Intel Cascade Lake 96 núcleos vs AMD EPYC Rome 128 núcleos: arquitectura y cuál rendiría mejor

Con la filtración que desvelamos ayer sobre la plataforma Intel Cascade Lake ya tenemos los primeros datos comparativos para enfrentarla a la todopoderosa AMD EPYC. Si bien ambos resultados son dos filtraciones, denotan que la guerra comercial entre los dos grandes de los procesadores va a estar muy reñida y que a falta de reviews correspondientes todo parece estar muy igualado.
Intel Cascade Lake VS AMD EPYC Rome

Este artículo va a ser enfocado desde los datos que se han filtrado de ambas arquitecturas, pero la realidad es que todavía quedan muchos datos que deben ser revelados para tener una visión más clara de todo el conjunto y plataformas.
Evidentemente no podemos hablar de lo que no sabemos ni se ha filtrado, y por supuesto no vamos a especular como tal. Pero lo que sí podemos hacer es ofrecer datos relevantes que, ya sea por un lado u otro, han sido revelados, algunos oficialmente y otros por medio de diversas fuentes.
Antes de comenzar con las arquitecturas haremos un breve inciso sobre las configuraciones existentes, ya que parece que muchos usuarios no lo tienen del todo claro y siempre es bueno refrescar la memoria para los más dados.
La plataforma Cascade Lake de Intel se compone de CPUS MCP, es decir, contienen dos dies por CPU. Cada procesador se compone de 24+24 núcleos para así hacer 48 núcleos por procesador, mientras que la plataforma acepta 2 sockets por placa base. Así, su configuración máxima por placa y rack será de 96 núcleos y 192 hilos como configuración máxima.
La configuración de AMD es más simple desde el punto de vista de la plataforma, cada CPU de AMD albergará 64 núcleos y al igual que Intel tendrán dos sockets por placa, haciendo un total de 128 núcleos y 256 hilos en su plataforma, siendo esta la configuración máxima.
Evidentemente, ambas plataformas son escalables y pueden ser instaladas en racks para mayor capacidad de cómputo, aunque tendríamos que ver cómo se conectan entre ellas, dato todavía no muy claro por ninguna de las partes.
Intel Cascade Lake

La arquitectura Cascade Lake se basa en la plataforma Purley y está diseñada como una actualización de la misma pero con ciertas mejoras implícitas. Contará con hasta 7 procesadores de la gama Xeon siendo estos:
- Xeon D: HT, TBT, AVX 512 (1)
- Xeon W: HT, TBT, AVX 512 (2)
- Xeon Bronce: AVX 512 (1), UPI (2) y escalabilidad hasta 2 plataformas.
- Xeon Silver: HT, TBT, AVX 512 (1), UPI (2) y escalabilidad hasta 2 plataformas.
- Xeon Gold 5000: HT, TBT, AVX 512 (1), UPI (2) y escalabilidad hasta 4 plataformas.
- Xeon Gold 6000: HT, TBT, AVX 512 (2), UPI (3) y escalabilidad hasta 4 plataformas.
- Xeon Platinum: HT, TBT, AVX 512 (2), UPI (3) y escalabilidad hasta 8 plataformas.
Todos los procesadores se fabrican en el proceso litográficos de 14 nm ++ de Intel y con distintas configuraciones como hemos visto más arriba. Al igual que tendremos varias configuraciones dentro de los procesadores, en cuanto a número de núcleos/hilos tendremos varias versiones distintas, pero en este artículo nos vamos a centrar a modo comparativo en la mayor, hasta 48 núcleos y 96 hilos con 12 canales de RAM DDR4.
En cuanto a seguridad se refiere, Intel ya ha desvelado las mejoras a nivel de hardware que traerán los Cascade Lake, siendo estas:
- Mitigaciones de hardware para CVE-2017-5715 (Spectre, Variante 2)
- Mitigaciones de hardware para CVE-2017-5754 (Meltdown, Variant 3)
- Mitigaciones de hardware para CVE-2018-3620 / CVE-2018-3646 (L1 Terminal Fault)
En cuanto a capacidades de memoria RAM estos procesadores podrán albergar hasta 1.5 TB de RAM por socket y 3 TB en total por plataforma.
