
A la hora de comprar una CPU o una GPU nos encontramos con especificaciones técnicas como la velocidad de reloj, la cantidad de operaciones en coma flotante, el ancho de banda de la memoria, etc. Pero, una de las formas de medir el rendimiento y diseñar un procesador tiene que ver con la latencia de las instrucciones. Os explicamos que es y por qué es tan importante para conseguir CPUs más rápidas.
El rendimiento de un procesador respecto a otro se mide por el tiempo en que tarda en solventar el mismo programa. Lo cual puede conseguir de muchas maneras distintas y hay diferentes caminos con tal de aumentar el rendimiento y con ello reducir el tiempo que tarda en ejecutarse. Una de ellas es recortar la latencia de las instrucciones que se ejecutan. Pero, ¿en qué consiste exactamente?
¿Qué entendemos por latencia de las instrucciones?
La latencia es el tiempo en el que un procesador tarda en realizar una instrucción y esta es variable de donde se encuentre el dato, ya que cuanto más alejado este más tiempo ha de recorrer para que estos sean colocados en los registros correspondientes. Es por este motivo y debido a que la memoria no escala a la misma velocidad que los procesadores se tuvieron que crear mecanismos como la caché e incluso integrar el controlador de memoria dentro del procesador para disminuir la latencia de las instrucciones.
No obstante esta no se suele tener muy en cuenta a la hora de vender una CPU e incluso una GPU, se suelen utilizar otras medidas de rendimiento para hablar que una arquitectura es superior a otra. Pero la latencia de las instrucciones, no suele ser utilizada a la hora de promocionar un procesador cuando es una forma más de entender el rendimiento.
Ciclos de reloj por instrucción y latencia

La primera medida de rendimientos son los ciclos por instrucción, ya que hay instrucciones lo suficientemente complejas como para tener ejecutarse en varios ciclos de instrucción distintos. Muchas veces a la hora de diseñar nuevos procesadores, los arquitectos suelen hacer cambios sobre la forma de resolver una instrucción respecto a procesadores anteriores con la misma ISA, ya sea si estamos hablando de CPUs, GPUs o cualquier otro tipo de procesador.
Lo que no se cambia jamás es la forma de la instrucción, sino que lo que se hace es recortar la cantidad de ciclos de reloj que son necesarias para revolverla. Por ejemplo podemos tener una instrucción encargada de calcular la media entre dos números que tarde en un procesador con la misma ISA 4 ciclos de reloj y que mejore en un 20% a una versión anterior de una misma instrucción que tarde 5 ciclos.
La idea no es otra que la de reducir el tiempo que tardan una parte de las instrucciones con tal de disminuir el tiempo en que se tarda en ejecutar un programa. De esta manera se consigue con pequeños acelerones en las instrucciones que el global del rendimiento aumente.
Caché y latencia de instrucciones

La memoria caché almacena una copia de la memoria RAM a la que apuntan las instrucciones que se ejecutan en ese momento, esto le permite al procesador acceder a la memoria sin tener que acceder a la RAM y dado que la cache está más cercana a las unidades de la CPU que la memoria se acaba pudiendo ejecutar la instrucción en menos tiempo, ya que la captación de instrucciones requiere menos tiempo.
El hecho que hablemos de diferentes niveles de caché, no significa que todas las cachés de primer nivel, segundo nivel e incluso de tercer nivel tengan la misma distancia y por tanto latencia, sino que de una arquitectura estas varían. Por ejemplo en las actuales de Intel Core de Intel la latencia con las cachés es menor que en sus equivalentes de la competencia, los AMD Zen de AMD.
De cara a mejorar una arquitectura de una versión a otra, uno de los cambios que se suelen plantear es la disminución de la latencia respecto a la caché. Especialmente a la hora de portar una misma arquitectura de un nodo a otro, lo que gracias a la reducción del tamaño del procesador y la distancia entre las unidades y la caché.
El dilema de los chiplets y la latencia

