
Quizá es una pregunta que puede que no te hayas hecho, puesto que todo se está centrando en NVIDIA con su Ray Tracing y DLSS, con su serie RTX y su arquitectura Turing, pero ¿podrá AMD soportar Ray Tracing y DLSS en sus nuevas GPUs? Es una gran pregunta, no por la pregunta en sí, sino por todo lo que ello conlleva en cuanto a desarrollo.
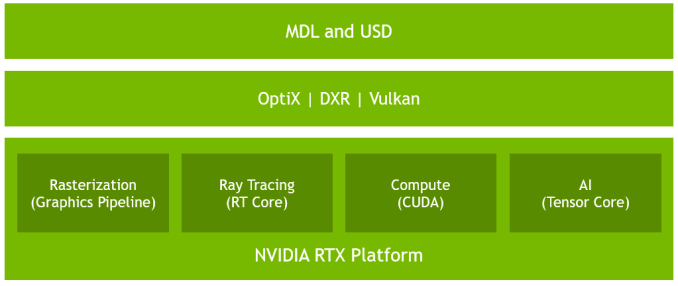
No puedo evitar empezar este artículo sin poner en contexto qué es Ray Tracing, DLSS, Tensor Cores y RT Cores, es imprescindible saber qué son, qué hacen y por qué son importantes para comprender la respuesta a este artículo, así que empecemos.
Ray Tracing o Trazado de rayos

Comencemos por la teoría básica, el Ray Tracing: el trazado de rayos es una técnica basada en el algoritmo de determinación de superficies visibles de Arthur Appel denominado Ray Casting (1968) para renderizar gráficos 3D con modelos de iluminación complejos y más naturales, para lograr imágenes de calidad cinematográfica y un nivel de realismo casi fotográfico que no es práctico con las técnicas gráficas tradicionales.
Hasta la fecha, el trazado de rayos se ha utilizado en aplicaciones especializadas, como efectos especiales y películas de animación, diseño industrial, modelado mecánico y arquitectónico para crear imágenes realistas y fotorrealistas.
Teoría asimilada, para entender mejor el Ray Tracing hemos de volver un poco al pasado, a sus inicios comerciales, de la mano de Imagination Technologies hasta llegar a su PowerVR GR6500, presentado allá por el 2014 y que hizo su debut en el CES de 2016.
La familia de GPUs PowerVR Wizard por aquel entonces ofrecía rastreo de rayos de alto rendimiento, gráficos y computación para dispositivos móviles y sistemas integrados. El diseño se basaba en PowerVR Rogue de cuarta generación con cuatro clústeres que incluían:
- Gráficos completos y rendimiento informático: cuatro Unified Shading Clusters (USC), con 128 núcleos ALU que entregaban más de 150 GFLOPS (FP32) o 300 GFLOPS (FP16) a 600 MHz
- Rendimiento del trazado de rayos en el mundo real: hasta 300 MRPS (millones de rayos por segundo), 24 mil millones de pruebas de nodos por segundo y 100 millones de triángulos dinámicos por segundo a 600 MHz
- PowerGearing G6XT para administración de energía avanzada y asignación dinámica de recursos
- Tecnologías de triple compresión PVR3C ™ (PVRTC y ASTC para compresión de texturas, PVRIC para compresión de búfer de cuadros, PVRGC para compresión de geometría)
- Soporte Deep Color para una calidad de imagen muy alta en resoluciones Ultra HD y más allá.
