
El DLSS es una de las puntas de lanza de NVIDIA frente a AMD, los juegos que lo soportan pueden alcanzar mayores tasas de fotogramas a resoluciones de salida donde sin el uso de esta técnica no sería posible. Este hecho ha sido el que ha convertido a las GPUs de las gamas RTX de NVIDIA en las actuales líderes del mercado de las GPUs, pero el DLSS de NVIDIA tiene trampa y os vamos a contar cuál es.
Si tenemos que hablar de las dos puntas de lanza de NVIDIA para sus GeForce RTX está claro que son el Ray Tracing y el DLSS, el primero ha dejado de ser ventaja por la implementación en las RDNA 2 de AMD, pero el segundo sigue siendo un elemento diferencial que le da una gran ventaja, pero no todo es lo que parece a primera vista.
El DLSS en las RTX depende de los Tensor Cores
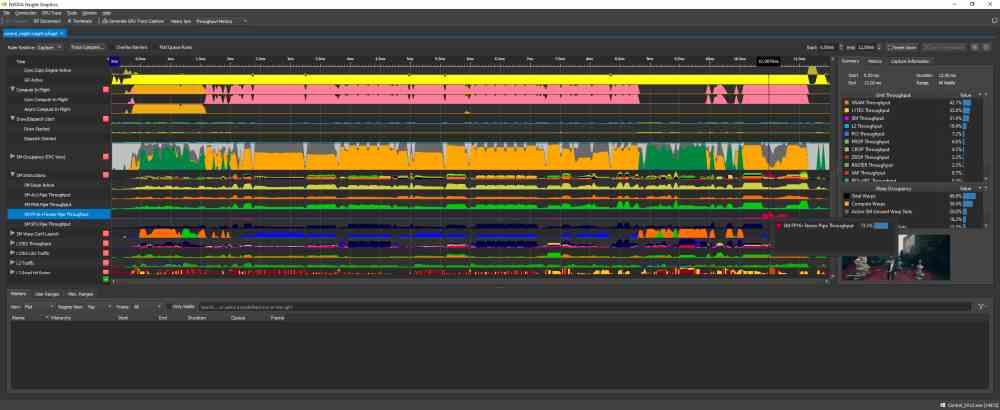
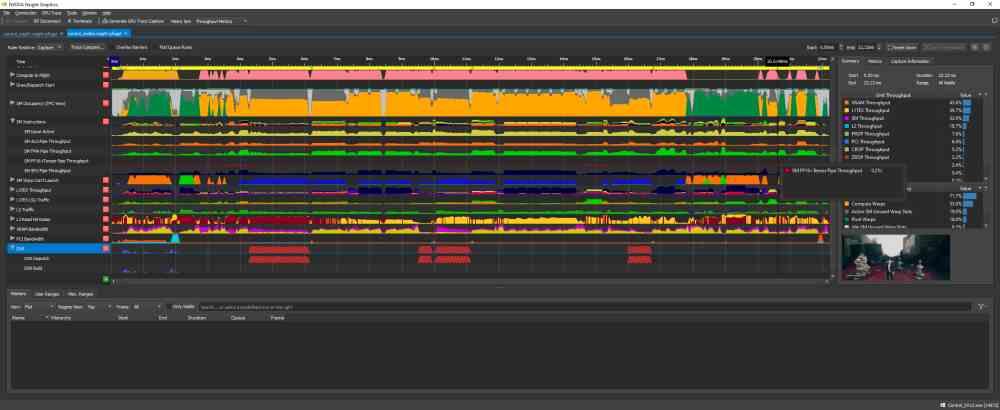
Lo primero que tenemos que tener en cuenta es como los diferentes algoritmos, llamados comúnmente DLSS, aprovechan el hardware de la consola y nada mejor que hacer un análisis del funcionamiento de la GPU mientras está renderizando un fotograma con el DLSS activo y sin este.
Las dos capturas de pantalla que tenéis arriba de estas imágenes corresponden al uso de la herramienta NVIDIA NSight, la cual mide el uso de cada una de las partes de la GPU a través del tiempo. Para interpretar las gráficas hemos de tener en cuenta que el eje vertical corresponde al nivel de uso de esa parte de la GPU y el eje horizontal el tiempo en el que se renderiza el fotograma.
Como se puede ver, la diferencia entre ambas capturas de pantalla del NSight es que en una de ellas se puede ver el nivel de uso de cada parte de la GPU al utilizar el DLSS y en la otra no. ¿Cuál es la diferencia? Si no fijamos bien veremos que en la correspondiente al uso del DLSS la gráfica correspondiente a los Tensor Cores esta plana excepto al final de la gráfica, que es cuando estas unidades se activan.