La idea de los chiplets no es otra que la de utilizar varios chips en vez de uno solo para una misma función, esto aumenta por tanto la distancia de comunicación entre las diferentes partes y por tanto la latencia. Esto se traduce en una pérdida de rendimiento respecto a la versión monolítica del procesador.
En el caso de los AMD Ryzen, que son el caso más conocido, una forma que se tiene de recortar la diferencia entre las versiones basadas en chiplets y las que son procesadores monolíticos es la de recortar la caché de último nivel en los segundos. ¿El motivo? Si tuvieran la misma cantidad de caché entonces las versiones vía chiplet solo por la distancia del controlador de memoria tendrían menor latencia en las instrucciones y con ello un mayor rendimiento.
La latencia de instrucciones es la clave del 3DIC

Los chips integrados en tres dimensiones son otro de los puntos clave, en especial los que apilan memoria sobre un procesador. El motivo de ello es que ponen la memoria tan cercana al procesador que solo por eso se aumenta el rendimiento. La contrapartida de esto es el ahogamiento termal entre la memoria y el procesador, lo que fuerza a disminuir la velocidad de reloj y en algunos diseños puede ocurrir que colocar el procesador y la memoria por separado permite alcanzar mayores velocidades reloj que en un diseño 3DIC.
Si la memoria está lo suficientemente cercana al procesador puede crear un efecto curioso, en el que cueste menos tiempo el acceder a los datos en la memoria embebida que recorrer los diferentes niveles de caché de la arquitectura uno por uno. Lo cual cambia por completo la forma de diseñar un procesador, ya que la memoria caché es una forma de reducir la latencia cuando los datos a procesar se encuentran demasiado alejados.
Distancia y consumo están relacionados
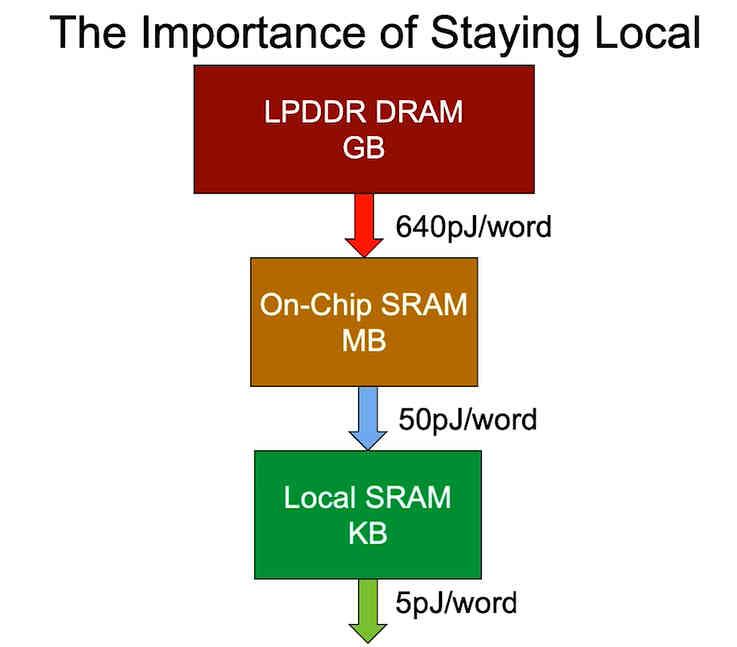
El último punto es el del consumo energético, el cual depende de donde se encuentren los datos. Es por ello que a la hora de diseñar una versión más optimizada en cuanto a consumo de un procesador lo que se busca es recortar la distancia en la que se encuentran los datos, ya que el consumo energético de un procesador aumenta con la distancia en la que se encuentren los datos y no solo la latencia, por desgracia no podemos colocar las enormes cantidades de datos que necesitamos para ejecutar un programa dentro del espacio de un chip.
En un mundo donde el consumo energético por el cambio climático se ha convertido en uno de los puntos más importante y la portabilidad y bajo consumo son un elemento de venta y por tanto de valor en muchos productos, el hecho de buscar formas de acercar la memoria al procesador y con ello disminuir la latencia de las instrucciones algo que se vuelve extremadamente importante con tal de aumentar el rendimiento por vatio.