Además, tenía soporte de Open GL 3/2/1, DX11 y 10_0, Open CL 1.2 y Open RL 1.x
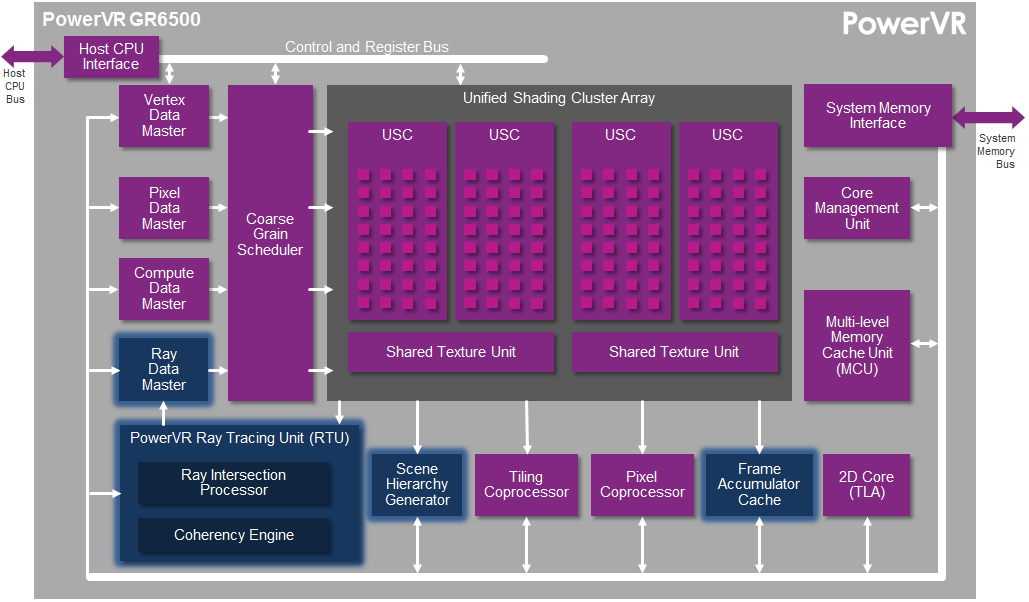
Sin ahondar más en este PowerVR GR 6500, siempre es bueno saber desde donde viene una tecnología y quien fue el «primero» en implementarla. Este GR6500 era un chip bastante básico con un rendimiento muy limitado frente a lo que ofrece NVIDIA, pero en resumen es un buen indicativo de lo que ha avanzado todo.
Viendo el gráfico superior podríamos decir que las unidades USC son lo que ahora NVIDIA denomina SM (salvando las distancias y complejidad). Para hacernos una idea la unidad RTU del PowerVR era capaz de realizar 300 MRPS mientras que Turing es capaz de realizar 10.000 MRPS.
Podríamos pensar que esto es debido a la mayor potencia del chip de NVIDIA, a la mayor frecuencia o más caches, pero nada más lejos de la realidad. Todo se basa en los Turing SM o SM a secas si hablamos de forma general:
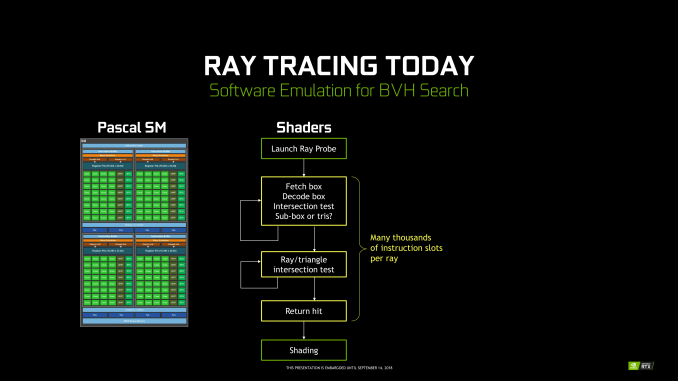
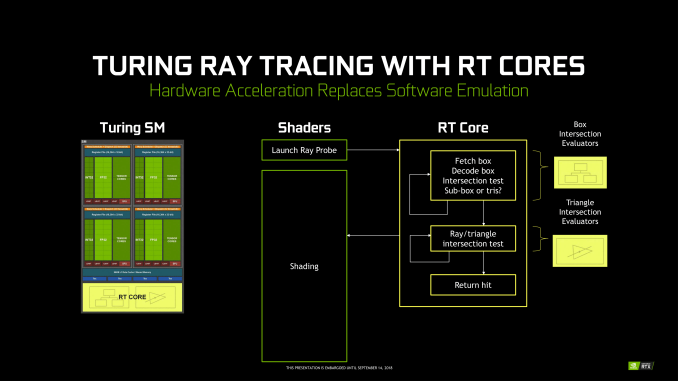
A diferencia del PowerVR GR6500 que solo tenía una unidad RT, NVIDIA incorpora en su RTX 2080 Ti la friolera de 72 unidades RT, llamadas RT Core, cada unidad está dentro de un SM de forma indivisible.
