
La nueva generación de tarjetas gráficas de los tres gigantes está un poco en el aire, porque si bien sabemos algunos detalles sobre ellas la realidad nos indica que no sabemos si finalmente tendrán un núcleo o varios dentro de un interposer. Hay mucha especulación, donde Intel es el único que ha mostrado y confirmado cómo serán sus die, pero lo que no había comentado es lo que tiene preparado para las gráficas ARC Battlemage: así funcionarán sus GPU MCM con varios núcleos.
AMD podría traer GPUs MCM, NVIDIA parece que lo fiará todo a monodie una vez más (aunque podría sorprender con varias líneas de GPU) mientras Intel va a lo suyo sabiendo que no podrá competir de momento con RDNA 3 y Ada Lovelace o Hooper. Por ello y tras una patente del 21 de septiembre del año pasado que ahora ve la luz, está preparando Battlemage para ser una apuesta definitiva para la gama alta, media y baja.
Un nuevo procesamiento de gráficos para una nueva arquitectura
Underfox@Underfox3Patent: Position-based rendering apparatus and method for multi-die/GPU graphics processing – IntelIntel MCM GPUs is coming…
More details: https://t.co/GIkfwrXGzV https://t.co/sXGt9nbJ1S
24 de mayo, 2024 • 07:26
30
0