El DLSS no es otra cosa que un algoritmo de superresolución, que toma una imagen a una resolución de entrada determinada y saca en el proceso una versión de la misma imagen a más resolución. Es por eso que los Tensor Cores al aplicarlo se activan al final, ya que requieren que la GPU renderice la imagen primero.
Funcionamiento del DLSS en las NVIDIA RTX

El DLSS toma hasta 3 milisegundos del tiempo para renderizar un fotograma, independientemente de cuál sea la velocidad de estos a la que funciona el juego. Si por ejemplo queremos aplicar el DLSS en los juegos a una frecuencia de 60 Hz, entonces la GPU deberá resolver cada fotograma en:
(1000 ms/60 Hz) -3 ms.
Dicho de otra manera, en 13.6 ms, a cambio vamos a obtener una tasa de fotogramas más alta en la resolución de salida que obtendríamos si pusiéramos a renderizar a la GPU de manera nativa dicha resolución de salida.

Suponed que tenemos una escena que queremos renderizar a 4K. Para ello tenemos una GeForce RTX indeterminada que a dicha resolución alcanza los 25 fotogramas por segundo, por lo que renderiza cada uno de estos a 40 ms, sabemos que la misma GPU puede alcanzar a 1080p una tasa de fotogramas de 5o, 20 ms. Nuestra hipotética GeForce RTX tarda unos 2.5 ms en escalar de los 1080p a los 4K, por lo que si activamos el DLSS para obtener una imagen 4K a partir de una a 1080p entonces cada fotograma con DLSS tardará 22.5 ms. Con ello hemos obtenido renderizar la escena a 44 fotogramas por segundo, lo cual es mayor que los 25 fotogramas que se obtendrían renderizando a resolución nativa.
Por otro lado, si la GPU va a tardar más de 3 milisegundos en hacer el salto de resolución entonces el DLSS no se activará, ya que es el límite de tiempo marcado por NVIDIA en sus GPUs RTX para que estas apliquen los algoritmos DLSS. Esto hace que las GPUs de gama más baja tengan limitada la resolución a la que pueden ejecutar el DLSS.
EL DLSS se beneficia de la alta velocidad de los Tensor Cores

Los Tensor Cores son esenciales para la ejecución del DLSS, sin ellos no se podría realizar a la velocidad que se ejecuta en las NVIDIA RTX, ya que el algoritmo utilizado para realizar el aumento de resolución es lo que llamamos una red neuronal convolucional, en cuya composición no vamos a entrar en este artículo, solo decir que estas utilizan una gran cantidad de multiplicaciones de matrices y las unidades tensor son ideales para el cálculo con matrices numéricas, ya que son el tipo de unidad que más rápido las ejecuta.
En el caso de una película hoy en día los descodificadores acaban generando la imagen inicial en el búfer de imagen varias veces más rápido que la tasa en la que se muestra en pantalla, por lo que a la hora de escalar hay más tiempo y por tanto se acaba necesitando una potencia de cálculo mucho menor. En un videojuego en cambio no tenemos almacenada en un soporte como será la siguiente imagen, sino que se ha de generar por la GPU, esto recorta el tiempo que tiene el escalador para funcionar.