Pero, ¿qué es un SM? Un SM (Streaming Multiprocessor) es la unidad mínima de ejecución de NVIDIA que incluye todas las unidades de cómputo, registros, warps y memorias compartidas. Esto quiere decir que si NVIDIA en sus chips inferiores reduce su número de SM, también reduciría los RT Core y por lo tanto los MRPS de la GPU (a no ser que directamente los elimine del SM).

Dentro de cada SM, aparte de los RT Core y los INT32 y FP32, NVIDIA ha creado un nuevo motor de renderizado llamado Tensor Cores. Estos Tensor Cores fueron introducidos por NVIDIA en la arquitectura Volta para servidores siendo su potencial enorme, y en Turing han sido aumentados a 8 núcleos dentro de cada SM.
Básicamente, es una ALU eliminando las partes flexibles de los CUDA Cores y dejando un solo núcleo (ocho en el conteo completo) con una capacidad de multiplicar matrices enorme, que es capaz de procesar miles de valores a la vez, es decir, son unidades de ejecución especializadas y diseñadas específicamente para realizar operaciones de tensor / matriz que son la función de cómputo principal utilizada en Deep Learning.
Estos Tensor Cores son los encargados de trabajar con el nuevo Deep Learning Super Sampling (DLSS) del que hablaremos más adelante. Como último apunte, y puede que no sea necesario, al estar incluidos dentro de los SM, los TC se reducirían en la misma proporción que los RT Cores si NVIDIA decide quitar SM para producir chips más pequeños, como se espera en las GTX 2060 e inferiores.
Entendiendo esto podemos pasar a ver cómo trabajan los RT Cores y la arquitectura de NVIDIA en general para Ray Tracing.
Renderizado por Tiles o baldosas
Las GPUs de NVIDIA llevan renderizando por Tiles (o baldosas en castellano) muchos años, es una técnica ampliamente utilizada y que se «introdujo» en Maxwell en su máxima expresión.
El funcionamiento es sencillo, se divide la pantalla en mosaicos o baldosas (Tiles) y luego se rasteriza todo el cuadro por cada mosaico en tamaños de 16×16 y 32×32 píxeles (aunque esto puede variar si la GPU lo considera necesario) adaptando los tamaños a lo que mejor rendimiento ofrezca en cada momento.
Esto tiene una ventaja, es posible garantizar que los datos procesados ocupen menos espacio que la de un procesamiento de pantalla completo, son lo suficientemente pequeños como para ocupar menor espacio en la caché L2 y puede llenarse y vaciarse más rápido según convenga.
Además, la GPU no tiene que acceder a grupos de memoria tan grandes y lentos de procesar, reduciendo la carga de VRAM y dejándola disponible para otras tareas. Por ello el tamaño de las caches de las GPU NVIDIA va creciendo en cada nueva arquitectura (entre otras razones por supuesto).