Como sabemos, hasta ahora todo ha sido AFR y SFR en tarjetas gráficas tanto de un die como de varios, aunque estos fueran realmente SLI y Crossfire encubiertos. El escenario futuro será parecido, pero sobre todo plantea la ventaja de chips totalmente independientes en un mismo PCB mediante interposer, tal y como hace AMD ahora mismo con los Ryzen, Threadripper y EPYC, pero en GPUs.
La nueva patente de Intel muestra precisamente cómo va a hacer que trabajen sus GPU con distintos núcleos (dies), ya que las tecnologías de AFR y SFR no escalan ni mucho menos como deberían pese a que en el papel son óptimas, pero en el mundo real tienen demasiados problemas. La idea que ha tenido Intel es bastante sencilla como concepto, pero realmente complicada de implementar en hardware.
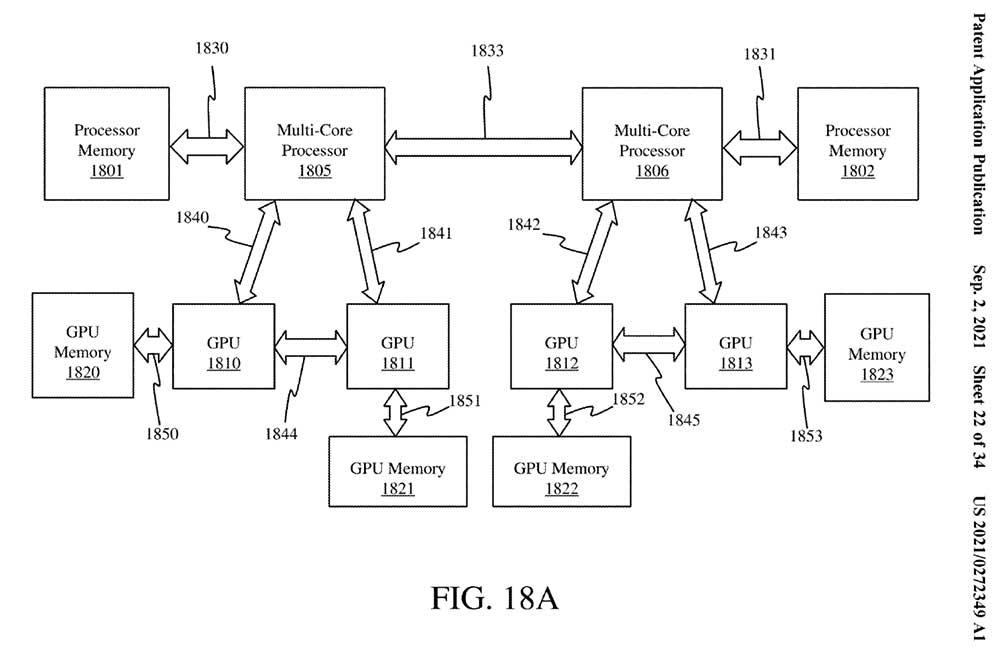
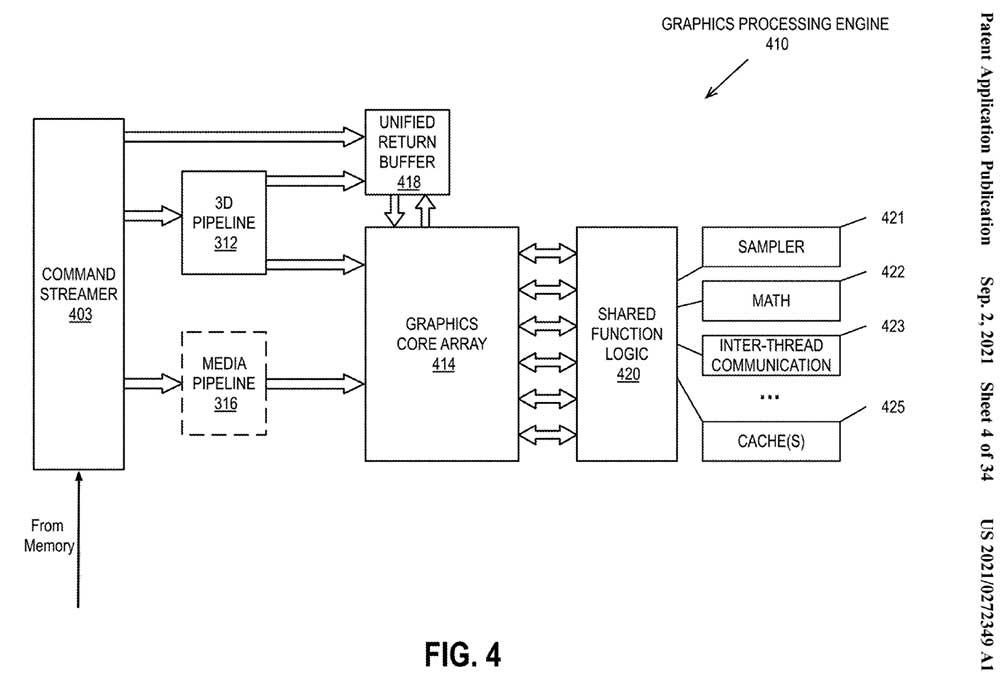
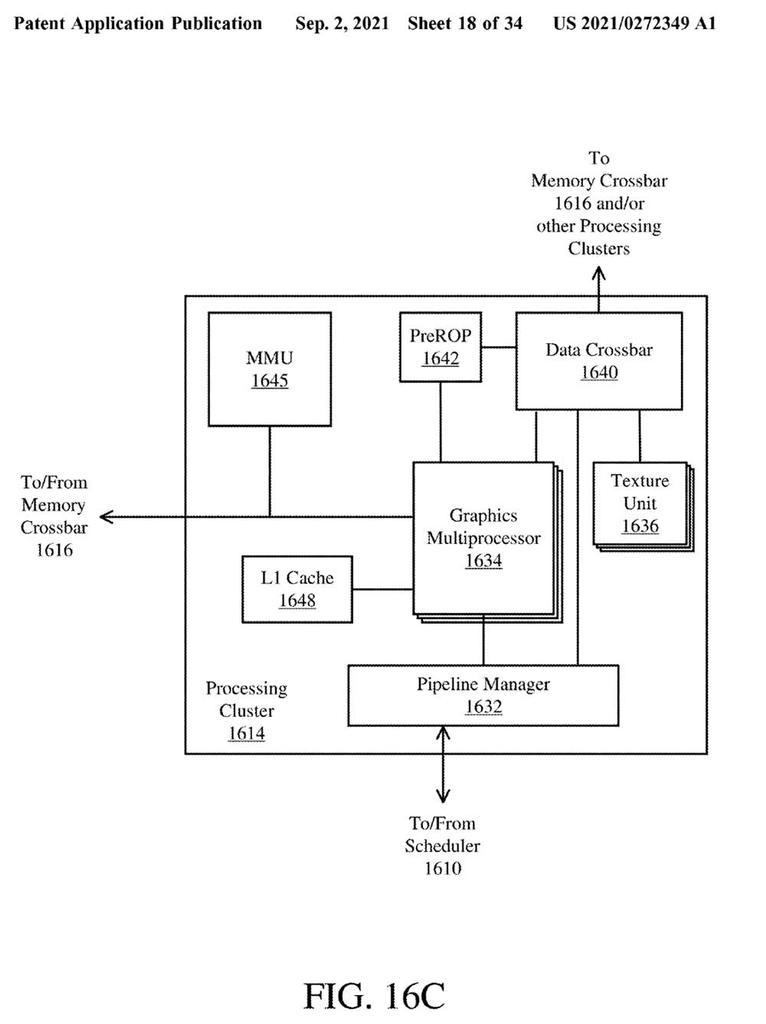
Lo que pretenden los de Pat Gelsinger es incluir un búfer de comandos donde este divida las draw calls y las encauce a los correspondientes dies mediante un comprobador de renderizado integrado con Tiled. Esta división parece hacerse de forma aleatoria, donde una vez realizada y seleccionados los dies que las trabajarán serán ejecutadas por una nueva unidad llamada POSH o Position-Only Shaders.
