
Los programas shader llegaron por primera vez en las GPU a partir de la NVIDIA GeForce 3, pero no fue hasta el lanzamiento más tarde de la GeForce 8800 por parte de NVIDIA y la AMD Radeon R600, en la que pudimos ver las primeras Compute Units o SM contemporáneas, las cuales a día de hoy se siguen utilizando.
Las unidades shader son sumamente importantes, por el hecho que ejecutan los diferentes programas shader que se ejecutan en diferentes etapas del pipeline gráfico, así como los programas utilizados en la computación de alto rendimiento cuando la GPU no se utiliza para renderizar gráficos. Por lo que se han convertido en una pieza fundamental en cualquier arquitectura gráfica sea cual sea su utilidad.
Elementos de las Compute Units o SMs
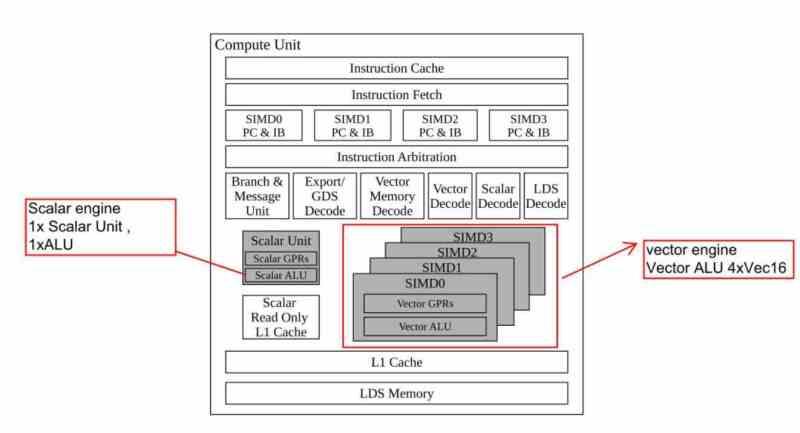
Todas las Compute Units tienen los siguientes elementos en común:
- Caché de instrucciones
- Caché de datos, donde se almacenan los datos que luego se copiarán en los registros, también llamada cache de texturas.
- Planificador, el cual controla que instrucciones se ejecutan y en que orden, esta unidad es la encargada de mover las instrucciones que no se han ejecutado a tiempo a la cola.
- Unidades SIMD: encargadas de ejecutar las diferentes instrucciones, debido a su gran cantidad las unidades SIMD solo pueden ejecutar instrucciones aritméticas simples como sumas, restas y multiplicaciones.
- Unidades SFU: Encargadas de ejecutar instrucciones aritméticas más complejas, son muchas menos que las unidades SIMD por su complejidad y se encargan de operaciones aritméticas como potencias, raíces, logaritmos. Las cuales no son muy comunes, pero que serían muy lentas de ejecutar por las unidades SIMD.
- Registros: Es donde se almacenan los datos e instrucciones que han de ejecutar las unidades SIMD y SFU. Es decir, las olas o warps se almacenan en esta parte.
- Unidades de filtraje de texturas
- Memoria Local: Un espacio de memoria que se utiliza para comunicar varias olas entre sí.
¿Cómo funcionan las Compute Units?
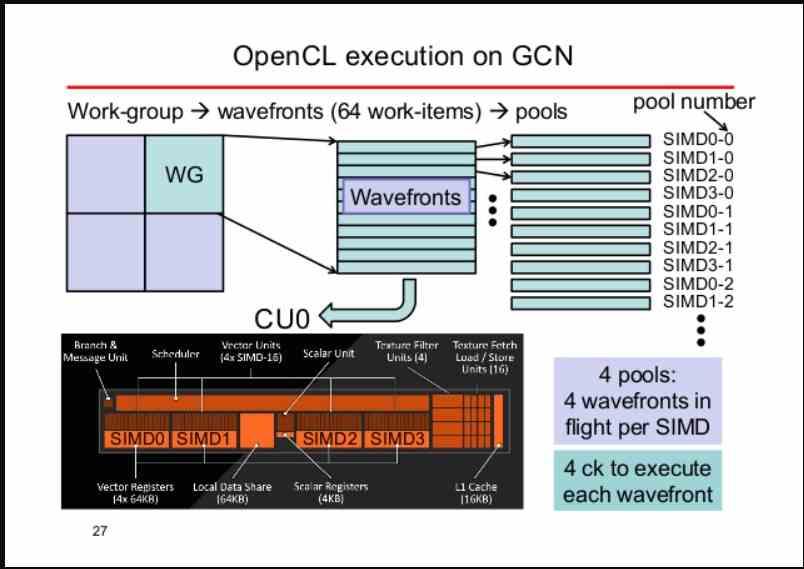
Las unidades shader no ejecutan los programas shader de la misma manera que una CPU ejecuta sus programas, ya que mientras que la CPU tiene una fase de captación desde memoria en el caso de las unidades shader ese proceso no es activo sino pasivo. Es decir, son los grupos de instrucciones y datos en los diferentes hilos de ejecución los que van a dichas unidades. A esto se le llama Stream Processing, que en español se traduciría como procesamiento en caudal.
El procesamiento en caudal supone que las instrucciones sean ejecutadas a medida que van llegando a los registros de la unidad shader, donde las diferentes unidades van ejecutando las instrucciones que se encuentran en dichos registros de manera secuencial, las cuales no tienen por qué pertenecer todas al mismo programa shader.