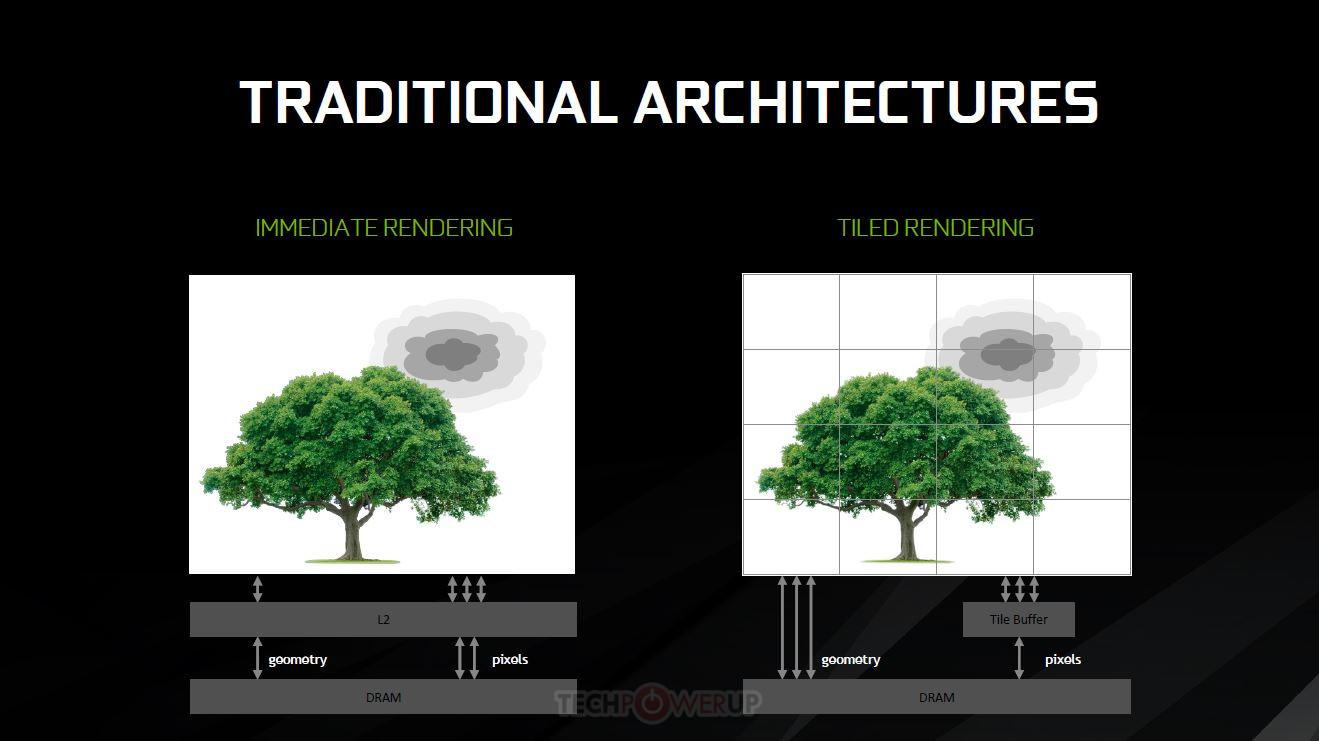
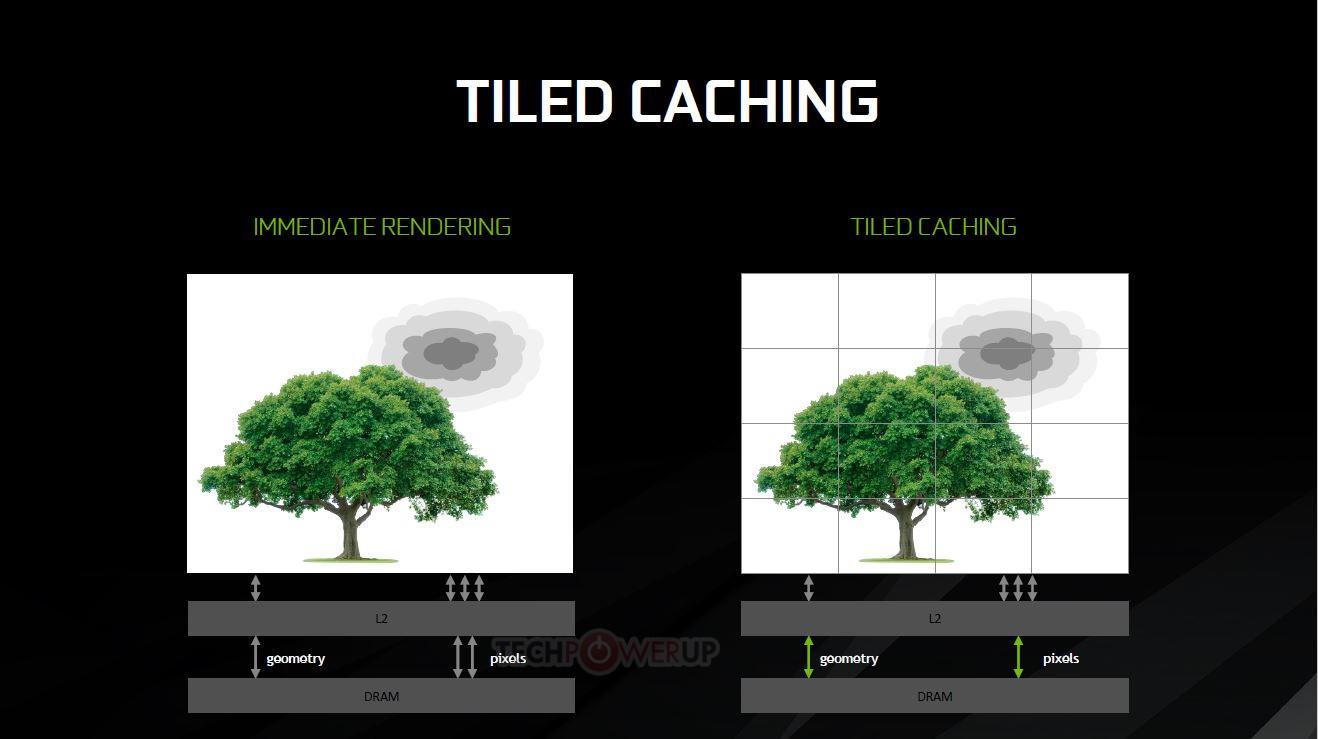
Esto tiene otra ventaja muy importante, al rasterizar los polígonos en Tiled se pueden descartar aquellos polígonos no visibles para NO ser rasterizados, de manera que una vez terminado este proceso la L2 manda todo el rasterizado a los shaders o CUDA Cores para representar los píxeles en pantalla.
Pero entonces ¿qué tiene que ver los tiles con el Ray Tracing? Bueno, pues atendiendo a la descripción de RT que hay más arriba es fácil imaginar qué ocurre si eliminas polígonos que no sean visibles para el ojo humano pero que interactúen con la escena a la hora de representar los rayos, sería un desastre.

Te puede interesar ...
Así mejoran Metro Exodus, Shadow of the Tomb Raider y otros juegos con Ray Tracing
Esto solo es un problema en un principio, ya que no permitiría realizar el trabajo correctamente y el efecto no sería fotorrealista ni mucho menos.
Bounding Volume Hierarchy (BVH)
La solución es algo simple, antes de rasterizar los polígonos, NVIDIA introduce un (nuevo) algoritmo: Bounding Volume Hierarchy (BVH) o mapa de geometría de la escena (en forma de árbol) de manera que sea más sencillo posicionar los polígonos en pantalla.
Esto es un concepto difícil de imaginar, por lo que una imagen es mucho más sencilla de interpretar y comprender:

Siguiendo el orden del árbol desde arriba hasta abajo, los RT Cores saben cuantos objetos hay y en qué orden deben de hacer trabajar el Ray Tracing en cuanto a los cruces de rayos en pantalla se refiere.
Ahora puede surgirnos la pregunta ¿Por qué no se usan los CUDA Cores para esto en vez de los RT Cores? Fácil, porque los RT Cores son unidades diseñadas para acelerar las funciones de los BVH dentro del propio SM. Son unidades específicas para esto y por eso NVIDIA las incluye en esta arquitectura Turing.
