Chips modulares como solución a la Ley de Moore: así es el prototipo RC-18 de NVIDIA
El futuro de las GPUs para por adaptarse a los tiempos que corren, donde la idea de un chip monolítico está perdiendo cada vez más fuerza, impulsado por otro lado por unos menores costes y una mayor escalabilidad. Siendo conscientes de esto, NVIDIA ha revelado uno de sus proyectos y chips estrella aún en desarrollo al que han llamado internamente RC-18: un concepto de implementación de múltiples matrices.
La solución a la Ley de Moore en GPUs pasa por el mismo camino que en CPUs
A tenor de lo presentado en el GTC organizado por NVIDIA y de la mano de Bill Dally (Jefe de la División de Investigación de los de Huang), la marca ha dejado ver y conocer uno de sus proyectos estrella para un futuro cercano, algo extraño y que no es muy común que realicen, todo sea dicho.
Según Dally, el prototipo es un experimento para realizar y lograr la escalabilidad para el Deep Learning, al que llamaron internamente RC 18, y el que puede ser ampliado desde un tamaño muy pequeño. Este chip en concreto tiene 16 PE (Process Elements) dentro de cada troquel, por lo que es relativamente pequeño, ya que solo porta 87 millones de transistores en un proceso litográfico como son los 16 nm de TSMC.
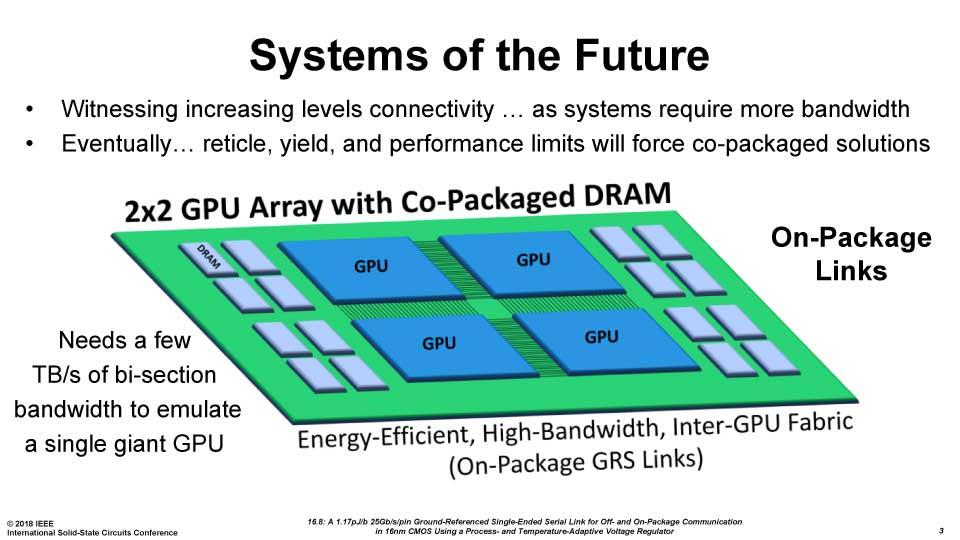
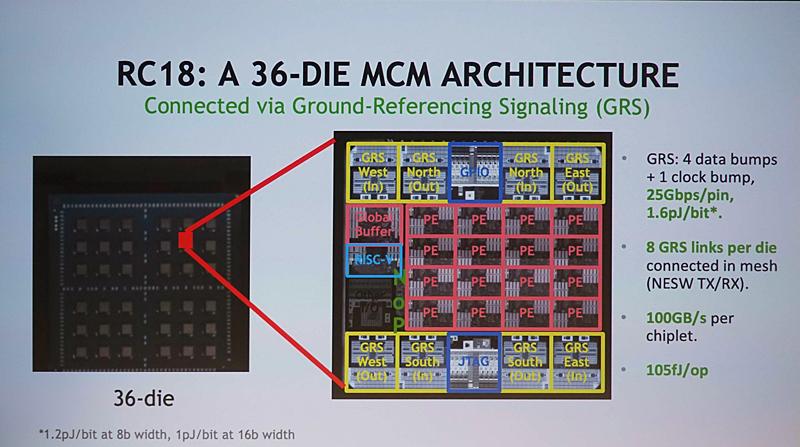
Es un chip totalmente MCM en el que se pueden interconectar, de momento, hasta 36 dies en un sustrato orgánico y se espera que pueda ser mucho más escalable.
