
En la GTC 2022, Jensen Huang ha presentado sus nuevas tarjetas para inteligencia artificial con su chip GH100, en varias configuraciones y factores forma. Estas se han presentado bajo el nombre de NVIDIA GH100 Tensor Core GPU y al contrario de las RTX no se encuentran diseñadas para el mercado gaming y no son para PC domésticos. Aunque nos dan una pista de lo que podríamos ver en RTX 40.
Se ha de tener en cuenta que NVIDIA empezó a diferenciar sus tarjetas gráficas para servidores de las utilizadas en el mercado doméstico y el profesional a partir de la GP100, cuya arquitectura era distinta a sus contemporáneas para gaming, las GTX 1000. Desde entonces las diferencias entre ambas gamas se han ido acrecentando más y más. Siendo la principal de ellas el hecho de que unidad shader, conocida cómo SM en ambas gamas, difiere por completo el enfocarse a necesidades diferentes. Una para reproducir los gráficos de los juegos para PC y el otro para cálculos de carácter científico.
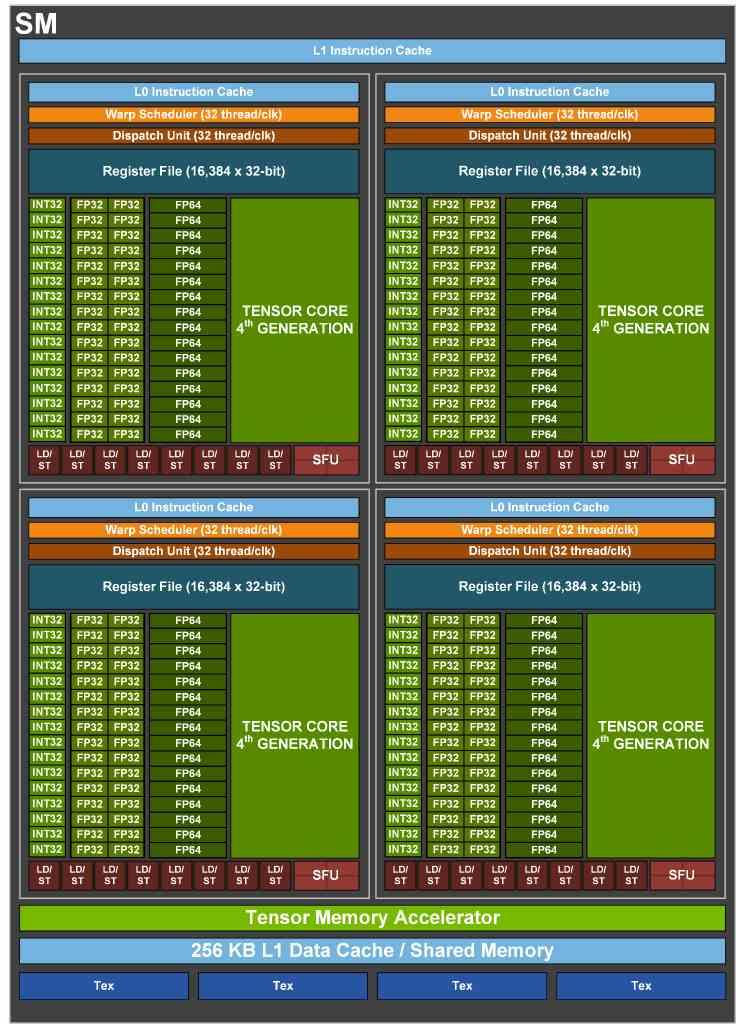
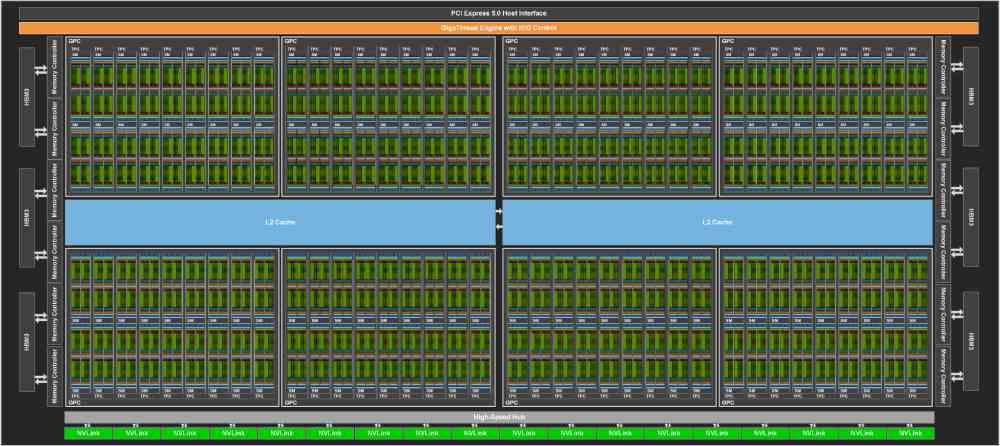
Cómo se puede ver los RT Cores para acelerar el Ray Tracing no se encuentran en esta tarjeta gráfica, de ahí que no reciba el nombre de RTX. En cambio, tenemos que las GPU cómo la NVIDIA GH100 soportan coma flotante de doble precisión. La cual es esencial para el trabajo en ciertos campos de investigación científica y de ingeniería. También hemos de tener en cuenta que pese a su nombre, la NVIDIA GH100 Tensor GPU no puede reproducir gráficos con la misma velocidad y soltura que las tarjetas para gaming.