De usar NVIDIA los Shaders o CUDA Cores el proceso sería este:
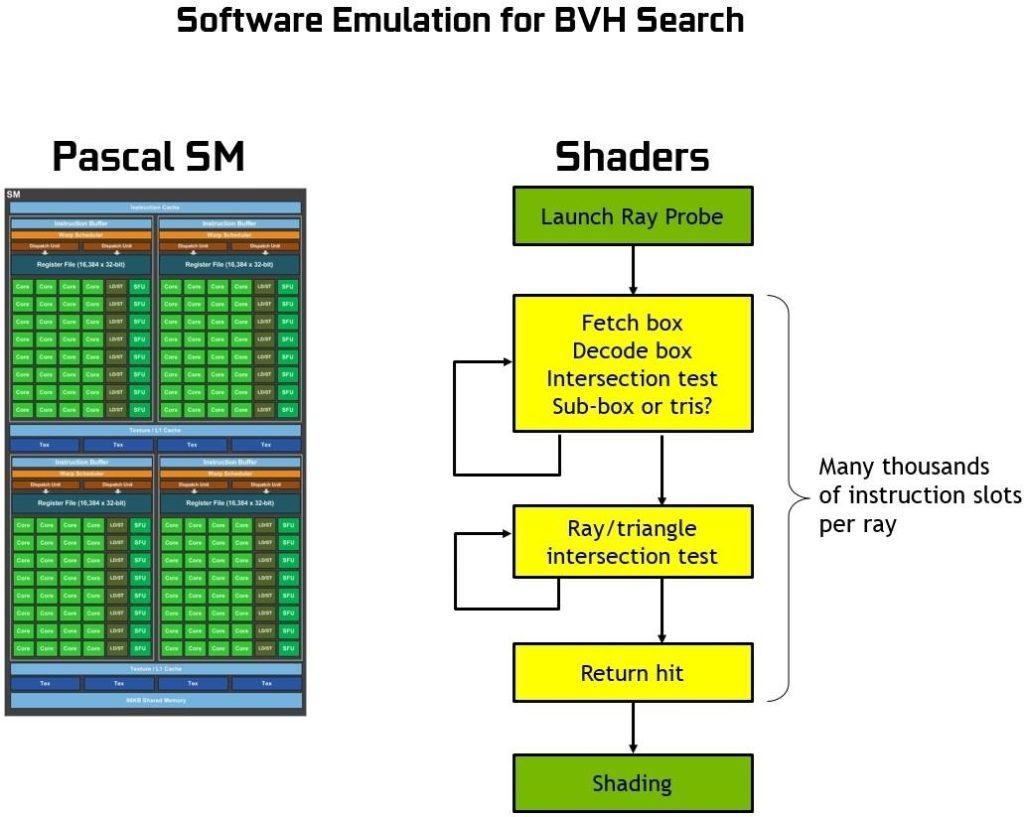
Como se aprecia el proceso sería extremadamente lento, mientras que con los RT todo es mucho más rápido gracias a que cada unidad RT Core incluye dos unidades especializadas. La primera unidad realiza pruebas de cuadros delimitadores, mientras que la segunda unidad realiza pruebas de intersección de triángulo/rayo.
El SM se divide entonces en dos procesos, los CUDA Cores inicia el BVH mientras que los RT realizan las pruebas de cruce y triángulos y lo devuelve al SM ya trabajado y listo.
Esto libera al SM/CUDAS de un cálculo muy complejo y pesado acelerando todo el proceso.
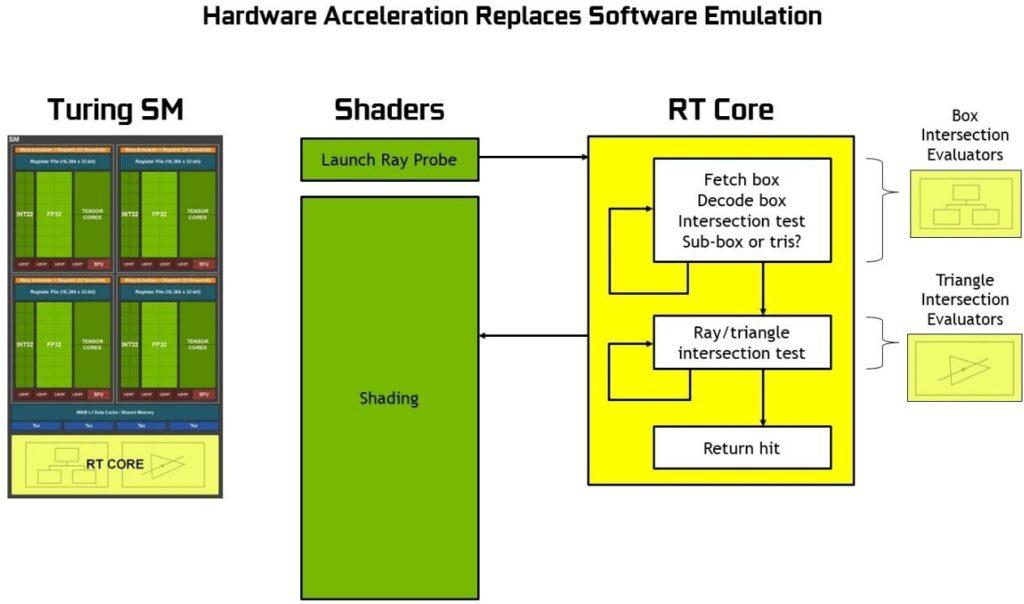
Las GPUs Pascal (y anteriores) al no disponer de RT Cores tienen que forzar el trabajo a través de los CUDA Cores (como en el primer gráfico), consiguiendo un rendimiento mucho menor y de ahí la insistencia de Jen-Hsun Huang con los ya famosos 10 Giga Rays en Turing.
