
El concepto SWAR a muchos os resultará extraño, pero, ¿qué ocurre si os decimos que las unidades SIMD de vuestras CPUs, GPUs en vuestros sistemas son en su mayoría del tipo SWAR? Este tipo de unidades difieren de las unidades SIMD convencionales y tienen su origen en las extensiones multimedia de finales de los 90. ¿Qué son y cuál es su utilidad a día de hoy?
El rendimiento de un procesador se puede medir de dos maneras, por un lado lo rápido que ejecuta las instrucciones en serie y que por tanto no pueden ser paralelizadas, ya que solo afectan a un dato unitario. Por el otro lado aquellas que trabajan con varios datos y pueden ser paralelizados. ¿La forma tradicional de hacerlo en CPUs y GPUs? Las unidades SIMD, de las cuales existe un subtipo que es altamente utilizado en CPUs y GPUs, las unidades SWAR.
Las ALUs y su complejidad
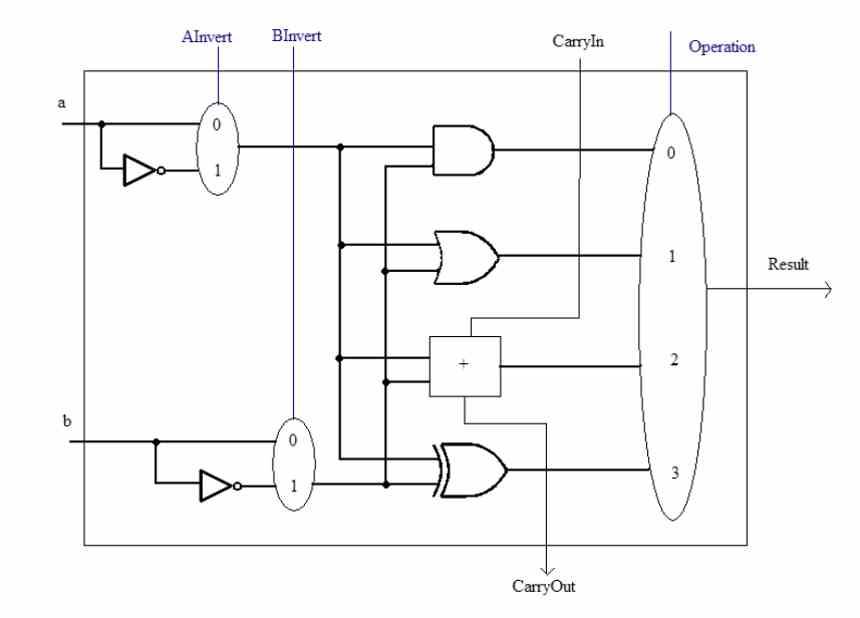
Antes de ponernos a hablar sobre el concepto SWAR hemos de tener en cuenta que las ALUs son las unidades de una CPU que se encargan de realizar cálculos aritméticos y lógicos con los diferentes números. Estas pueden crecer de complejidad de dos maneras, una a partir de lo compleja que sea la instrucción que han de ejecutar. No es lo mismo la circuitería interna de una ALU que puede realizar por ejemplo el cálculo de una raíz cuadrada que no el de una simple suma.
El otro es la precisión con la que trabajan, es decir, la cantidad de bits que manipulan simultáneamente cada vez. Una ALU puede manipular siempre datos iguales o inferiores al número de bits para la que está diseñada. Por ejemplo no podemos hacer que un número de 32 bits pueda ser calculado por una ALU de 16 bits, pero sí que podemos hacer el caso contrario.
Pero, ¿qué ocurre cuando tenemos varios datos de menor precisión? Normalmente que se van a ejecutar a la misma velocidad que a precisión completa, pero hay una forma de acelerarlos, y eso es el SIMD sobre registro. El cual es una forma también de ahorrar transistores en un procesador.
¿Qué es el concepto SWAR?
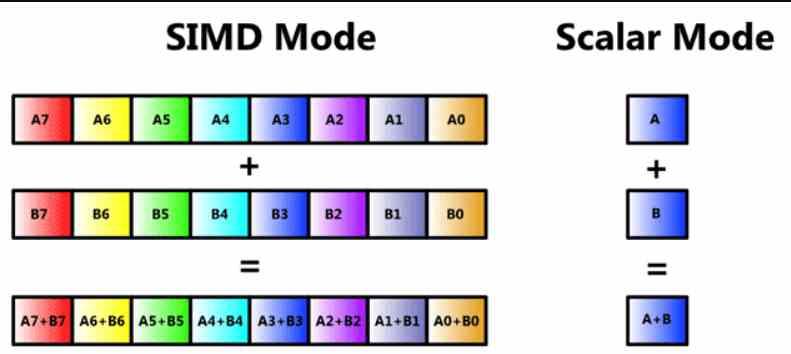
A estas alturas muchos de los lectores sabréis que es una unidad SIMD, pero vamos a repasarlo para que nadie pierda el hilo de este artículo desde el principio. Una unidad SIMD es un tipo de ALU donde a través de una sola instrucción se manipulan varios datos al mismo tiempo, y por tanto son varias ALUs que comparten la parte de captación de lo que es la instrucción en sí misma y su descodificación, pero donde en cada una se trata un dato distinto.