Según Dally, este chip en desarrollo e investigación tiene la ventaja de poder demostrar muchas tecnologías al mismo tiempo para el aprendizaje profundo, donde una de ellas es precisamente la escalabilidad que puede conseguir.
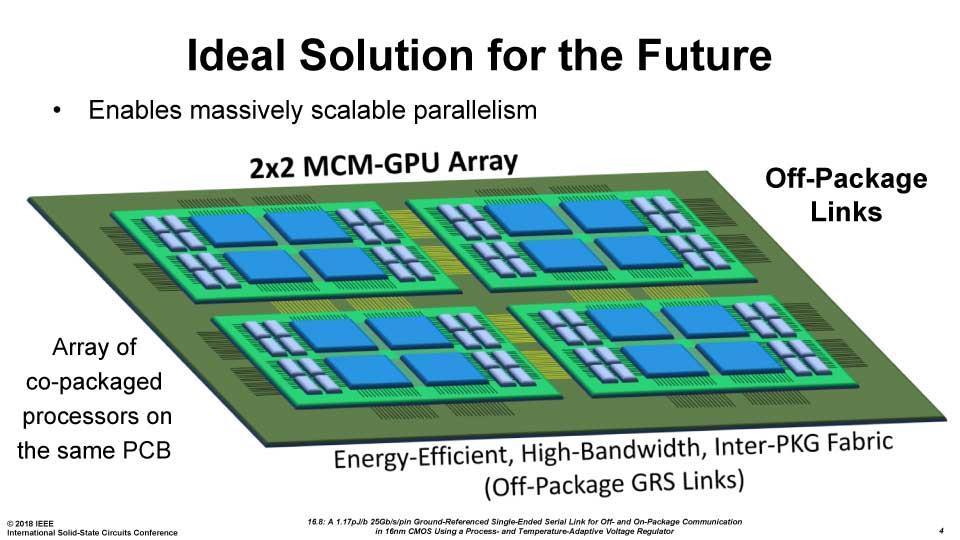
Otra de esas ventajas es ser capaz de conseguir una matriz para los dies muy eficiente en un sustrato orgánico que mejore las tecnologías de transmisión actuales, lo cual es básico si finalmente esta tecnología se implementa en dies o grupos de dies de alto rendimiento.
Arquitectura de RC 18
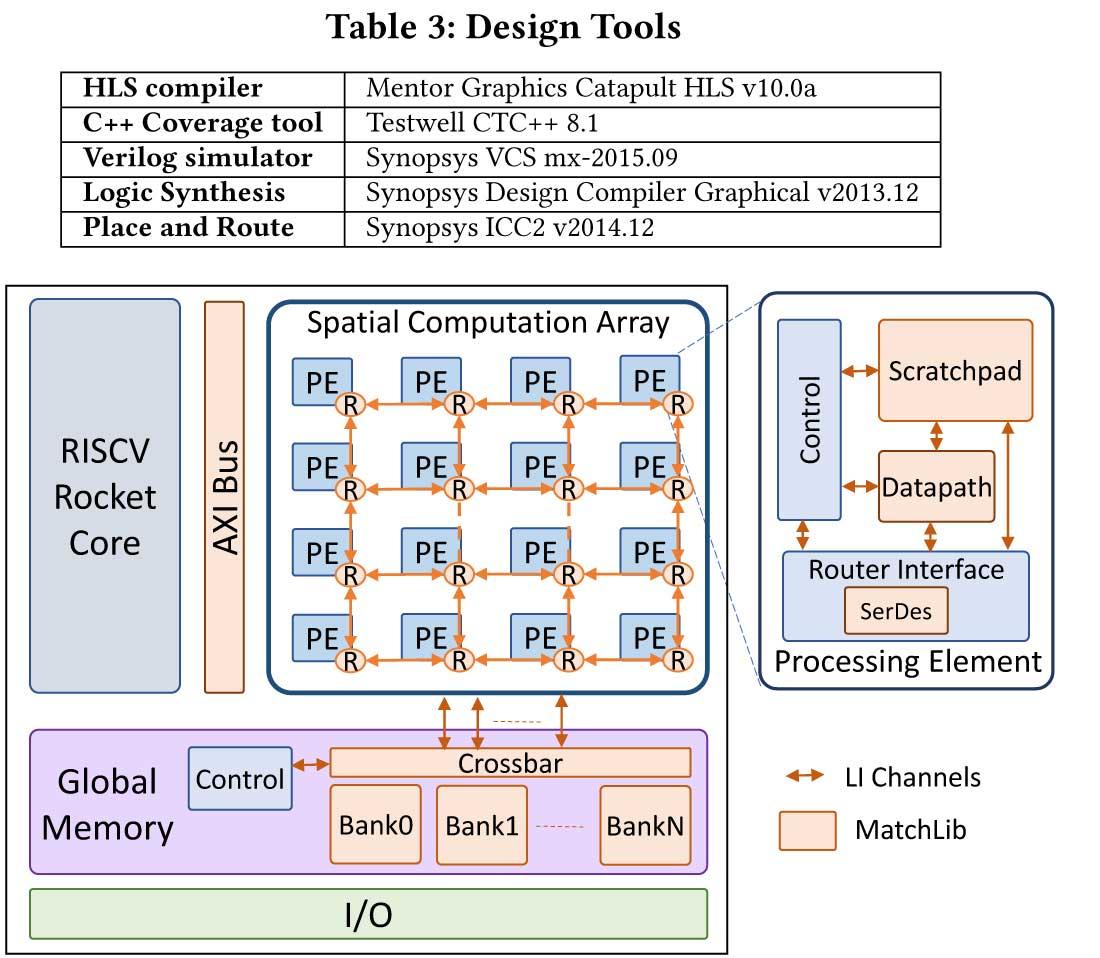
Como ya hemos comentado, este chip se basa en los 16 nm de TSMC y contiene solo 87 millones de transistores en 16 PE, pero además incluye un núcleo de control, una memoria intermedia global y ocho enlaces de señalización o GRS (100 GB/s por chiplet).
Los 16 PE están en una matriz de 4×4, estando compuestos cada uno de una unidad de procesamiento, una memoria global, una unidad de control y un enrutador, además de estar conectados mediante una interconexión NoC (Network-on-Chip). Como novedad, el llamado RISCV Rocket Core está conectado al array de PE mediante un bus AXI, el cual ya ha sido visto en otros proyectos como EyeRiss.