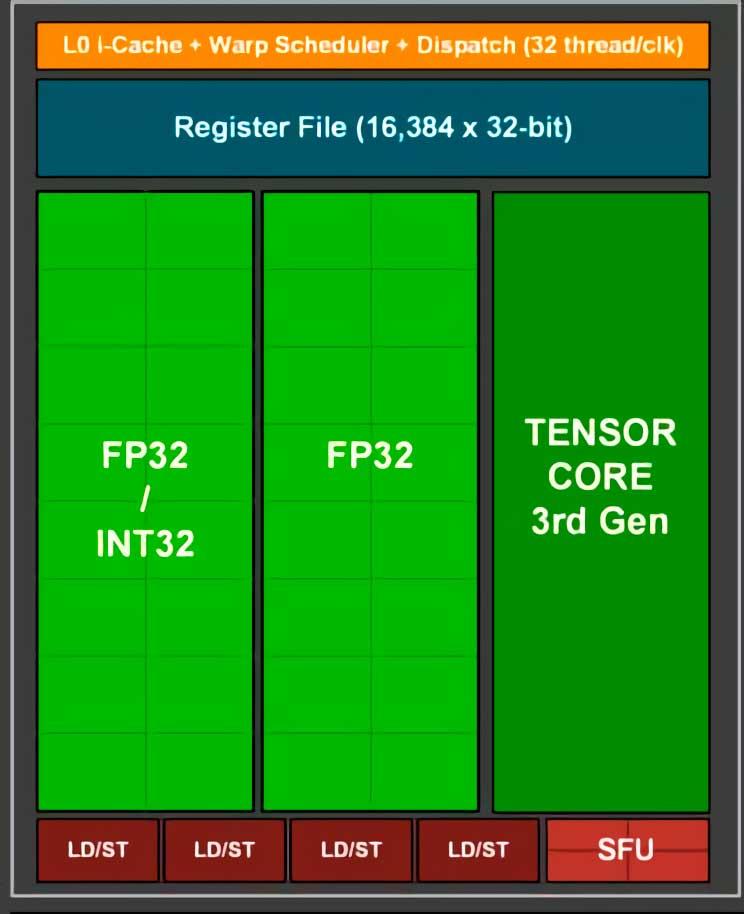
Cada uno de estos Tensor Cores se encuentra en el interior de cada unidad SM y según la tarjeta gráfica que estemos utilizando su capacidad de cálculo variará, al variar el número de SMs por GPU, y por tanto generará la imagen escalada en más menos tiempo. Debido a que el DLSS se activa al final del renderizado se necesita una gran velocidad para aplicar el DLSS, es por ello que es diferente a los otros algoritmos de superresolución como los que se utilizan para escalar películas e imágenes.
No todas las RTX de NVIDIA rinden igual en DLSS
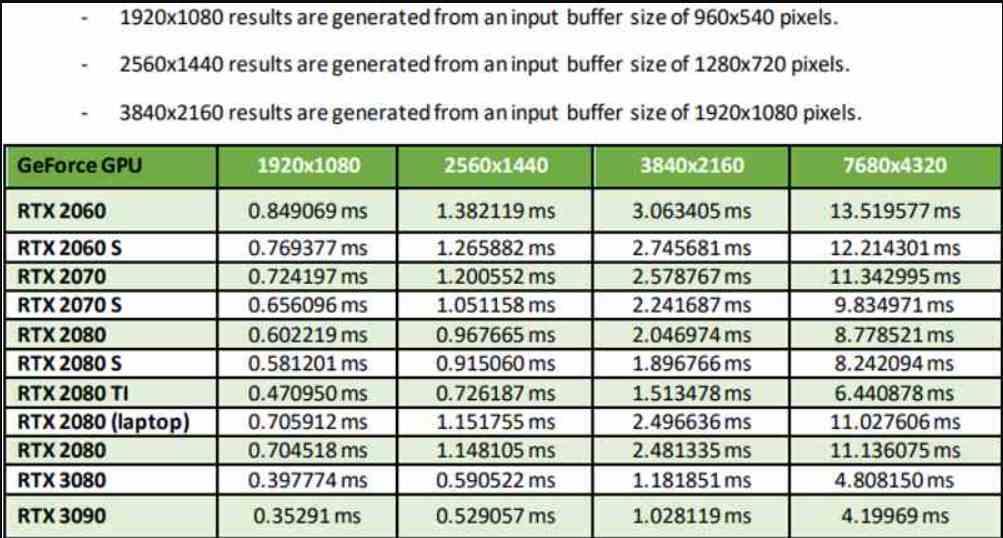
Esta tabla que veis esta sacada de la documentación de la propia NVIDIA, donde la resolución de entrada en todos los casos tiene 4 veces menos la resolución de salida, por lo que estamos en el Performance Mode. Hay que aclarar que existen dos modos adicionales, el Quality Mode da mejor calidad de imagen, pero requiere una resolución de entrada de la mitad de píxeles, mientras que el Ultra Performance Mode hace un escalado de 9 veces, pero tiene la peor calidad de imagen de todas.
Como se puede ver en la tabla el rendimiento no solo varía según la GPU, sino también si tenemos en cuenta la GPU que estamos utilizando. Lo cual no debería sorprender a nadie después de lo que hemos explicado con anterioridad. El hecho que en el Performance Mode una RTX 3090 acabe consiguiendo escalar de 1080p a 4K en menos de 1 ms es cuanto menos impresionante, no obstante esto tiene una contrapartida que se deriva de una conclusión lógica y es que el DLSS en las tarjetas gráficas más modestas va a funcionar peor siempre.
