
Muchas veces estamos escuchando en los últimos tiempos, máxime por el uso de arquitectura ARM por parte de Apple y por Intel Foveros, sobre la arquitectura big.LITTLE en procesadores, donde coexisten núcleos «pequeños» de bajo consumo encargados de las tareas más livianas y núcleos «grandes» para desatar toda la potencia. Esta arquitectura por el momento solo la hemos visto en CPUs pero, ¿sería posible implementarla también en GPU para tarjetas gráficas?
El concepto de esta arquitectura es muy sencillo y a la vez eficaz: tenemos un DIE con dos tipos de núcleos, unos pequeños que siempre están activos y que se encargan de las tareas livianas como puede ser navegar por Internet o escribir en un Word, y otros núcleos más grandes y potentes, que normalmente están desactivados y a la espera de que se ejecute una tarea que requiera mayor potencia para activarse y hacerse cargo de todo.
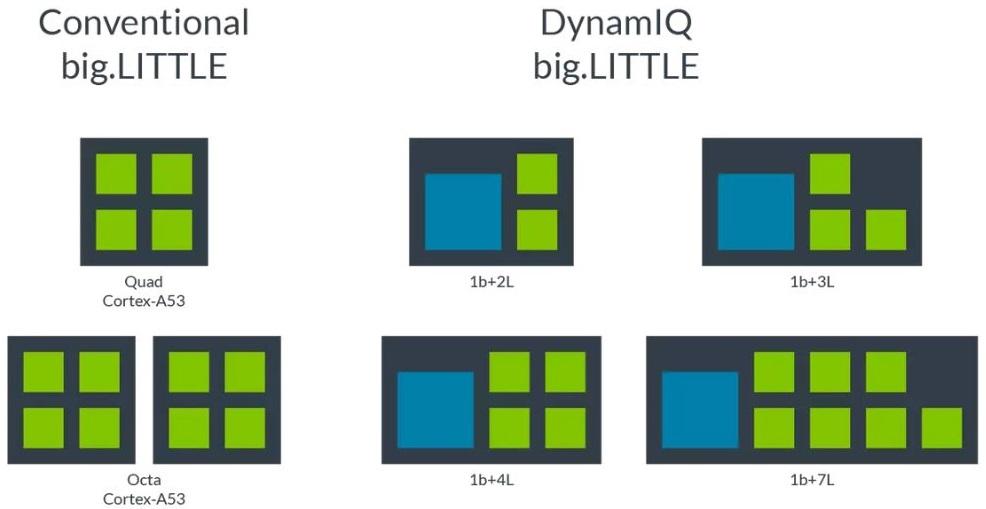
Repaso a la arquitectura big.LITTLE
Lo primero que debes saber de este diseño es que está enfocado enteramente a procesadores. Esta es una solución desarrollada por parte de ARM para los SoC que diseñan. Aprovechamos para recordar que ARM no fabrica chips, simplemente diseña y licencia estos diseños a terceras empresas. Hablamos de un diseño enfocado a smartphone y tablets que se ha visto tan bueno, que se esta copiando por otras empresas.
El nombre de big.LITTLE viene dado porque en un mismo DIE tenemos los núcleos de eficiencia (LITTLE) y los núcleos de potencia (big). Los núcleos de eficiencia se encargan de tareas sencillas, como cuando navegamos en el móvil o escuchamos música. Por otro lado, los núcleos de potencia están en reposo a la espera de activarse cuando hay carga, como puede ser cuando lanzamos un juego en nuestro smartphone.
Debido a lo polivalente de esta tecnología y lo eficiente que se muestra, está siendo copiada o imitada. Intel ya ofrece procesadores que combinan núcleos de eficiencia, que han denominado E-Cores y núcleos de potencia, que han denominado P-Cores. Además, la compañía se refiere a este diseño como «núcleos heterogéneos». Como entenderéis, básicamente es el mismo concepto que esta arquitectura big.LITTLE ya que funciona de igual manera, aunque obviamente no se llama así por temas legales.
AMD de momento no comercializa procesadores con esta combinación de núcleos, aunque sí que están desarrollándolos. El principio es exactamente igual a la de Intel y, por supuesto, a la de ARM. Por consiguiente, este tipo de tecnología ya es común en los procesadores modernos, al menos en los de Intel. Ahora bien, seguramente te estés preguntado si esta tecnología es posible escalarla a las tarjetas gráficas. Pues bueno, esto es algo que vamos a ver y explicar a continuación.
NVIDIA Optimus, ¿es similar a big.LITTLE?
Muchos de vosotros recordaréis los tiempos en los que casi todos los portátiles con GPU dedicada NVIDIA que contaban con tecnología NVIDIA Optimus. Esta permitía que, cuando estábamos en el escritorio o haciendo tareas que no fueran 3D, se utilizara la tarjeta gráfica integrada en el procesador para ahorrar energía, pero cuando ejecutábamos algún juego o tarea 3D entonces se tiraba de la gráfica dedicada para poder tener toda la potencia disponible.

