
Aunque todavía no ha salido al mercado como tal las llamadas BIG Navi con arquitectura RDNA2 y sus chips Navi 2x, lo cierto es que AMD (y en menor medida NVIDIA) ya trabajan en implementar la diga sucesora de esta (que no será HBM2E): HBM3. Aunque no sabemos demasiado sobre ella a día de hoy, se han filtrado una serie de datos comparativos frente a HBM2 que son bastante interesantes y que pueden decantar la balanza del rendimiento entre ambas compañías, ¿de cuánta es la mejora?
Como bien sabemos, HBM2 y HBM2E son dos tipos de VRAM que tienen una serie de limitaciones importantes en cuanto a su implementación y desarrollo para los chips de GPU. Tienen muchas ventajas desde el punto de vista del rendimiento y el consumo, son el presente por necesidad, pero no serán el futuro como tal.
Para ello llega HBM3, que dentro de lo poco que sabemos de ella, terminará con los problemas de sus dos versiones anteriores. Hasta hoy, no conocíamos su rendimiento, y sobre todo, de cuanta mejora podemos hablar frente a la versión a la que sustituye.
HBM2 vs HBM3: llegan las primeras comparativas y simulaciones de rendimiento
Como decimos, los primeros datos ya están aquí, salvo que como suele ocurrir en estos casos no se ofrecen a modo de anchos de banda, FPS o cualquier otra métrica común dentro del sector gaming.
Como memoria TOP de alto rendimiento, lo que interesa al mundo empresarial es saber de las mejoras frente a HBM2 en un entorno de servidores Exascale, que a fin de cuentas son los que dominan el mundo por su enorme potencia. Por lo tanto, los datos que vamos a ver reflejan esta situación y se centra en obtener conclusiones para la organización, el ancho de banda, la latencia, la capacidad y la energía.
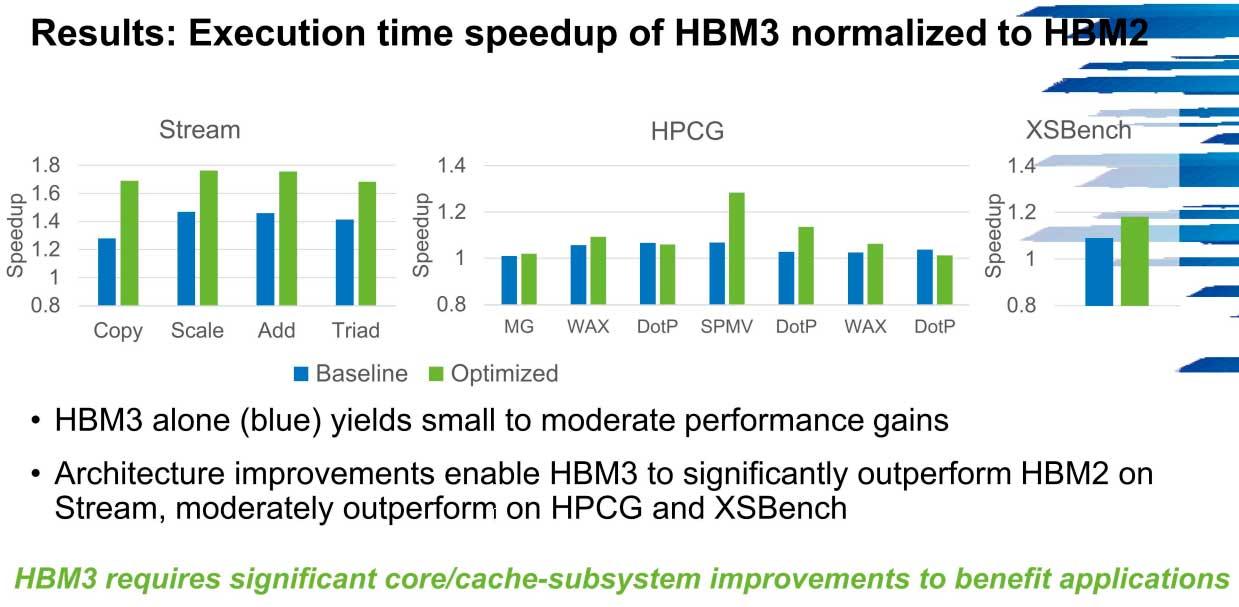
La pregunta es clara y clave: ¿hasta qué punto los PCs del futuro se beneficiarán de HBM3 frente a HBM2? Los datos son bastante claros.
