
¿Es verdad que NVIDIA ha duplicado la potencia de los Shaders en sus nuevas gráficas de la serie RTX 30? ¿Como? Os lo explicamos en este artículo y disipamos de paso algunos mitos.
Una de las novedades que más sorprendieron durante la presentación de la arquitectura RTX 30 de NVIDIA es la afirmación de NVIDIA de que la cantidad de Shaders se han duplicado. ¿Hasta qué punto es verdad esto que dice NVIDIA? ¿Es una norma general o solo ocurre en momentos específicos?
¿Qué es realmente un núcleo en una GPU?
Un mito muy extendido por parte del marketing tanto de AMD como de NVIDIA es la confusión de las unidades encargadas de la ejecución de las instrucciones con lo que es un núcleo entero que sería el que lleva todo el ciclo de instrucción al completo.
Así pues NVIDIA ha llamado históricamente a las ALUs encargadas de ejecutar operaciones matemáticas bajo precisión de coma flotante de 32 bits como núcleos CUDA, lo que lleva a confusiones ya que cuando hablamos de CPUs, un núcleo completo es aquel capaz de realizar las tres etapas generales del ciclo de instrucción, el cual es llamado también el ciclo Fetch-Decode-Execute.
En las GPUs de NVIDIA la unidad completa que se encarga de un ciclo de instrucción completo es el SM. Esta unidad es común entre todas las GPUs de NVIDIA durante los años y ha ido sufriendo evoluciones con el tiempo y diversos añadidos. Una de las últimas evoluciones ha sido pasar a las 64 ALUs FP32 por SM que vimos en las NVIDIA Turing, tanto en las 20×0 como en la 16×0.
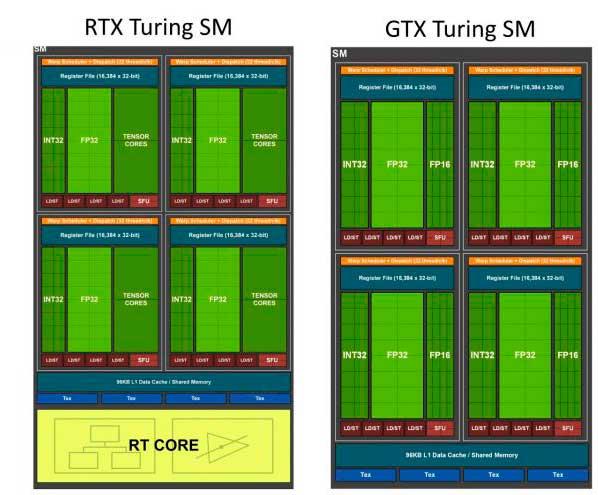
Mientras, en los SM en la gama RTX 30×0 las unidades FP32 se han duplicado llegando a un total de 128, pero esto no significa que se haya duplicado la potencia.
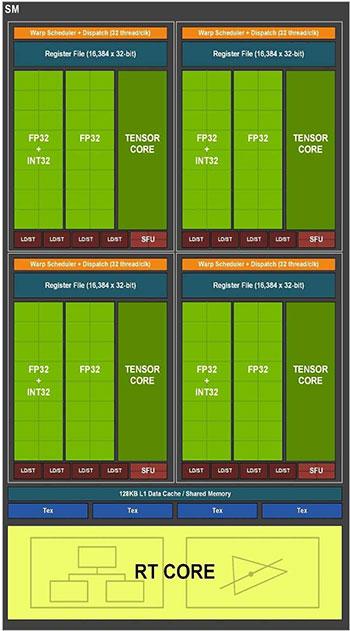
¿Se ha duplicado la potencia de los Shaders en las RTX 30?
Obviamente la realidad es que no todas las instrucciones de los diferentes programas Shader se van a ejecutar en las unidades de coma flotante, algunas de ellas lo harán en:
- Las ALUs de enteros (Int32)
- Las instrucciones de captación de datos utilizarán las unidades Load/Store (L/S en los diagramas).
- Algunas instrucciones matemáticas son ejecutadas en las SFU (Special Function Units).
- Obviamente no podemos olvidar los Tensor Cores que también se encuentran en el SM.
Cada tipo de instrucción tiene su métrica diferenciada. No obstante, el doble de operaciones en FP32 por ciclo de reloj tienen su trampa, ya que para poder operar las ALUs han de tener acceso a los registros y el problema es que el segundo conjunto de ALUs FP32 esta conmutado con las 16 ALUs Int32. Con conmutado nos referimos a que si se utiliza un tipo de ALUs para ejecutar un tipo de instrucción entonces las ALUs del otro tipo quedan inactivas y viceversa. Por ello, la ventaja de la RTX 30×0 respecto a sus antecesoras, que es tener el doble de unidades en FP32, solo sera visible en programas que hagan uso masivo de este tipo de operaciones.
¿Cómo se ejecutan los hilos de ejecución en el SM?
Para entender el motivo hemos de tener en cuenta que el SM tiene 4 partes iguales. Cada una de ellas simétrica; por un lado una unidad que distribuye 32 hilos entre los SM, 16 ALUs para el cálculo con enteros (Int32) y 32 ALUs para el cálculo en coma flotante (FP32). Todo ello teniendo como director de orquesta el llamado «Warp Scheduler» o Planificador de «Warps».
¿Que es un Warp? Pues un conjunto de hilos de ejecución agrupados. El planificador lo que hace es, como su nombre indica, planificar que hilos de ejecución y en qué orden se van a ejecutar en las ALUs del SM (Int32, FP32…), y envía cada hilo de ejecución a través de la unidad de Dispatch a los registros a un ratio de 32 hilos por ciclo de reloj.
Por otro lado, las ALUs que están también conectadas a los registros toman los hilos de ejecución que se encuentran almacenados en los registros y ejecutan los hilos de ejecución. Debido a que en las ALUs solo se pueden utilizar 32 registros por ciclo de reloj esto se traduce en que hay unidades que no van a ser utilizadas y esto lleva a que el segundo conjunto de ALUs en FP32 e Int32 estén conmutadas por falta de registros en los que operar dentro de cada sub-grupo del SM, ya que sin una memoria de apoyo desde la que leer los datos y escribir los datos una ALU no puede operar, y de ahí a que si se utilizan el segundo conjunto de ALUs en coma flotante no se pueden utilizar las de enteros y viceversa.
Para hacer un símil y simplificarlo al máximo, imaginad que tenemos un grupo mixto con 32 niñas y 16 niños que tenemos que ir turnando par ir dándoles clase pero solo tenemos 32 pupitres. Imaginad que cada instrucción es una clase y que a cada alumno se le da una clase distinta (hilo de ejecución). Por otro lado se ha decidido que 16 de las niñas tengan su pupitre asegurado por lo que los otros 32 tendrán que compartir los 16 pupitres (registros) restantes.
La conclusión es que el supuesto doble de potencia de la gama RTX 30 solo se da en ciertas circunstancias y por tanto no el 100% del tiempo