
En los últimos días varios se ha hablado de las NVIDIA RTX 50 en los mentideros de la red, cuyas fuentes suelen ser de forma indirecta foros sobre hardware, pero con la misma fiabilidad de un reloj roto, de tanto en cuando la aciertan. Sin embargo, todavía es demasiado pronto para hablar de ellas y os vamos a explicar el motivo.
Todavía quedan casi dos años para las RTX 50, por lo que hablar de cifras de rendimiento y cosas así es una tontería, ya que no lo sabe ni la propia NVIDIA a estas alturas. Sin embargo, analizando como es la arquitectura de las RTX 40, los elemento que en el chip H100 no han podido añadir y ciertas tecnologías venideras, pues nos podemos una idea de como pueden ser desde un punto de vista lógico y realista.
Ampere Next Next
Mucho antes de que el nombre Lovelace sonase como nombre en clave para las RTX 40, NVIDIA publicó un mapa de ruta cuanto menos curioso, donde las RTX 30 aparecían nombradas como ‘Ampere’, las RTX 40 bajo el nombre ‘Ampere Next’ y las RTX 50 como ‘Ampere Next Next’. Fuera de bromas, no es que les faltasen científicos para darle nombre a las nuevas arquitecturas, pero la salida de las RTX 40 nos los ha confirmado.
Lo que define toda GPU son sus núcleos, en NVIDIA estos son los llamados SM, los cuales están compuestos también por los subnúcleos. Pues bien, hay más diferencia de RTX 20 a RTX 30, que de RTX 30 a RTX 40, donde lo único que se ha hecho es realizar cuatro cambios en los ‘Tensor Cores ‘y añadir un RT Core nuevo con más capacidades. ¿El resto? Se ha mantenido igual y se espera que lo haga respecto a las RTX 40.
Esto, junto al salto de los 8 nm de Samsung a los 4 nm de TSMC, es lo que permite una RTX 4090 con 144 núcleos SM en el chip, aunque 128 activos. ¿Podría haber sido más alto el número de núcleos? Pues sí, pero hemos de partir que la RTX 4090 usa la misma cantidad de memoria que la RTX 3090 Ti y, por tanto, tiene menos por núcleo disponible.
¿Qué cambios esperamos ver en los SM de las RTX 50?
Fuera de lo especificado en la siguiente lista, el resto de elementos continuarán como hasta el momento.
- Tensor Cores
- RT Core
- El planificador o ‘Warp Scheduler’ que lleva sin renovarse desde las RTX 30. Lo hará para adoptar ciertos cambios de CUDA9.
- Esto supone cambios en las cachés de primer nivel: datos e instrucciones. Así como en la memoria local de cada SM.
Los rumores hablan de una renovación de los SM después de un largo tiempo. Nosotros no lo creemos y más bien confunden la implementación de conceptos vistos en el chip H100 que no se han implementado en los chips AD10x de las diferentes RTX 40.

¿Tendrán las RTX 50 tanta caché como las actuales?
No, no hemos cambiado de tema ni se nos ha traspapelado otro artículo, sino que para entender como puede ser la NVIDIA RTX 50 hemos de entender este cambio en la generación actual, a que se debe y si hay visos de verlos en la próxima generación.
- Para empezar el hecho estrechar el bus de memoria respecto a lo necesario para no terminar teniendo un chip más grande, ya que el coste por oblea es mayor y son menos mm² los que tienen disponibles respecto a la generación anterior y por desgracia las interfaces de memoria no escalan con los nodos de fabricación de chips.
- El segundo motivo es que al recortar el bus nos encontramos con una anemia en el ancho de banda. ¿Lo mejor? Aumentar la caché L2 para que estos tengan menos probabilidades de acceder a la RAM de vídeo, en todo caso tienen un límite en ese caso, tanto en espacio en el chip como en latencia.
- El tercer motivo es que colocar más núcleos aumenta las exigencias de cara a la memoria. Si bien tenemos disponibles GDDR6X a 23 y 24 Gbps. Si NVIDIA todavía no las ha lanzado es por el hecho que no se atreven por el momento a lanzar una tarjeta gráfica con un TDP de 600 W y esto se tiene que deber a algo, posiblemente por el hecho que no se fían del todo de sus mecanismos de refrigeración para consumos tan altos.

Entonces, ¿Podemos saber como serán las RTX 50?
A estas alturas solo lo sabe NVIDIA, pero podemos hacer una serie de predicciones sobre los cambios que vamos a ver. El principal de ellos será el uso de la memoria GDDR7 y creednos que incluso relanzando una RTX 4090 con interfaz para dicha memoria veríamos un aumento considerable del rendimiento en varios apartados a día de hoy limitados por el ancho de banda.
Si bien los 96 MB de caché L2 que tiene la configuración máxima del chip AD102 nos pueden parecer impresionantes, en el fondo son bastante anémicos para la enorme cantidad de datos que maneja una GPU de tal calibre como la de la RTX 4090, es por ello que es más que posible en una eventual RTX 50 de gama alta no veamos la misma cantidad de caché L2 en el chip, sino mucho menor con tal de adoptar una mayor cantidad de núcleos SM, aunque lo que nos interesa más bien es la comunicación interna, la cual sí que sabemos que cambiara.
CUDA9
Una de las diferencias más grandes entre H100 y AD102, es el hecho que la última es una GPU CUDA 8.9, debido a que no integra una serie de cambios que NVIDIA sí que ha añadido a su GPU para computación de alto rendimiento. Y no, no nos referimos a los núcleos SM que serán siempre diferentes entre ambos mercados, sino la forma en la que estos se comunican entre sí.
