
NVIDIA y AMD han dado casi todos los detalles de sus últimas arquitecturas de GPU Gaming, pero se suelen guardar elementos bajo llave. La mayoría de ellos son cajas negras que no serán nunca documentados, otros en cambio no han sido revelados, pero sí que se pueden medir, A la hora de ejecutar instrucciones, ¿cómo son las latencias en las RX 6000 y las RTX 30, cuáles son las diferencias?
Las latencias de instrucciones no son una información que los fabricantes de GPUs suelan dar en sus especificaciones públicas, ya que son del interés de los desarrolladores de juegos y aplicaciones. Es por ello que para el público general suelen ser desconocidas. No obstante, es una información que los aficionados al hardware siempre nos es interesante conocer.
Latencia de instrucciones en una GPU

La latencia de instrucciones en todo procesador es el tiempo existente, medido en ciclos de reloj, que hay entre la unidad de procesamiento y el dato que necesita para realizar una operación. Si el dato no se encuentra en los registros entonces es necesario que el mecanismo de captación recorra toda la estructura de cachés hasta llegar a un dato.
Debido a que las GPUs están compuestas por una enorme cantidad de núcleos en comparación con las CPUs, la cantidad de peticiones a la VRAM es enorme. De ahí a que sus núcleos tengan una composición distinta y estén más basados en ejecutar varios contextos o hilos de ejecución que no en la ejecución en serie. Esto les permite cambiar de un contexto a otro mientras esperan el dato de uno de los hilos de ejecución.
No obstante la latencia de instrucciones en una GPU también es importante, aunque en menor medida que en una CPU, ya que no siempre una GPU tiene el nivel de tareas por hacer para mantenerla ocupada. Además, hay momentos en el pipeline 3D como son los Pixel/Fragment Shaders, donde el acceso a la VRAM se hace de manera continua y es necesario una baja latencia para resolver la mayoría de los hilos de ejecución.
AMD RX 6000 frente a NVIDIA RTX 30 en latencias
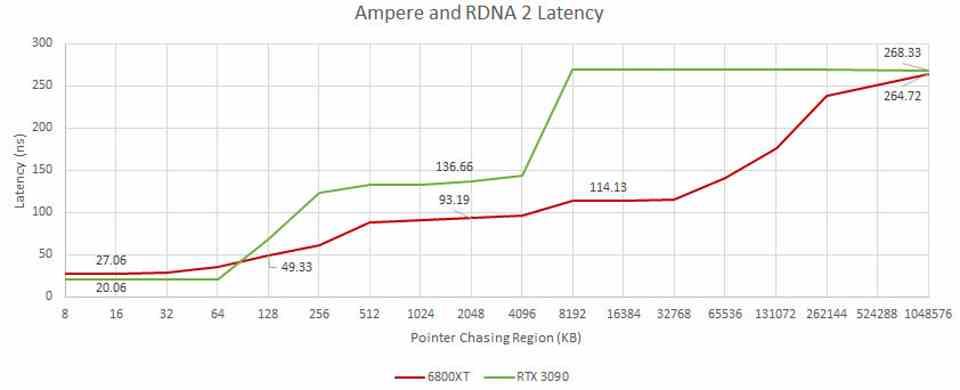
El sitio web Chips and Cheese ha decidido medir las latencias de las últimas GPUs gaming, NVIDIA RTX 30 y AMD RX 6000, para ello han utilizado el test pointer chasing en OpenCL. Este test consiste en copiar bloques enteros de datos desde la VRAM a las cachés. Dependiendo del tamaño del bloque estos datos se podrán copiar en los diferentes niveles de cachés en la GPU, para luego medir el tiempo de acceso a todo el bloque al completo, el cual estará en diversos niveles según su tamaño.
El test demuestra como AMD ha retocado en las arquitecturas RDNA su jerarquía de cachés, ya que este era uno de los puntos en los que su anterior arquitectura gráfica, GCN, estaba muy por debajo de NVIDIA. Hay que tener en cuenta que sin contar la Infinity Cache, la arquitectura de AMD tiene 3 niveles de caché: L0 dentro de la Compute Unit, L1 por Shader Array y luego la L2. En cuanto a la Infinity Cache esta añade solo 20 nanosegundos adicionales al acceso en comparación con la L2.
En cuanto a NVIDIA, su estructura de cachés no ha evolucionado desde Maxwell, GTX 900. El tiempo en ir desde la caché dentro del SM en las RTX 30 a la caché L2 es de 100 nanosegundos, mientras que en AMD ir desde su equivalente a la caché L2 es solo de 66 ns existiendo un nivel por el medio. Una causa podría ser el enorme tamaño de las GPU de NVIDIA en comparación con las de AMD. Siendo la caché una de las mejoras que NVIDIA podría haber aplicado en Lovelace.