Como vemos, la optimización de la HBM3 va a ser un pilar más que importante en los sistemas Exascale, y es que se puede conseguir hasta un 1,7x de aumento de la velocidad en los sistemas sobre HBM2 a poco que el número de núcleos y las cachés de los subsistemas den la talla.
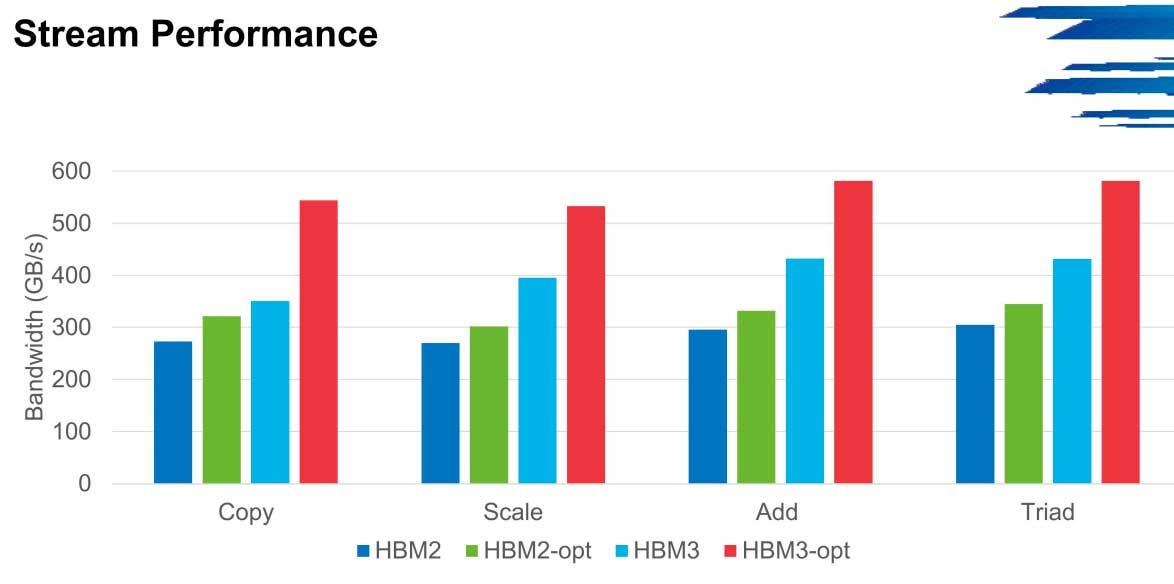
En HPCG el rendimiento en ancho de banda se puede disparar hasta los 600 GB/s en estos entornos desde los 300 GB/s de los que parten las primeras versiones a bajas velocidades, un escenario que se repite en Stream por ejemplo.
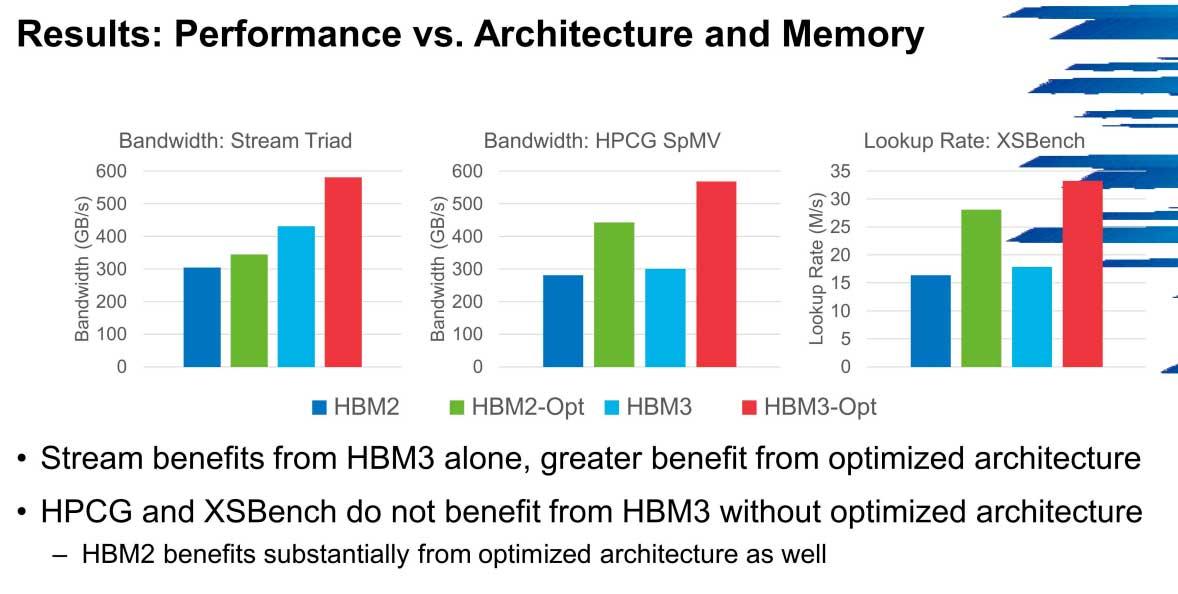