Como ya avanzamos hace algunas semanas, Intel ha cambiado las matrices y los troqueles para diseñar 3 tipos de CPUs distintas en cuanto a concepto se refiere, albergando en estas 3 variantes todas las CPUs disponibles para su fabricación y que consta de los ya conocidos SoC: LLC, HCC y XCC.
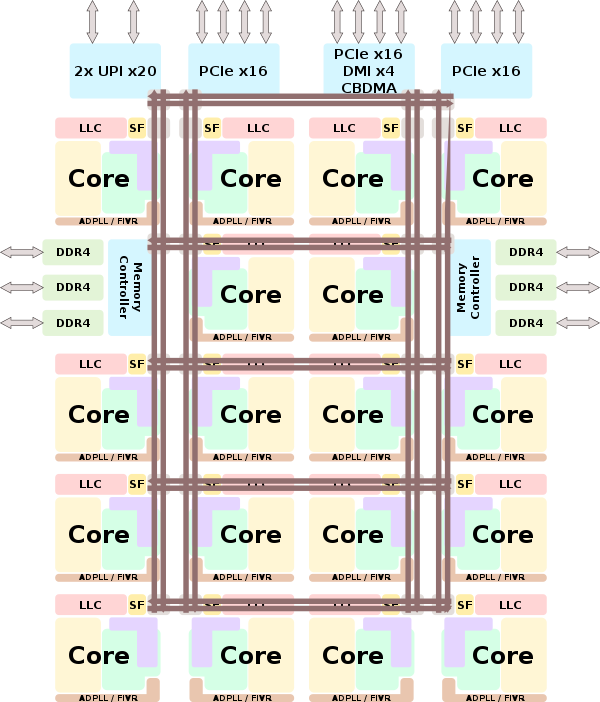
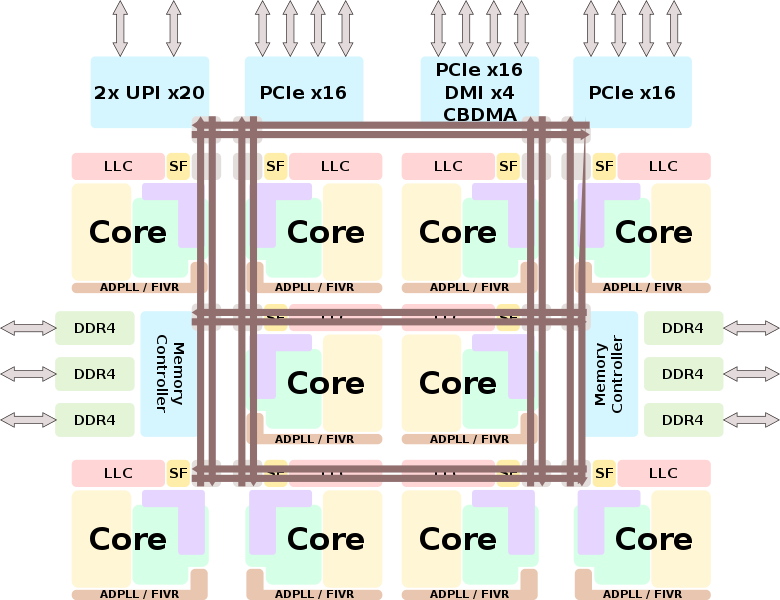
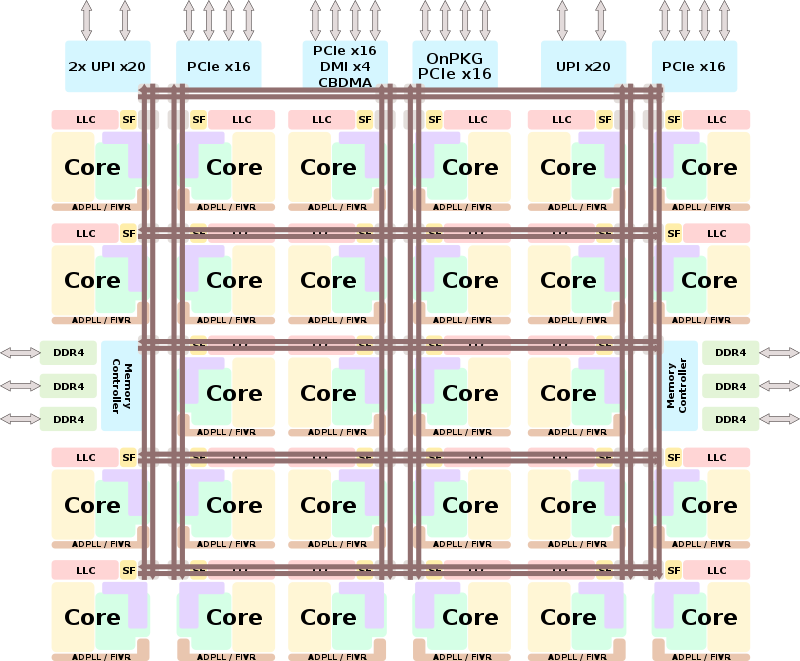
Las mejoras de la arquitectura en cuanto a nivel del front-end o back-end son prácticamente nulas, ya que como hemos dicho soy el siguiente paso a Skylake en servidor e Intel no ha interpuesto mejoras en dichos apartados.
