
Cada nueva generación de procesadores que estamos viendo en la actualidad viene con un mensaje concreto: esta CPU tiene un X% más de IPC. Por lo que se ha convertido en una medida para comparar procesadores, pero en este artículo no os hablaremos de que es el IPC, sino si existen limitaciones sobre el límite que se puede alcanzar y por qué.
El término IPC hace referencia al paralelismo de las instrucciones, es decir, a cuantas se pueden ejecutar simultáneamente, pero dicho paralelismo se ve limitado por una serie de factores. Seguid leyendo para saber cuáles son.
El IPC y su relación con el paralelismo de instrucciones
El IPC se ha convertido en la medida de rendimiento explotada por el marketing de los diferentes fabricantes de CPUs, el cual hace referencia a la media de instrucciones que un modelo concreto de CPU o una arquitectura puede alcanzar. Normalmente medida a través de un benchmark concreto para hablar de cuanto ha mejorado dicha CPU respecto a un diseño más antiguo o cuanto de mejor es respecto a la competencia.
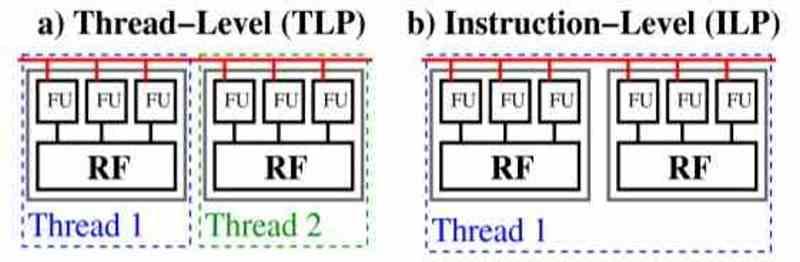
Pero la cantidad de instrucciones en paralelo que se pueden ejecutar no va a crecer sin parar eternamente y hay una serie de elementos dicho de los propios procesadores que limitan el rendimiento de una CPU a la hora de ejecutar varias instrucciones al mismo tiempo. Aquí tenemos que aclarar la diferencia entre paralelismo a nivel de instrucción o ILP y paralelismo a nivel de hilo de ejecución o TLP. Siendo el primer tipo el utilizado en el diseño de las CPU y el segundo tipo más típico de las unidades shader de las GPU.
Cuando hablamos de ILP nos referimos a explotar las instrucciones implícitas en una misma o rama del código y que por tanto tienen interdependencias entre ellas. En cambio cuando hablamos de TLP estamos hablando de ramas de código independientes entre sí, las cuales se pueden ejecutar en paralelo y por tanto de manera no coordinada con los otros hilos de ejecución. Es por ello que los fabricantes como Intel y AMD hacen uso del IPC al referirse del aumento del rendimiento de sus CPU en monohilo.
¿Qué elementos provocan el límite del IPC en un procesador?

Un procesador no es más que un circuito integrado de una alta complejidad, en la que los electrones recorren su estructura de una manera u otra según cuál sea la instrucción que están ejecutando. Dicha estructura está formada por una cantidad de transistores que combinados forman las puertas lógicas y memorias internas del procesador, por lo que los diseñadores se ven limitados a la cantidad de transistores que van a utilizar.
Incluso hoy en día, con nodos de fabricación que permiten utilizar miles de millones de transistores en el diseño de una CPU nos encontramos con partes que son compartidas por varias instrucciones. Eso significa que cuando esas instrucciones funcionan al mismo tiempo en paralelo, la parte en común no se ejecute en paralelo. Lo cual se traduce en que cuando se están ejecutando dichas instrucciones el IPC se reduzca. ¿La solución? En diseños posteriores añadir nuevas partes en el procesador que impidan la contención de ciertas instrucciones entre sí.
Esos puntos en comunes son muchas veces el uso de registros internos en el procesador, siendo una de las trampas más comunes la creación de duplicados de cada uno de los registros comunes de un conjunto de registros e instrucciones, que son invocados cuando el registro principal está siendo ocupado por otra instrucción.
La unidad de control y el límite del IPC
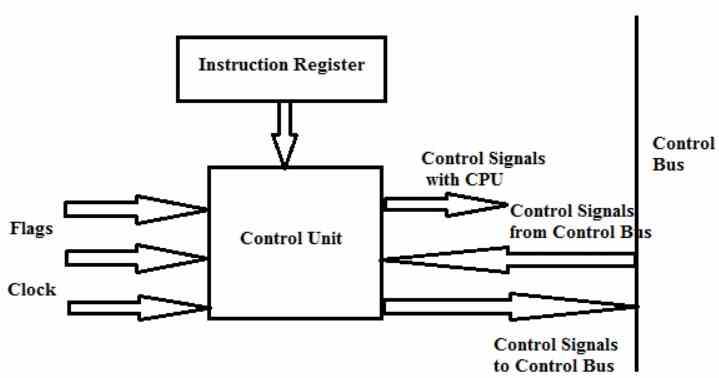
El otro punto limitante es la unidad de control, por dos motivos. El primero de ellos es el tiempo que se tarde en descodificar las instrucciones, lo cual puede llevar a que instrucciones posteriores se vean retrasadas. Un truco común para alcanzar grandes velocidades de reloj es alargar el pipeline de cada instrucción, pero esto puede llevar a un alargamiento excesivo del tiempo de captación y descodificación de las mismas.
En cuanto al segundo motivo tiene que ver con una serie de parámetros que no siempre son perfectos en un procesador, y cuyos fallos añade mayor latencia a las instrucciones, los cuales son los siguientes:
- La localización de los datos a manipular por las instrucciones en las cachés, donde la búsqueda infructuosa de los mismos por toda la jerarquía de cachés añade ciclos de reloj adicionales a la ejecución de la instrucción.
- Una mala predicción de saltos, ya sea en un salto simple o condicional afecta también negativamente el rendimiento a la hora de ejecutar varias instrucciones.
- Los registros de acceso a memoria y de datos sobre memoria crean contención si hablamos de un controlador de memoria con pocos canales.
Es por ello que en cada nueva arquitectura también se busca aumentar el rendimiento de las cachés, de las unidades de protección de saltos y de todo el mecanismo de acceso a la memoria con tal de aumentar de superar el límite del IPC de una generación de procesadores a otra.