El principal problema que va a arrastrar HBM3 es precisamente las redes NoC, en las cuales el ancho de banda sea un cuello de botella. Los clusters tendrán una mejora leve en estos casos siempre que no exista dicho cuello de botella, pero no es un tipo de memoria que al parecer sea demasiado óptima para sistemas no optimizados precisamente.
El número de hilos, tipos y tamaños de caché así como directorios son claves
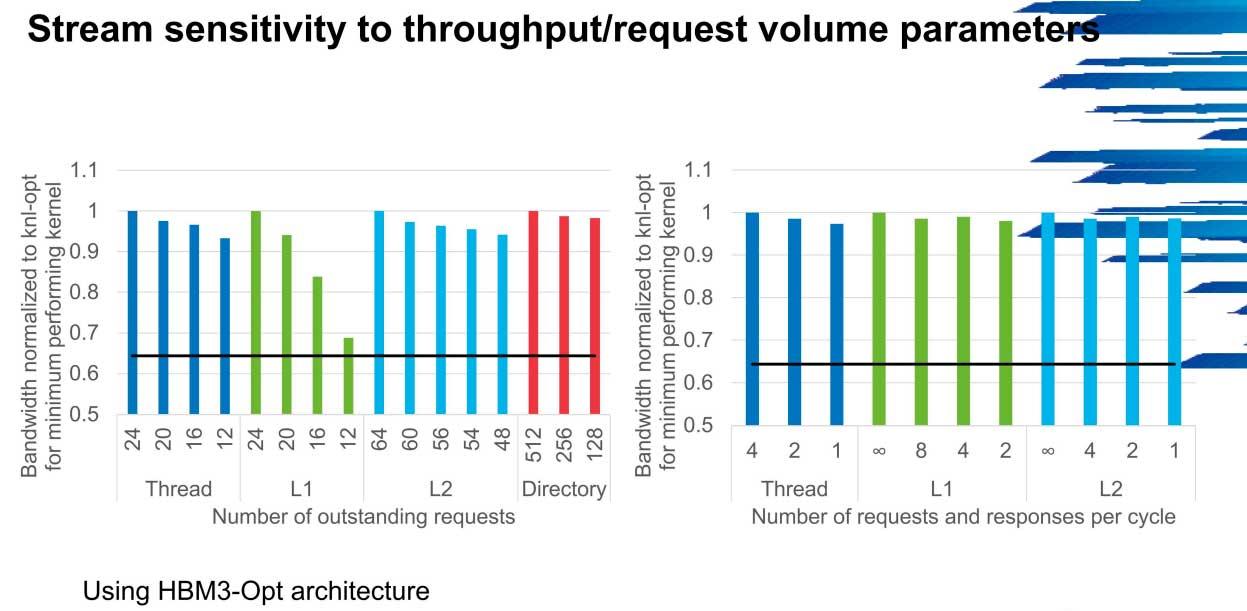
La frecuencia y el número de núcleos también tienen mucho que decir, ya que el incremento del ancho de banda pasa de entre 1 y 2 GHz en 300 GB/s hasta los 600 GB/s si la frecuencia de la red es de 5 GHz, algo que ahora mismo está fuera del alcance de casi todos los servidores del mundo.