Estas unidades trabajan dentro de los dies y son las encargadas de mandar las Draw a los núcleos correspondientes también de forma aleatoria. Evidentemente hay un orden de carga de trabajo y sobre todo de representación en pantalla, donde esta se dividirá en Tiled mediante el Checkerboard descrito anteriormente o comprobador. Esta asigna y comprueba que cada primitiva está presente en un espacio de la pantalla.
Una vez que la asignación está hecha y los datos de visibilidad están correctos se da prioridad a las primitivas más relevantes mediante el procesador de geometría y una vez que este realiza su trabajo se procesan los píxeles de manera que cada núcleo ha trabajado una parte del tiled distinta según la complejidad de la misma, dando como resultado una optimización del tiempo y del cálculo.
Las ventajas de las tiled por núcleo en las GPU Intel MCM
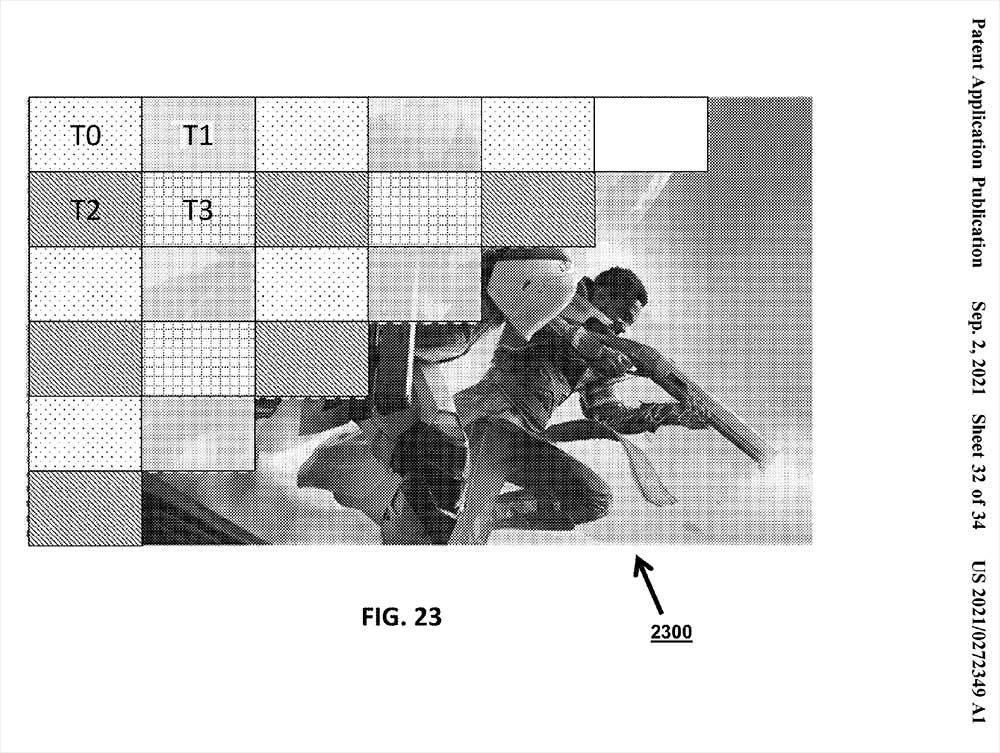
Lógicamente el motor de renderizado y la complejidad de las asignaciones logran que la escalabilidad aumente según se añaden matrices a la ecuación, es decir, aunque el sistema sea complejo si el motor de renderizado permite escalar casi al 100% a mayor número de dies/núcleos entonces no encontraremos límites de rendimiento como tal.
Esto evidencia que Intel tiene las bases muy asentadas y que el futuro es sin duda múltiples dies además de múltiples interposer, donde el número de núcleos irá escalando progresivamente y ya no hablaremos de Shader como la unidad de escalamiento como tal, sino como una unidad más de renderizado donde lo importante será su número total en base a los núcleos que la GPU posea.