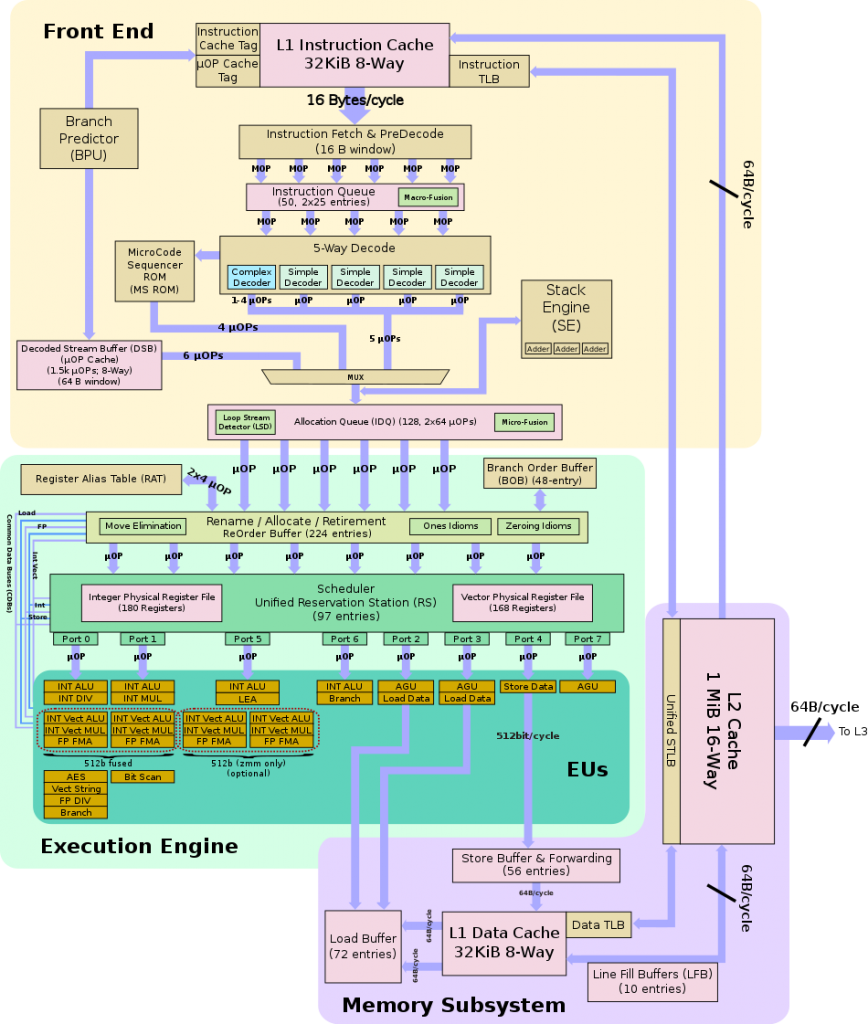
Debido a esto la jerarquía en cuanto a memoria es idéntica a lo ya visto, así que no nos detendremos demasiado y solo nombraremos lo más llamativo o determinante: máxima velocidad de RAM de 2666 MT/s, ancho de banda de 21.33 GB/s mínimo y máximo de 128 GB/s por die. Caché L1I compartida por todos los núcleos/hilos al igual que la L1D, caché L2 de 1 MB por núcleo, caché L3 hasta 1.375 MB compartidos en todos los núcleos.