El escenario más realista es una frecuencia de 4 GHz, donde hay una leve caída del ancho de banda operacional, sobre todo en scale y copy, pero es asumible teniendo en cuenta la potencia actual.
El número de hilos, tamaño de cachés L1 y L2, así como el número de directorios también son fundamentales, sobre todo en caché L1. La escalabilidad casi es de un 80% al pasar de 12 a 24, algo que no se refleja en los demás parámetros pero que indica la importancia que van a tener las futuras arquitecturas en este punto, algo en lo que AMD ya lleva tiempo trabajando y que Intel se tomó en serio hace poco más de un año.
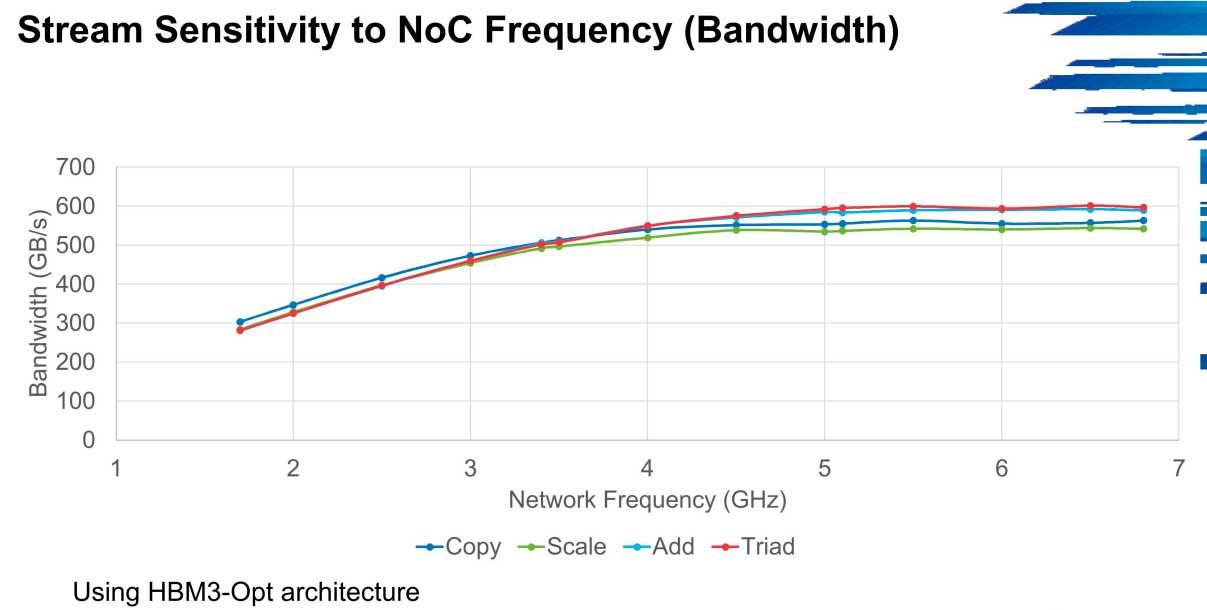
En definitiva, HBM3 para servidores es tremendamente dependiente de los recursos NoC, se necesitará una optimización máxima para sacarle todo el provecho en cuanto a ancho de banda se refiere (mucho más cuando aumenten su velocidad final en el JEDEC) y en definitiva es un tipo de memoria muy dependiente de la escalabilidad y recursos.
En gaming volverá a ser una memoria muy cara y con nulos beneficios, donde ya ha quedado en múltiples ocasiones que no aporta beneficio alguno en altas resoluciones y hercios. Será, no obstante, empleada seguramente por AMD en su GPU de gama alta cuando los consumos se disparen y GDDR6 no sea una opción por su voltaje, donde solo nos queda la esperanza de que RDNA 2 sea más eficiente y con ello se evite su implantación y costes en el equipo de Lisa Su.
Por otro lado, NVIDIA no tiene visos de usarla fuera de sus GPU Tesla y apostará por las memorias GDDR6 de 18 Gbps para aumentar el ancho de banda manteniendo los consumos generales de sus tarjetas, sobre todo aprovechando los nuevos nodos de 7 nm y 8 nm de TSMC y Samsung.