- El Tensor Memory Accelerator o TMA es una unidad que permite la transferencia y comunicación directa entre las memorias locales de los SM. No confundir con la caché y la memoria global compartida, la cual se encuentra dentro del chip y tampoco es una caché.
- Thread Block Cluster, el cual consiste en que varios SM compartirán tanto sus cachés L1 como sus memorias locales para trabajar en grupo.
Estos cambios, aunque menores, los veremos en los SM de las RTX 50, si o si, desde el momento en que dichas tarjetas gráficas van a tener que ejecutar dicha versión de CUDA.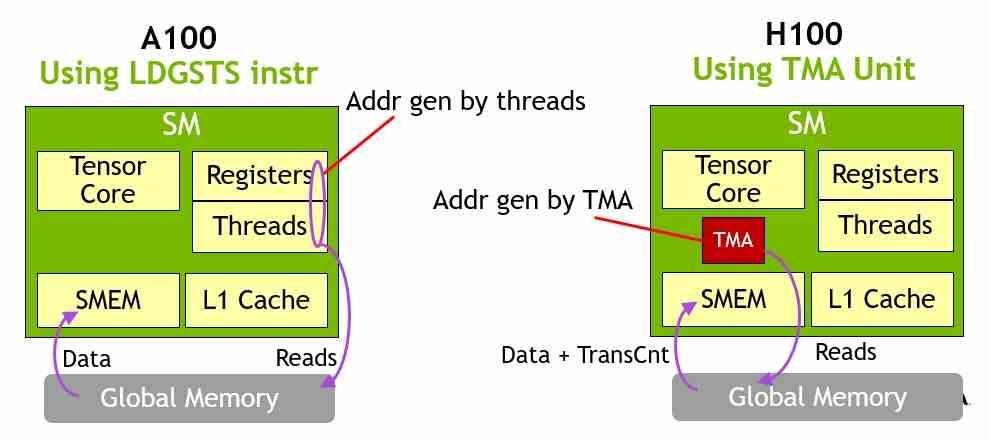
¿Y qué hay de los últimos rumores?
Se habla mucho de que veremos un bus de 512 bits de las RTX 50, lo cual dudamos por el hecho que eso sería hacer el chip más grande y caro de lo que ya puede llegar a ser. ¿La justificación para ello? El hecho de disgregar la GPU como ha hecho AMD, pero nosotros creemos que hacer esto solo tiene sentido si tu diseño si está en un solo chip supera el límite y durante años han procurado no superarlo, pero es que ese ya no es el problema, sino el coste asociado de hacer un chip tan grande.
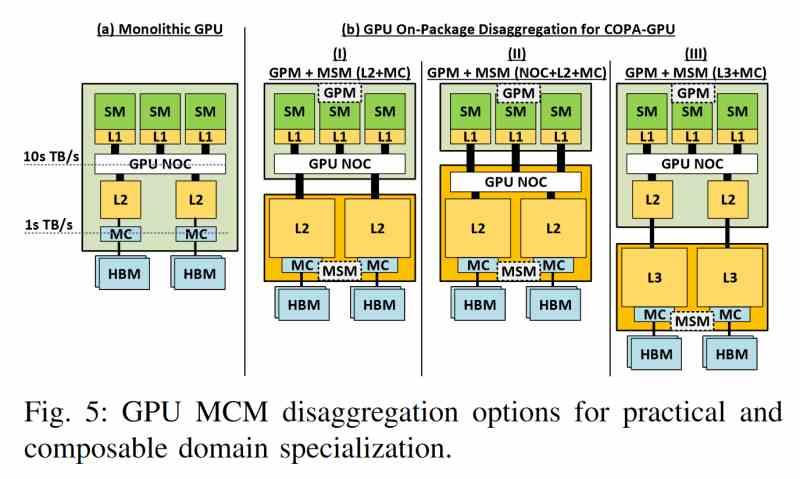
A día de hoy ni la propia NVIDIA se atreve a ello como hacía antes. ¿Cuál es el escenario más lógico? Pues el hecho de ir a una configuración de doble chip, en el que ambos tengan acceso a la misma memoria. Esto nos llevaría al añadido de una caché L3 y el controlador de memoria separado, todo ello en una configuración muy parecida a la de RDNA 3, pero no sería una copia desde el momento en que la propia compañía ya habló de la idea en su documento COPA. Algo que NVIDIA tendría acceso, desde el momento en que es cliente de TSMC. En todo caso, los diferentes elementos deberán estar encima de un Interposer para reducir el coste energético de la transferencia de datos.
Conclusiones, por el momento
En resumidas cuentas, la cosa quedaría, por el momento, en lo siguiente:
- RTX 50 añadiendo cosas de las H100 que son útiles para gaming y que no se añadieron en la actual generación.
- Buscarán que sea más eficiente, para ganar mayores velocidades de reloj.
- El mayor Boost vendrá de la GDDR7, que traerá mayor capacidad y ancho de banda, dos elementos en los que las RTX 40 están faltas.
Fuera de todo esto no vamos a ver ningún cambio importante, es más, es posible que el número de núcleos final no aumente tanto o ni tan siquiera aumente y el rendimiento venga por los elementos que os hemos dicho. El motivo de ello es que AMD si decide al final lanzar una tarjeta gráfica con una mayor cantidad de Compute Units es muy poco probable que supere la cantidad de núcleos que tiene la RTX 4090, por lo que NVIDIA no tiene necesidad de ello.