Al ser Cascade Lake una evolución natural de Skylake comparte socket (LGA-3647) compartiendo pinout inclusive. No podemos olvidar su soporte para Optane DC DIMM de la propia Intel y 12 DIMMs gracias a su IMC Hexachannel (por die).
La configuración que ha realizado Intel por CPU es bastante curiosa, sobre todo si tenemos en cuenta que hace no más de un año criticó en AMD lo que ahora ha hecho.
El problema es que ha tenido que hacerlo debido a el retraso que ha sufrido su proceso litográfico de 10 nm, mientras que AMD ya tiene prácticamente listos sus CPUs con los 7 nm de TSMC, donde en menor espacio puede incluir más transistores y por lo tanto más núcleos.
Para poder competir hasta que sus 10 nm estén listos, Intel ha tenido que seguir la llamada configuración multi core processor o MCP. Esto no es más que disponer de varios dies dentro de una misma CPU, tal y como AMD lleva haciendo desde el principio con Ryzen y EPYC.
Así, Intel ha tenido que dotar a cada CPU de dos dies de 24 núcleos para hacer hasta 48 núcleos en una sola CPU. Para interconectar ambos dies usa un solo BUS que a su vez es de nuevo usado para conectar las dos CPUs en cada placa base.
Hablamos del Intel Ultra Path Interconnect o UPI, que viene a sustituir a QPI y que proporciona mayor ancho de banda, más eficiencia en el tratamiento de los datos y menor energía mientras que algún núcleo está en idle.

Esto supone usar, como hemos visto más arriba, hasta 3 UPIs en el caso de las CPUs de 48 núcleos, ya que cada CPU internamente usa una y la restante corre a cargo de la placa base.
De momento no está confirmado, pero es posible que Intel use dicho BUS en vez del PCI-e para comunicar distintas plataformas entre sí, ya sean 2, 4 u 8.
AMD EPYC Rome

En el caso de AMD, suponemos debido al hecho de la novedad en cuanto a su I/O die, los datos son menos cuantiosos por ahora, en el caso de Intel al ser una evolución natural todo está más claro y además ha dejado mucha información al respecto.
Pero en el caso de AMD no hemos tenido de momento tanta suerte, aunque se han filtrado varias cosas interesantes. La semana pasada hablamos de la batalla que de nuevo tienen AMD e Intel por los núcleos, recordando épocas pasadas y donde pareció haberse detenido por algunos años.
También hablábamos de la necesidad del diseño MCM por parte de AMD para ser más competitivo y al mismo tiempo reducir los gastos generados por CPU.
¿Qué ofrece AMD con sus nuevos EPYC Rome?
Lo primero un Front-end mejorado, como así pasó de Zen a Zen+, solo que en este caso las mejoras son mayores. Se ha reelaborado la unidad de predicción, con mejoras evidentes en el prefetcher y se han optimizado el sistema de jerarquía de las cachés y sus instrucciones.
Para mejorar el problema de las latencias, tanto en RAM como en las cachés, se han modificado la caché uOP y su tamaño se ha aumentado en más de las 2048 entradas existentes, todo dentro del cómputo de la L1I.
En cuanto al back-end, las unidades de punto flotante tienen importantes cambios en cuanto a FPU se refiere. En cada ciclo la FPU puede recibir 2 data charge de las unidades de carga y almacenamiento, debido a que dichas unidades de ejecución han pasado de 2 X 128 bits a 2 x 256 bits, es decir, el doble que en Zen y Zen+.
Esto supone que al tener 2 FMA de 256 bits, EPYC Rome podría alcanzar 16 FLOPs/ciclo e igualando en este apartado a Skylake/Cascade Lake.