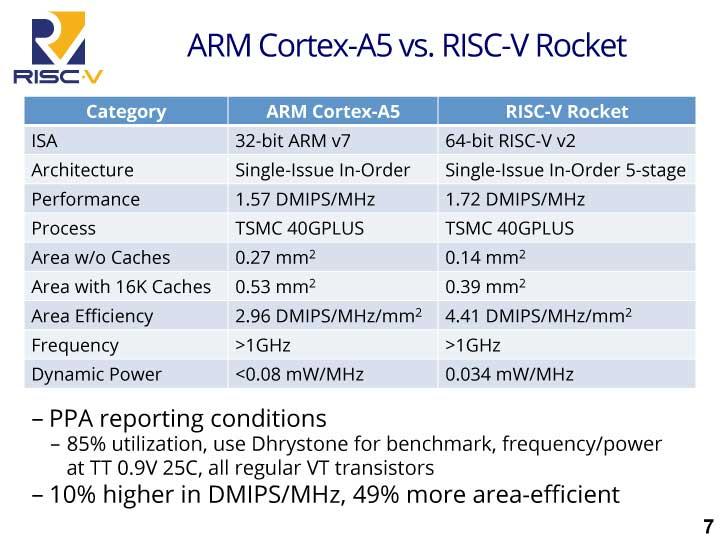
Dicho núcleo Rocket es un procesador ARM Cortex-A5 de 64 bits con Single-Issue In-Order 5-stage como pipeline y está diseñado para iniciar cada PE configurando el registro de control mediante el controlador global, minimizando el impacto de la latencia que se genera en el compilador-generador de las RAMs.
Aunque es un chip ARM, el diseño de NVIDIA logra aumentar el rendimiento un 10% en DMIPS/MHz siendo un 49% más eficiente por área.

Para finalizar, Dally dijo que la dirección de NVIDIA en estos momentos es aumentar la productividad del diseño mediante la introducción paulatina de chips grandes y más complejos con un menor esfuerzo. Estos intentos lograrían reducir el tiempo de diseño futuro y aumentar la variedad de productos o gamas.
Parece claro que esta tecnología irá, en un primer momento, a los centros de datos, pero según lo que hemos visto en el pasado esto terminará implementándose en las GPUs para gaming a corto plazo y con el consecuente nuevo enfoque.