La causa detrás de ello es clara, una GPU con menor potencia no solo va a necesitar más tiempo para renderizar el fotograma, sino incluso para aplicar el DLSS. ¿Es la solución el modo Ultra Performance que aumenta la cantidad de píxeles en 9 veces? No, desde el momento en que el DLSS requiere que la imagen de salida tenga suficiente resolución de entrada, ya que cuanto más píxeles haya en pantalla entonces habrá más información y el escalado será más preciso.
Geometría, calidad de imagen y DLSS
![]()
Las GPU están pensadas para que en la etapa del Pixel/Fragment Shader, en la que se da color a los píxeles de cada fragmento y se aplican las texturas, lo hagan con fragmentos de 2×2 píxeles. La mayoría de GPUs cuando han rasterizado un triangulo lo convierten en un bloque de píxeles que luego es subdividido en bloques de 2×2 píxeles, donde cada bloque es enviado a una Compute Unit.
¿Las consecuencias sobre el DLSS? La unidad de rasterizado suele descartar de entrada todos los fragmentos de 2×2 de tamaño por ser demasiado pequeños, a veces correspondientes a detalles que se encuentran en la lejanía. Esto se traduce en que detalles que a una resolución nativa se verían sin problemas no se ven en la resolución obtenida a través de DLSS por el hecho que no se encontraban en la imagen a escalar.
Dado que el DLSS requiere una imagen con la mayor información posible como referente de entrada, no se trata de un algoritmo pensado para generar imágenes a muy alta resolución a partir de muy bajas, ya que se pierde detalle en el proceso.
¿Y qué hay de AMD, puede emular el DLSS?

Los rumores acerca de la superresolución en el FidelityFX hace meses que rondan la red pero desde AMD todavía no nos han dado ningún ejemplo real sobre el funcionamiento de su contrapartida al DLSS. ¿Qué es lo que le está complicando la vida tanto a AMD? Pues el hecho que los Tensor Cores son cruciales para el DLSS y en las AMD RX 600 no existen unidades equivalentes, sino que se utiliza SIMD sobre registro o SWAR en las ALUs de las Compute Units para obtener un mayor rendimiento en FP16 formatos de menor precisión, pero una unidad SIMD no es un array sistólico o unidad tensor.
De entrada, estamos hablando de un diferencial de 4 veces a favor de NVIDIA, esto significa que a la hora de generar una solución similar parte de una desventaja de velocidad considerable, optimizaciones para el cálculo de matrices aparte. No estamos discutiendo si NVIDIA es mejor que AMD en esto, sino del hecho que AMD a la hora de diseñar sus RDNA 2 no le dio importancia a las unidades tensor.
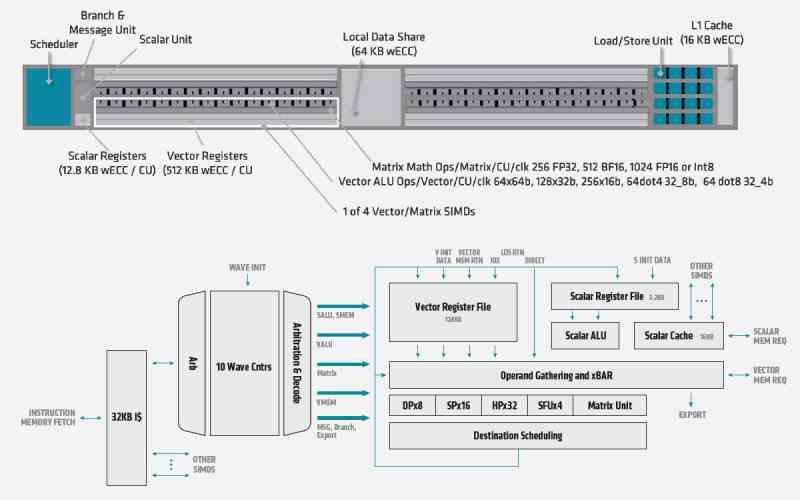
¿Es por incapacidad? Pues no, ya que paradójicamente AMD si que las ha añadido en CDNA bajo el nombre de Matrix Core. Por el momento es pronto para hablar de RDNA 3, pero esperemos que AMD no cumpla otra vez el mismo error de no incluir una de estas unidades. No tiene sentido prescindir de ellas cuando el coste por Compute Unit o SM es de solo 1 mm2.
Por lo que esperamos que cuando AMD añada su algoritmo por la falta de las unidades Tensor no alcance la precisión y tampoco la velocidad del de NVIDIA, pero que AMD presente una solución más simple como puede ser un Performance Mode que duplique los píxeles en pantalla.