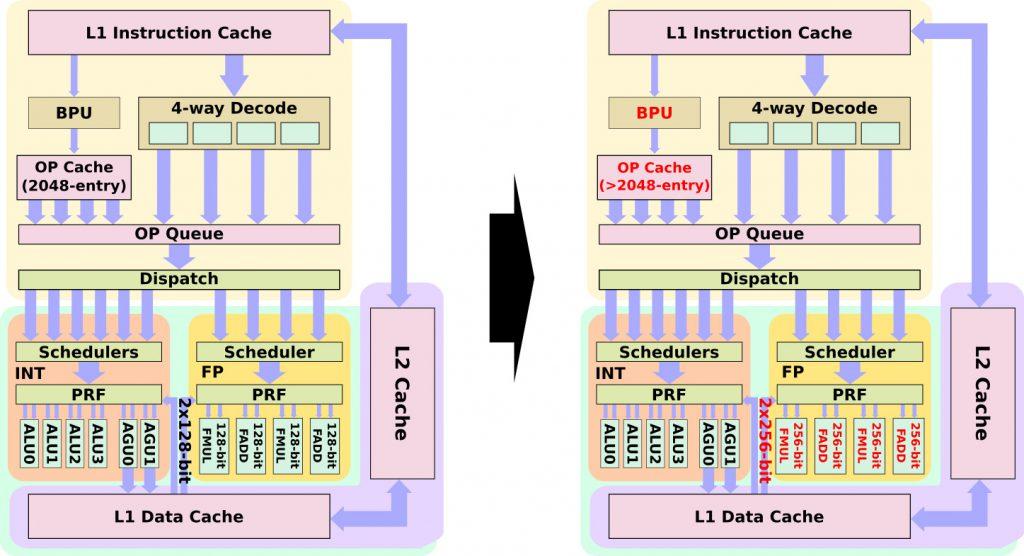
Esto debería reducir los problemas internos de latencias y aumentar el IPC. Otro detalle que sí sabemos es que AMD ha movido bloques de ejecución principales de los dies al troquel I/O die o E/S.
Dicho troquel es la pieza estrella de la nueva generación Zen 2 y viene construido a 14 nm por GlobalFoundries, ya que como decimos implementa muchas funciones que han sido llevadas hacia él.

De momento no sabemos mucho sobre este nuevo chip central con el que AMD pretende gestionar bastantes partes distintas y al mismo tiempo buses, pero lo que sí sabemos es que es totalmente paralelizable, ya que en teoría al ser un eje central todos los puntos deben tener las mismas latencias internas.
Esto mejora también las latencias entre back-end y front-end, donde ya no deberíamos ver accesos e instrucciones esperando una ruta más corta u óptima, tal y como hace Intel solo que aplicado desde la filosofía de AMD.
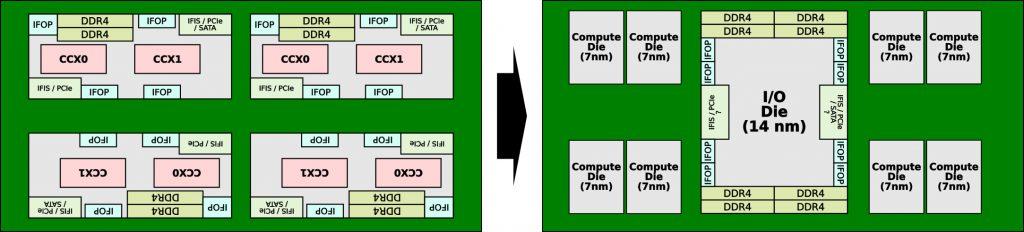
Para la interconexión de todos los dies, incluido el I/O, AMD ha hecho acopio de la última tecnología de TSMC llamada WoW o Wafer on Wafer y aunque no es una confirmación en sí misma, ya que no hay declaración al respecto, es totalmente lógico que sea fabricado así, pero veamos el por qué.
Para interconectar 8 dies o chiplets y el I/O die es necesario obtener diversas capas de silicio para dichas conexiones. TSMC creó para ello un intercalador que sería usado en todos los modelos MCM e incluso podría ser usado en monodie si la densidad del chip fuera muy alta.
El problema que se solventaba generaba otro mayor si cabe, las latencias. Para paliar dicho problema e ir reduciéndolo de cara al futuro TSMC usó los llamados TSV o Through Silicon Vias, que no son más que unos orificios de interconexión de 10 micrones que permiten que las obleas se toquen, permitiendo dicho intercambio y mejorando la eficiencia de paso.
