
Con la aparición de sistemas de empaquetado como Foveros de Intel y SoIC por parte de TSMC poco a poco las tecnologías que hacen uso de los llamados circuitos integrados o 3DIC van evolucionando, pero todas ellas tienen un punto en común. El uso de interconexiones en vertical para comunicar los diferentes elementos de estos potentes procesadores heterogéneos.
Uno de los mayores desafíos a la hora de diseñar un procesador es el consumo energético que se da al procesar la información y mover la información. El problema viene cuando en los últimos años todo el esfuerzo en ingeniería no se ha centrado en conseguir las unidades de ejecución más rápidas, sino que estás tengan la comunicación suficiente para que el procesamiento sea lo suficientemente rápido.
Independientemente de si un ordenador utiliza el modelo Harvard o Von Neumann se va a necesitar una memoria a la que accede el procesador para trabajar. En los sistemas más simples esta memoria se encuentra en un chip aparte y se ha de acceder a ella a través de una interconexión o cable. Pues bien, el gran problema aparece cuando tenemos en cuenta una serie de principios básicos.
El primero y más importante está en el hecho que la resistencia en un cable aumenta cuanto más largo sea, si tenemos en cuenta la Ley de Ohm sabremos que el voltaje es resultado de multiplicar la resistencia por la intensidad. ¿Qué tiene que ver esto con los semiconductores? No olvidemos que son circuitos eléctricos a pequeña escala y por tanto si aumenta la distancia a la que estén los datos a operar el consumo energético aumentará.
El motivo de ello lo encontramos en la fórmula básica para calcular el consumo energético, la cual es: P=V2*C*f. Donde V es el voltaje, C es la capacidad de carga que puede soportar el semiconductor y fes la frecuencia. Pues bien, hemos visto como el voltaje crece con la resistencia y hemos de añadirle que también crece con la velocidad de reloj.
Interconexiones en vertical
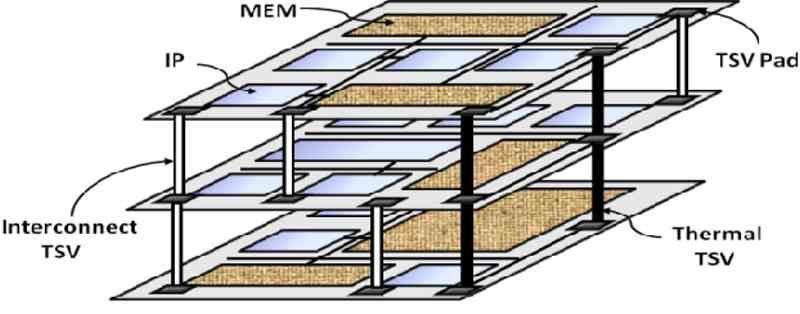
Ahora que tenemos el principio básico nos encontramos que la solución es acortar los cables para acercar la memoria al procesado. De entrada nos encontramos con una limitación y no es otra que la comunicación entre CPU y RAM se da en horizontal en el PCB y enrutando la interfaz de comunicación correspondiente a cada extremo, por lo que llegado a un punto no podremos continuar reduciendo la distancia.
Dado que el consumo energético aumenta exponencialmente con la velocidad de reloj, entonces la mejor solución es aumentar la cantidad de interconexiones existentes en la interfaz de comunicación, pero nos vemos limitados por su tamaño y dado que esta se encuentra en el perímetro del procesador esto significa aumentar el tamaño del mismo, lo que lo encarece en su fabricación. ¿La solución? Colocar dicha memoria arriba del chip, de tal manera que podemos tener un cableado en matriz.
Ambas cosas combinadas nos permiten aumentar la cantidad de interconexiones, lo que para conseguir el mismo ancho de banda nos permite reducir la velocidad de reloj, pero además tenemos la ventaja que hemos reducido la distancia del cableado de comunicación, por lo que reducimos también el consumo en ese punto. ¿El resultado? Reducir a un 10 % el coste energético del tráfico de datos.
El problema de la LLC y el consumo

En un diseño multinúcleo, estemos hablando de una CPU o una GPU, siempre hay una caché llamada LLC o de último nivel que es la más alejada del procesador, pero la más cercana a la memoria, su trabajo es:
- Dar coherencia en el direccionamiento a la memoria de los diferentes núcleos que forman parte de la misma.
- Permitir la comunicación entre los diferentes núcleos sin que lo tengan que hacer en la RAM, por lo que permite reducir el consumo.
- Les permite a los diferentes núcleos que forman parte acceder a un pozo de memoria común.
El problema viene cuando en un diseño decidimos separar varios núcleos entre sí para crear varios chips, pero sin perder la funcionalidad en conjunto para todos ellos. ¿El primer problema con el que nos enfrentamos? Al separarlos hemos alargado la distancia y con ello la resistencia del cableado, ergo el consumo energético ha subido como resultado.
Implementaciones de las interconexiones

Esto a ciertos niveles de consumo no es un problema, pero en una GPU sí que lo es y de repente nos encontramos que no podemos crear un procesador gráfico compuesto por chiplets utilizando los métodos de comunicación tradicionales. De ahí el desarrollo de intercomunicaciones verticales para comunicar los diferentes chips, lo que hace que se tengan que cablear en vertical con una base de intercomunicación común que le llamamos Interposer.
Los diseños basados en varios chips existen cuando es necesario llegar a un nivel de complejidad en el que el tamaño de un solo chip resulta contraproducente de cara a la fabricación y el coste del mismo, pero aquí las interconexiones en vertical se producen por lo general entre los diferentes elementos encima del interposer con este. Pero no resulta tan eficiente como una interconexión directa, debido a que también una relativa distancia de intercomunicación.

En cambio cuando hablamos de una implementación con un chip a pequeña escala se acaba optando por lo que es apilar dos o más chips uno encima del otro e intercomunicarlos en vertical. Estos pueden ser dos memorias, dos procesadores o la combinación de memoria y procesador. De ello tenemos ya varios casos en el hardware actual, como es el caso de la memoria HBM o la 3D-NAND Flash, el ya retirado del mercado Lakefield de Intel y los núcleos Zen 3 con V-Cache de AMD.
Por lo que el 3DIC no es ciencia ficción, es algo que tenemos ya desde hace varios años en el mundo del hardware y consiste en crear circuitos integrados en el que la interacción entre los componentes se haga en vertical en vez de hacerse en horizontal. Lo que trae consigo las ventajas que os hemos comentado antes acerca de las interconexiones en vertical de cara al consumo energético.