Habitualmente las unidades SIMD se componen por varias ALUs, pero hay casos donde se subdividen las ALUs en otras más simples, así como el registro de acumulación donde almacenan temporalmente sus datos para calcularlos. A esto se le llama SIMD sobre un registro o por sus siglas en Ingles SWAR, las cuales significan SIMD Within a Register o SIMD sobre un registro.
Este tipo de unidad SIMD es altamente utilizada y permite que una ALU de precisión n bits pueda realizar la misma instrucción pero haciendo uso de datos con menos precisión. Normalmente con la mitad de precisión o con una cuarta parte. Por ejemplo podemos hacer que una ALU de 64 bits pueda actuar como dos ALUs de 32 bits ejecutando en paralelo dicha instrucción o cuatro de 16 bits.
¿Profundizando en el concepto SWAR?
Dicho concepto tiene ya varias décadas, pero la primera vez que aparecieron en PC fue a finales de los 90 con la aparición de las unidades SIMD en los diferentes tipos de procesador que existían. Los más veteranos del lugar recordaran conceptos como MMX, AMD 3D Now!, SSE y similares que eran unidades SIMD construidas bajo el concepto SWAR.
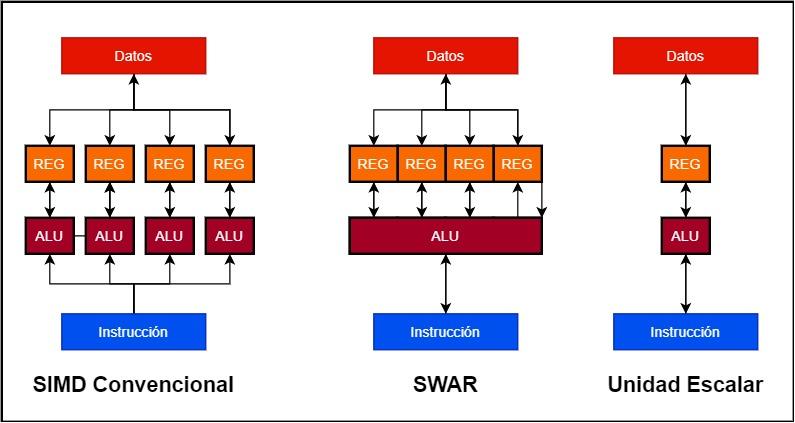
Supongamos que queremos construir una unidad SIMD de 128 bits
- En las unidades SIMD convencionales tenemos varias ALUs trabajando en paralelo y donde cada una de ellas tiene su propio registro de datos o acumulador. Así pues, una unidad SIMD de 128 bits puede estar compuesta por 4 ALUs de 32 bits y 4 registros de 32 bits.
- En cambio una unidad SWAR es una sola ALU que puede trabajar en una precisión muy alta así como también su registro acumulador. Esto nos permite construir la unidad SIMD utilizando una sola ALU de 128 bits con soporte SWAR.
La ventaja que tiene la implementación de una unidad del tipo SWAR sobre una escalar es simple de entender, si una ALU no contiene el mecanismo SWAR que le permite operar como una unidad SIMD ante datos de menos precisión entonces los va a ejecutar a la misma velocidad que los datos de máxima precisión. ¿Qué significa esto? Una unidad de 32 bits sin soporte SWAR en el caso de que tenga que operar la misma instrucción en datos de 16 bits lo hará a la misma velocidad que una de 32 bits. En cambio, si la ALU soporta SWAR podrá ejecutar dos instrucciones de 16 bits en un mismo ciclo, en el caso de que ambas vengan de manera sucesiva.
El SWAR como parche para la IA

Los algoritmos de inteligencia artificial tienen una particularidad, suelen trabajar con datos de muy poca precisión y a día de hoy la mayoría de ALUs operan con precisiones de 32 bits. Esto supone tener que añadir ALUs de precisión de 16, 8 e incluso de 4 bits en un procesador para acelerar dichos algoritmos. Lo que supone complicar el procesador, pero los ingenieros no cayeron en ese error y empezaron a tirar del SIMD sobre registro de una manera particular, especialmente en las GPUs.
¿Es posible combinar una ALU SIMD convencional con un diseño SWAR? Pues si y esto es lo que por ejemplo hace AMD en sus GPU donde cada una de las ALUs de 32 bits que componen las unidades SIMD de sus GPU RDNA soporta SIMD sobre registro y por tanto se puede subdividir en dos de 16 bits, 4 de 8 bits u 8 de 4 bits.
En el caso de NVIDIA le han dado la carga de acelerar los algoritmos para IA a los Tensor Cores, estos son arrays sistólicos compuestos por ALUs de coma flotante de 16 bits interconectados entre sí en una matriz de tres ejes, de ahí el nombre de unidad Tensor. No son unidades SIMD, pero cada una de sus ALUs sí que soporta SIMD sobre registro al poder realizar el doble de operaciones con precisión de 8 bits y el cuádruple con precisión de 4 bits. En todo caso las unidades Tensor son importantes por qué están pensadas para acelerar las operaciones matriz con matriz a una velocidad mucho más alta que con una unidad SIMD.