GPU Tile de Meteor Lake y Arrow Lake. La diferencia es que las GPU dedicadas harán uso de configuraciones de 2, 4 y quien sabe si 6 y hasta 8 tiles en una misma GPU.
No podemos dar cifras oficiales, pero se habla de configuraciones de «320 EU» por Tile GPU a 3 nm en el Roadmap de Intel, lo que se traduce en 2560 ALU FP32 en la configuración de 1 solo tile, lo que le permitiría a Intel tener una GPU de más de 20.000 «cores» en la gama alta; sin embargo, por el momento no sabemos si la vamos a ver como Battlemage o Celestial. En todo caso el nombre es lo menos importante de todo.
¿Cómo pretende Intel unir varias GPU distintas en una sola?
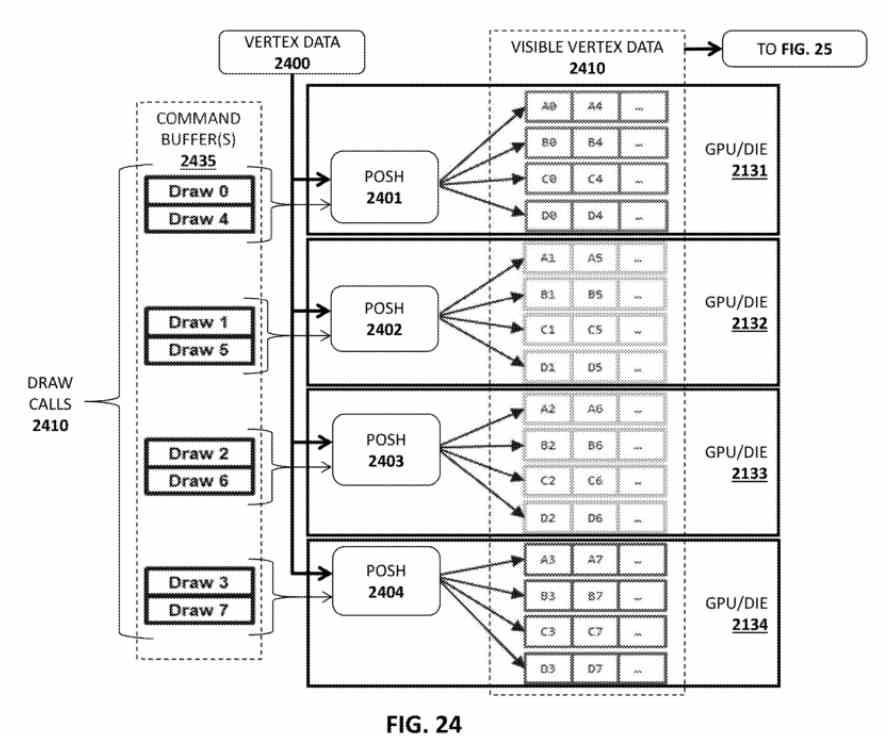
Aquí entramos en un tema que es sumamente interesante, las GPU en escritorio suelen dibujar con una sola lista de pantalla por fotograma, por lo si utilizamos varias de ellas tenemos tres soluciones:
- Alternar fotogramas, lo que significa que la CPU tendrá que tener ya preparados la lista de pantalla de los fotogramas siguientes. Se llega al punto en que no se puede hacer esto y no se puede escalar en GPU.
- Dividir el fotograma en varias partes de la pantalla, el problema es que toda la generación de la escena hasta el rasterizado no se hace a nivel de pantalla, sino de geometría del mundo, por lo que la hace una sola GPU.
La idea de Intel para sus futuras GPU es sencilla de entender, primero se renderiza la escena con un único Tile GPU, pero sin aplicar programas shader a ninguna primitiva gráfica y tampoco texturas para saber así donde se encontrará cada polígono de la escena desde el principio, saber cuáles no serán visibles y se tendrán que descartar, especialmente para crear listas de pantalla para renderizar la escena para orientadas a cada espacio de la misma y, por tanto, hacer que cada tGPU renderice su propia parte de la escena.
Se trata ni más ni menos que adoptar las mismas soluciones que el Tile Rendering, pero con la diferencia que el ordenamiento de la geometría se realiza antes del renderizado final de la escena. El pre-renderizado para crear la lista se hace vía el pipeline de computación, lo que permite el uso de varias Tile GPU en paralelo desde el principio.