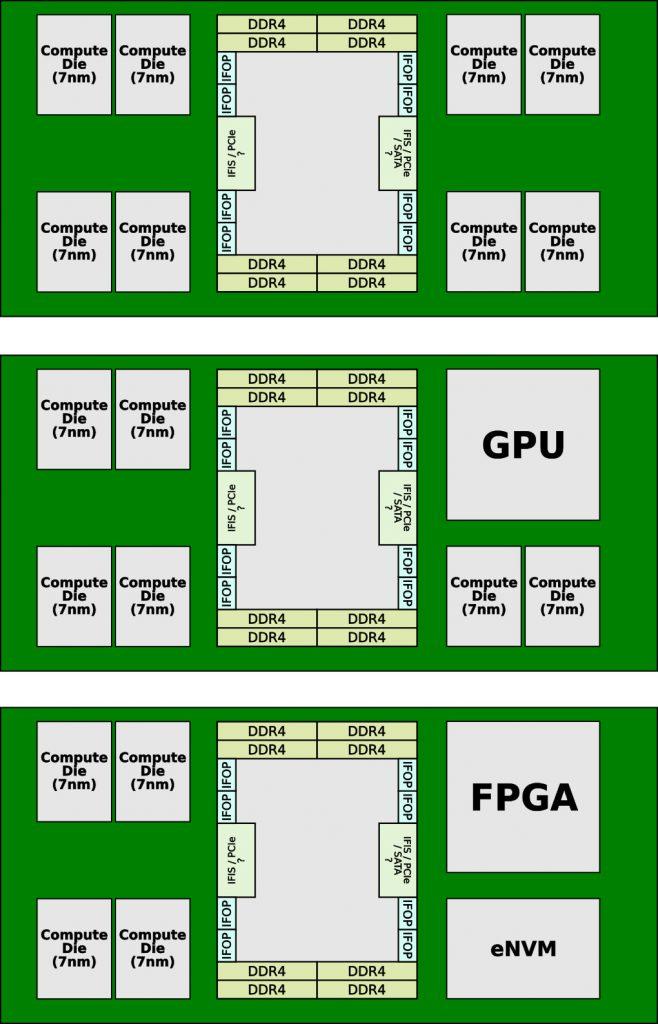
Así se consigue que por ejemplo, el I/O die pueda albergar PCI-e y Satas por ejemplo, pero además se conseguirán unos chips mucho más modulares a base de distintos troqueles. Por ejemplo podremos ver, si así AMD lo estima, chips con GPU o con sistemas NVMe en módulos independientes.
En diseño debe de ser más barato de fabricar que la opción escogida por Intel, aunque también ha venido forzada por la baja tasa de éxito que TSMC está obteniendo en chips de mayores tamaños. No es de extrañar que el I/O die venga en 14 nm, donde aparte es mucho más barato en cuanto a costos se refiere.
De momento esto es todo lo que podemos obtener de AMD hasta que por fín liberen más información o se filtre, pero ¿qué hay del rendimiento entre ambos?
La guerra del rendimiento parece mantenerse
Recordemos que ambas plataformas cuentan con dos sockets por placa base y que el recuento de núcleos en este escenario sería de 96 vs 128 y 192 vs 256 hilos, cifras realmente mareantes para el común de los mortales.
Si hablamos de rendimiento, hemos de enfocarlo desde los dos puntos de vista evidentemente, pero lo que de momento tenemos son dos filtraciones que ya publicamos y que deja a ambas plataformas al mismo nivel.
