
Intel desveló bastantes nuevos detalles sobre sus gráficas dedicadas Xe HPG durante el Intel Architecture Day 2021, incluyendo una hoja de ruta completa. La primera familia de GPU dedicadas de Intel tiene por nombre Alchemist, y aterrizará durante el primer trimestre de 2022 seguida de Xe2, Xe3 y Xe NG, con nombres Battlemage, Celestial y Druid respectivamente. Al mismo tiempo, las GPU Ponte Vecchio para servidor también han sido anunciadas, con hasta 45 TFLOPS de potencia, y en este artículo os lo contamos todo sobre ellas.
Está sucediendo: Intel está dando un gran golpe sobre la mesa al mercado de juegos, llevando la lucha por fin al mismo nivel que NVIDIA y AMD. La GPU dedicada Intel ARC Alchemist implementa la arquitectura gráfica Xe HPG y ofrece compatibilidad total con DirectX 12 Ultimate, así como otras características contemporáneas como XeSS (supermuestreo por IA que rivaliza con NVIDIA DLSS y AMD FSR) y mucho más, así que vamos a ver qué es lo que Intel nos ha contado al respecto.
Las GPU Intel Alchemist, bajo el nodo de 6 nm de TSMC

Según Intel, han definido un nuevo bloque de construcción de ordenadores que sirve como base para la arquitectura Xe como parte de este cambio. También han aprovechado la oportunidad para actualizar algunos de los nombres para dejar de hablar de unidades de ejecución; se estaban volviendo demasiado grandes para ser razonables, y los cambios generacionales dificultaban las comparaciones.
Así pues, Intel ha presentado los núcleos XE, que incluyen unidades aritméticas eficientes, cachés y lógica de almacenamiento de carga. Las unidades aritméticas incluyen motores para operaciones tradicionales de punto flotante, vectores enteros junto con motores de aceleración, convolución y operaciones matriciales que se encuentran normalmente en cargas de trabajo de IA.
Así pues, Intel ha decidido cambiar el nombre de la unidad de ejecución a una nomenclatura más técnica todavía. En lugar de EU, Intel ahora utiliza el siguiente estándar: la unidad básica de las GPU Xe Alchemist tendrá 16 motores vectoriales (256 bits) y 16 motores matriciales (1024 bits), formando un Xe Core. Cada uno de los Xe Cores tendrá su propio Sampler, Geometry, Caché y un Pixel Backend compartido; 4 núcleos Xe forman un segmento de renderizado, y cada uno también tiene su propia unidad de trazado de rayos.

La primera iteración de la GPU Intel Xe HPG tendrá 8 «partes» como veis en la diapositiva de arriba, cada una de ellas con 4 núcleos Xe. Esto constituye un recuento total de vectores / matrices de 512 (8x4x16), y sí, eso es exactamente lo que hasta ahora conocíamos como EU. Suponiendo que la arquitectura base es la misma (debería serlo), todavía estamos hablando por lo tanto de 4096 ALUs (512×8) en las GPU Intel Alchemist.
Además, TSMC ha confirmado que las GPU Intel Xe HPG se fabricarán en su litografía de 6 nm, lo cual debería darles una gran ventaja en términos de eficiencia energética y densidad de transistores. Esto también significa que es bastante probable que cuando se lancen al mercado lo hagan con un gran volumen de stock, puesto que TSMC no tiene problemas en sacar producción en masa de este nodo.
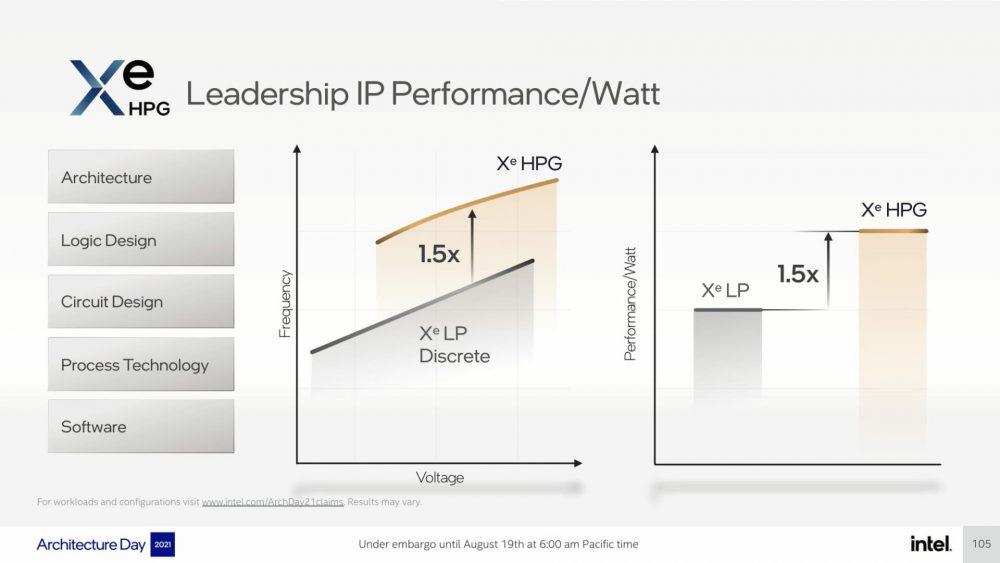
En principio, la arquitectura Xe HPG de Intel que veremos estrenada en las GPU Gaming «Alchemist» podrá alcanzar velocidades de reloj hasta 1,5 veces más elevadas de lo que vimos con Xe LP, ofreciendo a su vez un rendimiento por vatio también 1,5 veces superior. Esto significa que veremos velocidades de funcionamiento del rango de 2,1 GHz considerando que las GPU dedicadas Xe LP funcionaban a 1,4 GHz, así que podríamos estar hablando de un verdadero rival para AMD y NVIDIA en el mercado de las tarjetas gráficas para juegos.
Intel Ponte Vecchio para servidores, con 45 TFLOPS de potencia