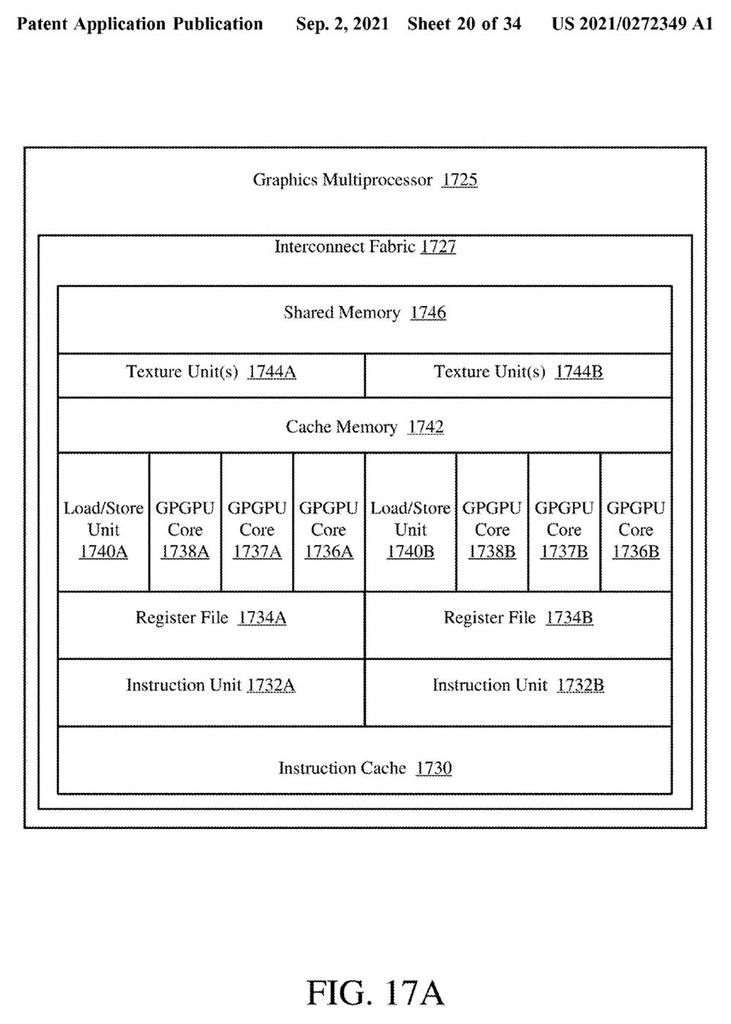
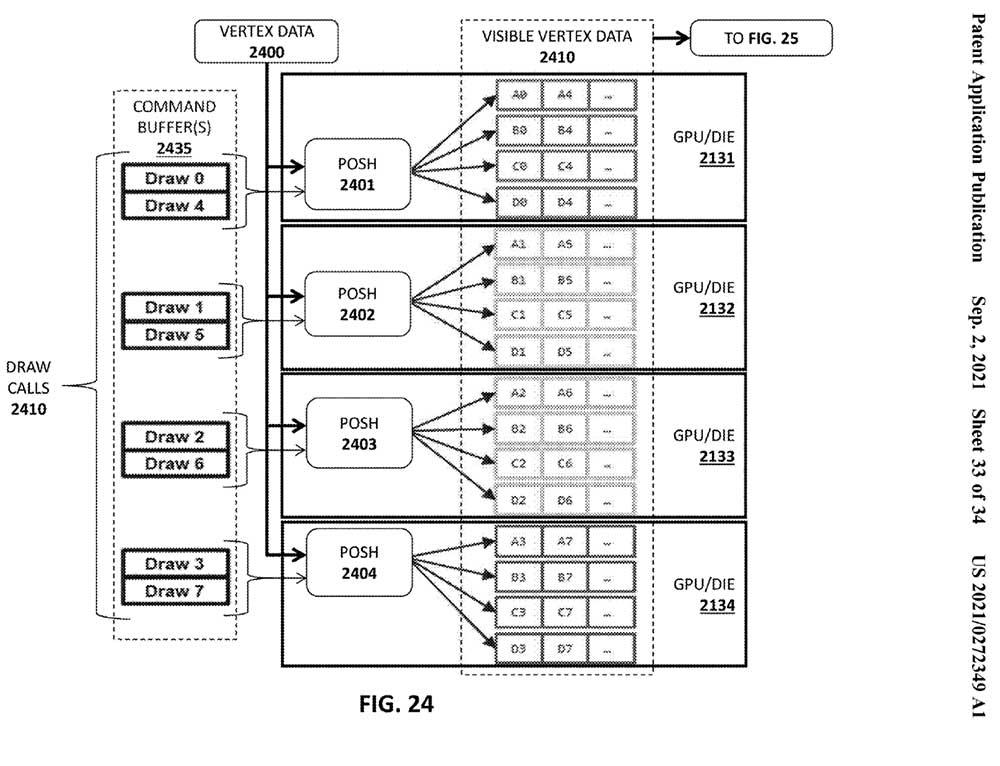
En definitiva, Intel va a segmentar la pantalla, la imagen global frame por frame en Tiled, donde cada una de ellas será trabajada por fragmentos que serán mayores o menores según el número de dies que tenga la GPU y al mismo tiempo, cuantos más núcleos tenga un die más divisiones tendrá cada Tiled, logrando completar una tarea muy costosa en tantos fragmentos como el hardware permita, de menor complejidad total y aportando mayor velocidad por cuadro.
Una apuesta arriesgada que lleva no uno, sino varios pasos más allá la tecnología Tiled que implementó NVIDIA como modo de renderizado, todo gracias al enfoque que utilizará Intel con MCM en sus GPU.