Así es la NVIDIA GH100 Tensor GPU, una bestia para la IA y el Deep Learning
Para la fabricación de este mastodonte de más de 800 mm2, aunque algo más pequeño que su predecesor, NVIDIA ha optado por el nodo N4, una versión algo más optimizada de su nodo de 5 nm. Sobre el que ha creado un diseño que en cierta manera es continuista con procesador del mismo tipo de la generación anterior, el A100. De paso, tampoco nos podemos olvidar que tenemos dos versiones, una con el factor forma SXM para superordenadores y otra en forma de tarjeta PCI Express, la cual por cierto no usa el nuevo conector PCIe Gen 5 y se ve limitada a 350 W. En cambio, la versión completa puede alcanzar los 700 W de consumo en total.
En cuanto a sus especificaciones técnicas oficiales, para los diferentes modelos son las siguientes:

Cómo se puede ver, aparte de adoptar la configuración en cuanto a las unidades de coma flotante de 32 bits de las RTX 30, con el segundo array de las mismas conmutado con la unidad de enteros, lo que más destaca es el uso de la memoria HBM3 por primera vez en un hardware finalizado. Aunque por el momento desconocemos si los primeros modelos van a usar memoria HBM2E mientras NVIDIA espera que el nuevo estándar esté disponible en masa. Sea cual sea el tipo de memoria utlizada,
¿Qué cambios de la NVIDIA GH100 podríamos ver en las RTX 40?
Lo más obvió de todos son los Tensor Cores de cuarta generación los cuales ahora son mucho más anchos y pueden superar el PetaFLOP de potencia, es decir, 1000 TFLOPS. Sin embargo, al igual que paso con RTX 30 respecto a A100, lo más seguro es que dejen fuera una buena parte de las capacidades. En especial todas aquellas relacionadas con el entrenamiento y el soporte de ciertos formatos de datos.
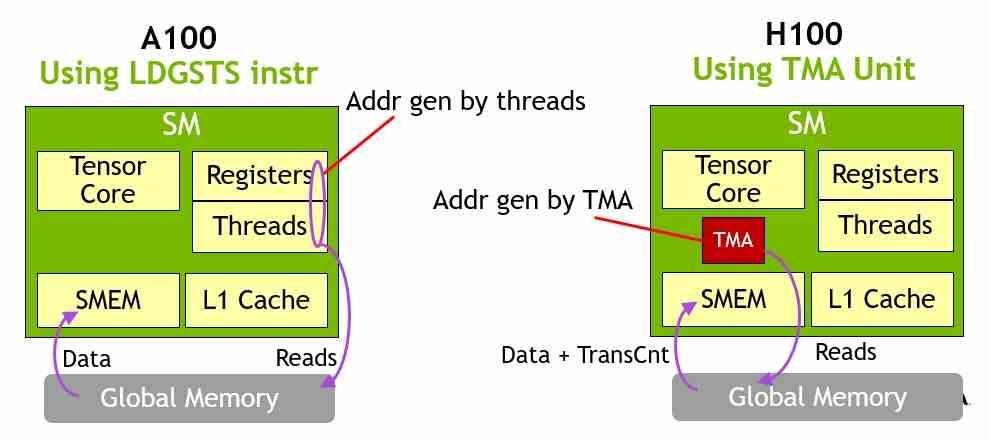
El segundo punto que también llama poderosamente la atención es el añadido del Tensor Memory Accelerator, el cual les permite a los Tensor Cores acceder a los datos más allá de la caché L1 cuando los registros y la caché de dicho nivel están ocupados realizando otras tareas. Dicho de otra manera, el acceso a memoria ya no estará conmutado y esto va a suponer una enorme ventaja en los algoritmos de Aprendizaje profundo aplicados a acelerar y mejorar visualmente los juegos.
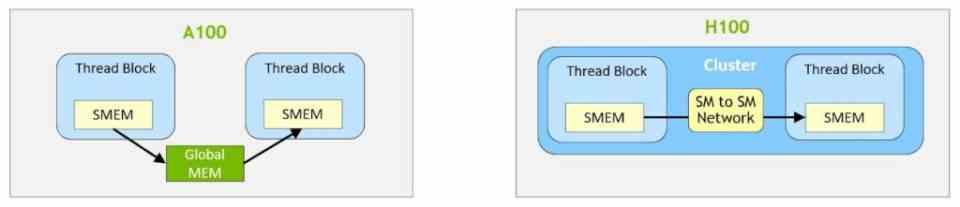
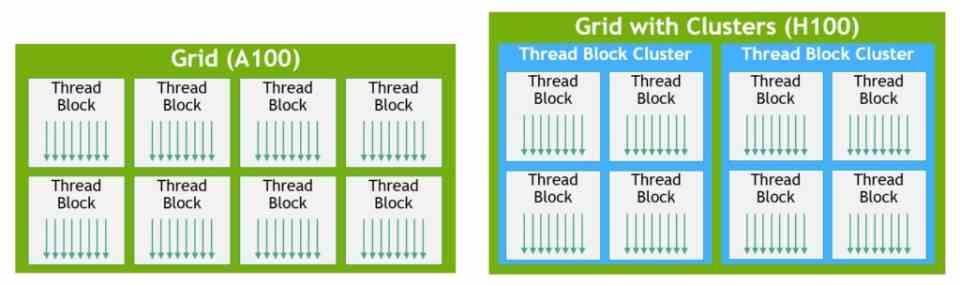
Ya para terminar nuestro resumen rápido, otra de las novedades que veremos en las RTX 40 y que se han estrenado con las NVIDIA GH100 Tensor GPU tiene que ver con la intercomunicación entre los SM. los llamados Thread Cluster Block que permiten intercomunicar de forma directa un conjunto de SM sin que estos tengan que bajar a buscar los datos a la caché L2 o lo que es peor, a la RAM de la propia tarjeta. Reduciendo así la latencia en la intercomunicación entre los diferentes núcleos que componen el chip.