Ayer vimos a la plataforma Intel lograr 12482 puntos en Cinebench R15:
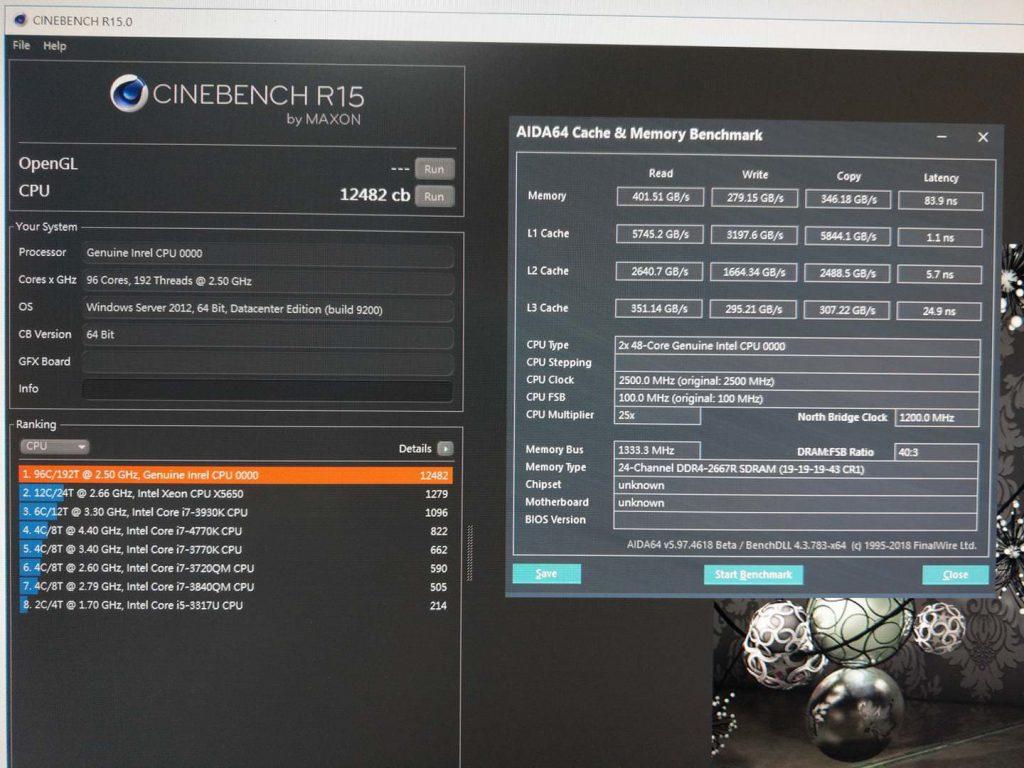
Y como ya apuntamos hace poco más de un mes, AMD antes hizo lo propio mostrando el potencial de EPYC Rome a través de una filtración desde Chiphell con 12587 puntos:
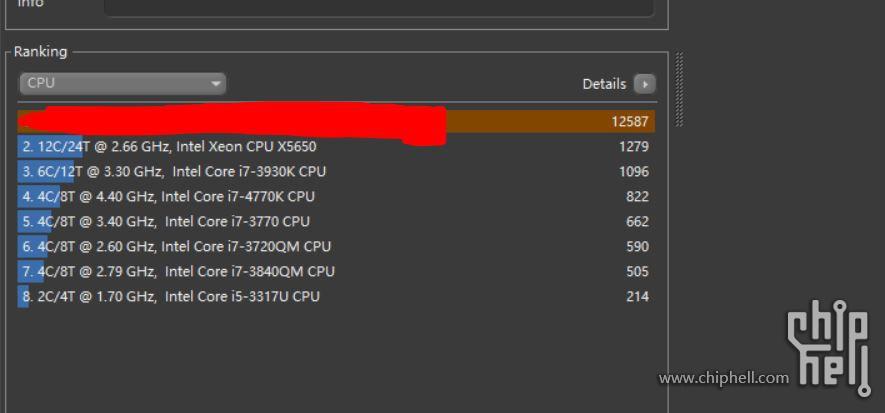
Además, ya se vio las primeras fotos de los samples de AMD con sus ocho canales de RAM.
Si el rendimiento fuera este, a tenor de ser un render muy válido y ser filtraciones, las palabras de Forrest Norrod quedarían en entredicho, ya que afirmó que EPYC Rome fue diseñado para competir contra Ice Lake de Intel, recordemos que a 10 nm.
Para ello desde AMD se tomó la hoja de ruta de Intel y se trazó el choque de trenes futuro, pero parece que Cascade Lake ha trastocado dichos planes, ya que vistas las declaraciones no van a competir con ellos.
Parece que el rival de Ice Lake será Milán, ya que de confirmarse estas filtraciones de rendimiento puede que Intel haya reaccionado a tiempo y tenga margen para seguir depurando sus 10 nm, cosa que hace solo unos meses era impensable viendo el potencial que va a desplegar AMD.
Lo que está claro es que AMD ha hecho forzar la máquina a Intel, ha llegado primero y ha vuelto a innovar. Quedará por ver duras batallas como WoW vs UPI, ver cómo se defienden con las mitigaciones por hardware y después cuál es el rendimiento final, sin duda va a estar interesante ya que Intel va a poder finalmente presentar batalla, cosa que no se esperaba realmente.
Faltan por supuesto datos de rendimiento en el entorno empresarial, aparte de muchos datos de la arquitectura de AMD por descubrir y que están celosamente bien guardados, así que estaremos atentos a cualquier filtración para mostrarlos.