Cada tipo de instrucción tiene un tiempo medio en ejecutarse según cuál sea su tipo, por ejemplo en las arquitecturas GCN se dividían las instrucciones en tres tipos distintos:
- Simples: Se resuelven en un solo ciclo de instrucción.
- Complejas: Se resuelven en cuatro ciclos de instrucción
- Salto: Se resuelven en dieciséis ciclos de instrucción
En una unidad shader no existen las instrucciones de acceso directo a la memoria, por lo que el dato ha de estar junto a la instrucción para ejecutarse. Cuando la instrucción tarda en ejecutarse por falta del dato esta es retrasada en su ejecución y se adelante la siguiente. A eso se le llama ejecución Round-Robin y es utilizada para que cada una de las Compute Units no pare su funcionamiento en seco.
¿Qué es una ola o Warp?

Una ola o Warp es lo que llamamos un conjunto de kernels de tamaño variable, siendo cada kernel una simple instrucción con su dato correspondiente. Debido a que en el procesamiento gráfico se aplica la misma instrucción para varias primitivas gráficas al mismo tiempo se utilizan unidades SIMD para ejecutar las diferentes olas.
Dependiendo de cada arquitectura una ola puede tener un tamaño u otro, siendo los tamaños estándar de 32 y 64 elementos. Si por ejemplo tenemos una ola de 64 elementos y una unidad SIMD de 16 ALUs, entonces podremos asignar por ciclo de reloj un elemento a cada ALU. Luego dependiendo del tipo de instrucción esta puede tardar más o menos en resolver la ola.
La cantidad de olas que puede soportar una Compute Unit o un SM depende de lo grandes que sean sus registros. Mientras queden olas y por tanto kernels a ejecutar, dicha Compute Unit seguirá ejecutando las diferentes olas y se mantendrá ocupada. Es por ello que la parte central de la GPU, ha de ser capaz de alimentar con el suficientemente número de olas a cada Compute Unit o SM.
Uso de las ALUs y ocupación de los registros

Uno de los problemas que existía en las Compute Units de las unidades GCN y RDNA de primera generación de AMD era que por unidad SIMD el planificador de la GPU estaba pensado para ejecutar por unidad SIMD hasta 40 olas de 64 elementos cada una. Lo cual teniendo en cuenta el tiempo de ejecución, esto eran unos 40 ciclos de reloj.
¿El problema? Si se buscaba ocupar la mayor parte de las ALUs de la unidad SIMD entonces se creaban ciclos muertos, ya que no había ya nada que calcular. Si se buscaba aprovechar todos los ciclos entonces las ALUs entonces se encontraban que todas las unidades SIMD no estaban ocupadas. ¿La solución? AMD en RDNA 2 decidió reducir la capacidad del planificador de 40 a 32 elementos con tal de conseguir la mayor ocupación en las diferentes unidades de sus Compute Units.