Esta inteligente manera de aprovechar que el portátil montara dos GPU es, en esencia, una especie de big.LITTLE, pero en modo burdo (en lugar de ser toda una arquitectura), pero la idea es básicamente la misma: cuando no se necesita la GPU «grande» está desactivada y a la espera, con la iGPU haciendo todo el trabajo mientras pueda y ahorrando energía y reduciendo el calor generado. Cuando hace falta, la GPU «grande» entra en funcionamiento y entrega el máximo rendimiento.
Realmente este diseño es inteligente, ya que hace uso de un elemento que, normalmente, queda inactivo. Sobre todo se ve en sistemas de sobremesa, donde cuando conectas una gráfica dedicada, se desactiva la integrada del procesador. Algunos programas, como Photoshop o Premier en sus procesos de renderización, sí que permiten usar la iGPU para acelerar el trabajo.
¿Lo veremos en tarjetas gráficas?
Debes saber en primer lugar que hay enormes diferencias entre una CPU y una GPU. Las CPU comerciales cuentan con configuraciones entre 4 núcleos y 16 núcleos, mientras que una GPU cuenta con miles de núcleos. Para poner esto en contexto, una Radeon RX 6800 XT tiene 3.840 Shader Processors (núcleos), mientras que una RTX 3090 tiene la friolera de 10.496 núcleos CUDA.
Un mecanismo para esto sería implementar dos GPU en una tarjeta gráfica. Esto hace muchos años no era algo raro, es más, alguno igual recuerda la NVIDIA GTX 295 o la AMD Radeon R9 295X2. Debido al gran aumento de potencia de las GPU y de su consumo energético (así como generación de calor) estos diseños se han descartado para uso doméstico. Sí que es algo que se sigue viendo en entornos profesionales bastante a menudo.
Para una implementación total de esta arquitectura sería necesario redefinir la forma de trabajar de la GPU, puesto que actualmente ya tienen dos tipos de ALUs: una sirve para instrucciones simples y cuyo consumo es muy bajo, mientras que otras (las SFUs) se encargan de realizar las operaciones más complejas como raíces cuadradas, logaritmos, potencias y operaciones trigonométricas. No son núcleos big.LITTLE, pero de hecho ya se llaman diferente (ALUs FP32) precisamente por este motivo.
Realmente, y en cierta medida, podríamos decir que las tarjetas gráficas modernas ya son big.LITTLE. Podemos encontrar en una misma GPU diferentes tipos de núcleos para diferentes tareas. AMD integra los Shader Processors y los Ray Accelerators, estos últimos específicamente para el Ray Tracing. NVIDIA por su parte, complementa los CUDA Cores con los RT Cores para el Ray Tracing y los Tensor Cores destinados a la tecnología DLSS.
Así que ya lo veis, en realidad tanto antaño con Optimus como en la actualidad ya se implementa algo parecido a big.LITTLe en GPU. Lo único que cambia es que se denominan de manera diferente y su funcionamiento también es bastante diferente. No obstante, dado que en los últimos tiempos todo parece estar enfocado a la mayor eficiencia en cuanto al consumo, es algo que no podemos descartar, y desde luego tanto NVIDIA como AMD tienen potencial para poder llevarlo a cabo. Sería, desde luego, una situación ideal para ahorrar energía y generar menos calor, lo que siempre es una buena noticia.
La arquitectura heterogénea, ¿es el futuro?
Desde luego, parece ser a lo que se tiende. Los fabricantes de procesadores se han dado cuenta de que en los últimos años están mejorando el rendimiento de sus productos generación tras generación a base de fuerza bruta, es decir, sus procesadores son más potentes porque funcionan más rápido, y eso ha provocado que le digamos adiós a ese concepto de «eficiencia energética» del que tantos nos hablaban, porque el resultado es que los procesadores cada vez consumen más energía.

Todos los fabricantes de procesadores tienen diferentes gamas, empezando por la gama baja que suele ser de bajo consumo, y terminando por la gama alta que es la que más rendimiento ofrece. Como decíamos, se han dado cuenta de que se les estaba yendo de las manos eso de mejorar el rendimiento a base de fuerza bruta, y fabricantes como Intel lanzaron sus arquitecturas heterogéneas comenzando con Alder Lake, los Intel Core de 12ª Generación, que contaban con esos núcleos potentes pero también núcleos de bajo consumo.
La clave es hacer que, cuando el equipo está en reposo o realizando tareas livianas que no requieren de mucha capacidad de cómputo, los núcleos potentes están «a la espera» y solo funcionan los núcleos de bajo consumo, haciendo que el equipo funcione relativamente bien para lo que necesita, pero consumiendo poca energía. En el momento en el que el sistema necesita más potencia es cuando entran en funcionamiento los núcleos potentes, entregando todo lo que da el procesador y elevando el consumo… justo como la arquitectura big.LITTLE.
Así que sí, parece ser que las arquitecturas heterogéneas son el futuro de los procesadores, y aunque AMD todavía no ha lanzado modelos comerciales así es bien sabido que están en ello y que llegarán más pronto que tarde. Por ahora, y hasta que den con la forma de manejar adecuadamente la relación rendimiento / consumo, parece la forma más factible de seguir progresando.