Además de hablar sobre sus próximas y esperadas GPU Gaming Alchemist y demás, Intel también habló durante su Architecture Day 2021 de las GPU para servidor, un entorno dominado completamente por NVIDIA en la actualidad pero que, con las cifras que ha presentado Intel, desde luego pone en peligro su hegemonía.
Ponte Vecchio ya ha logrado sobrepasar la barrera de los 45 TFLOPS de rendimiento de cómputo de precisión simple en su versión actual de silicio A0; estamos ante un acelerador para centros de datos que supone el primer procesador basado en Xe-HPC que presenta un diseño en múltiples mosaicos, que incluye Compute, Rambo, HBM y EMIB con un total de 47 mosaicos con 100.000 millones de transistores.
Al igual que en las GPU que hemos visto antes, el Xe-HPC Xe Core es el componente básico de estas GPU, y cuenta con 8 motores vectoriales y 8 motores matriciales. En comparación con Xe-HPG, Ponte Vecchio tendrá menos motores pero operará con buses mucho más anchos: 512 bits y 4096 bits respectivamente (para HPG, esas cifras son 256 y 1024 bits).
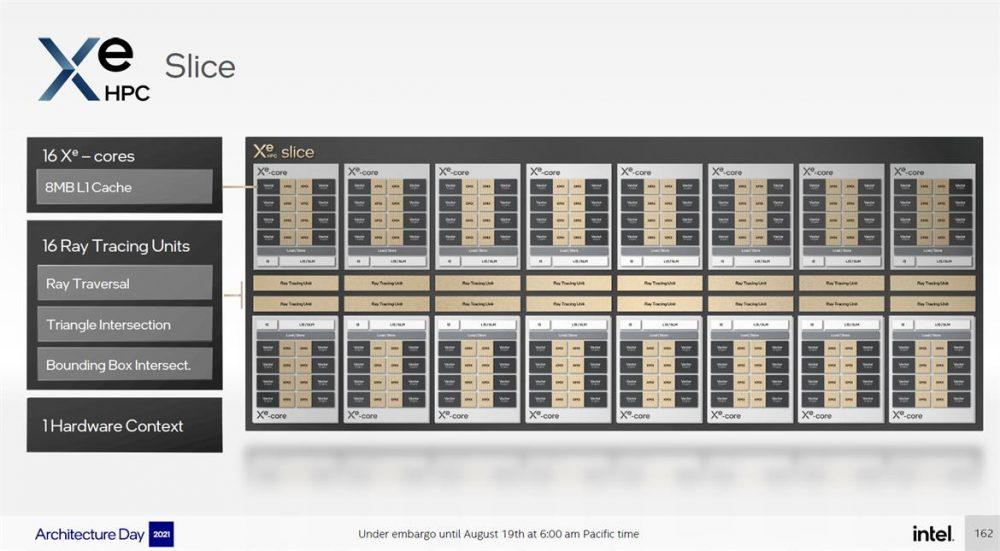
El Xe-HPC Slice es el bloque de construcción principal de estas GPU, que combina 16 Xe Cores. Lo que podría ser interesante es el hecho de que Ponte Vecchio está equipado con unidades de trazado de rayos, a pesar de que no es una GPU orientada al gaming. Al igual que HPG, cada Xe Core está vinculado a una sola unidad Ray Tracing, y los propósitos de estos núcleos se han enumerado en la diapositiva oficial como Rayos Transversales, intersección triangular e intersección de cuadrado delimitador. Ser un acelerador para servidores significa, por supuesto, que no están diseñados para juegos.
Intel se suma a la memoria HBM2e

Ponte Vecchio estará disponible en configuraciones de 1 y 2 pilas, lo que significa especificaciones de hasta 8 núcleos, 128 Xe Cores y 128 unidades de trazado de rayos. La configuración de 2 pilas tendrá nada menos que 8 controladores de memoria HBM2e.
La GPU Intel Ponte Vecchio cuenta con 5 nodos de proceso diferentes, lo que lo convierte en uno de los aceleradores HPC más complejos del mercado, si no el que más. Esto puede tener cierto impacto en el suministro de GPU para servidor, ya que en el caso de que alguno de estos 5 proveedores experimente problemas de suministro, también lo harán estas GPUs de Intel.
Por cierto, que Intel compara estas GPU con el acelerador NVIDIA A100, y obtiene más del doble de rendimiento FP32 (45 TFLOPS vs 19,5 TFLOPS en la solución de NVIDIA). Se espera que estas GPUs hagan su debut formal a partir de 2022, pero la fecha exacta está todavía por definir.