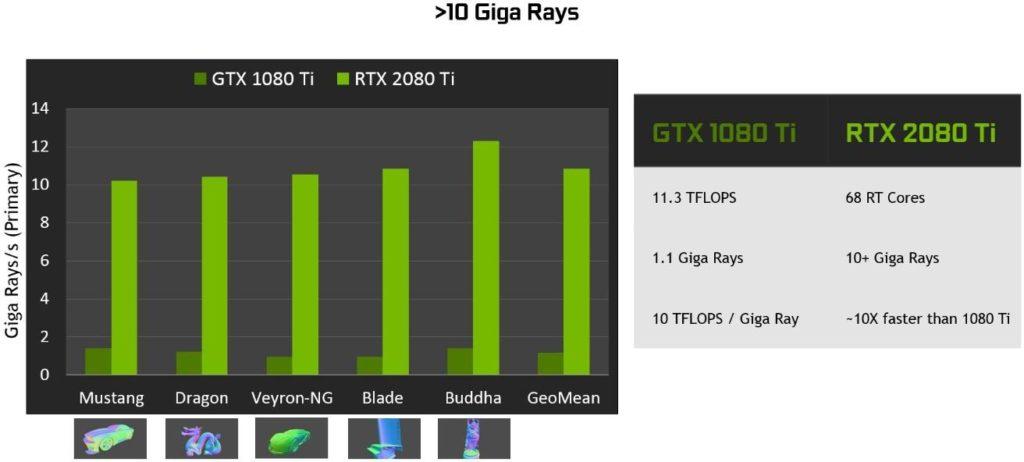
Por último, dentro de este punto hay que recalcar que un solo rayo por píxel puede dar como resultado docenas o incluso cientos de cálculos de rayos. Esto varía según la superficie a reflectar, si es poco reflectante bastarán algunos rayos, pero si pusiésemos un espejo serían necesarios miles de rayos casi con total seguridad.
Entonces, ¿son suficientes 10 Giga Rays para realizar un trazado de rayos en tiempo real? La respuesta es NO, un contundente NO, no hay suficiente potencia para realizar este trabajo completo en tiempo real en esta RTX 2080 Ti, así que NVIDIA conocedora de esto ha propuesto una alternativa más inteligente hasta que sus GPUs sean lo suficientemente potentes y las desarrolladoras de juegos optimicen el código y actualicen motores a su API OptiX o por el contrario sigan con DXR y Vulkan.
Prosiguiendo, NVIDIA ha denominado a su tecnología de representación Hybrid Rendering Pipeline, una mezcla de la rasterización tradicional (donde entran en juego las oclusiones ambientales más típicas como SSAO) y el trazado de rayos.

La representación híbrida utiliza tecnologías de rasterización tradicionales para representar todos los polígonos en un marco, y luego combina el resultado con sombras, reflejos y/o refracciones trazadas por rayos. Esto evita el colapso de información a procesar ya que el trazado de rayos se hace más simple, lo que permite aumentar todavía más el rendimiento a costa de una menor calidad por supuesto.
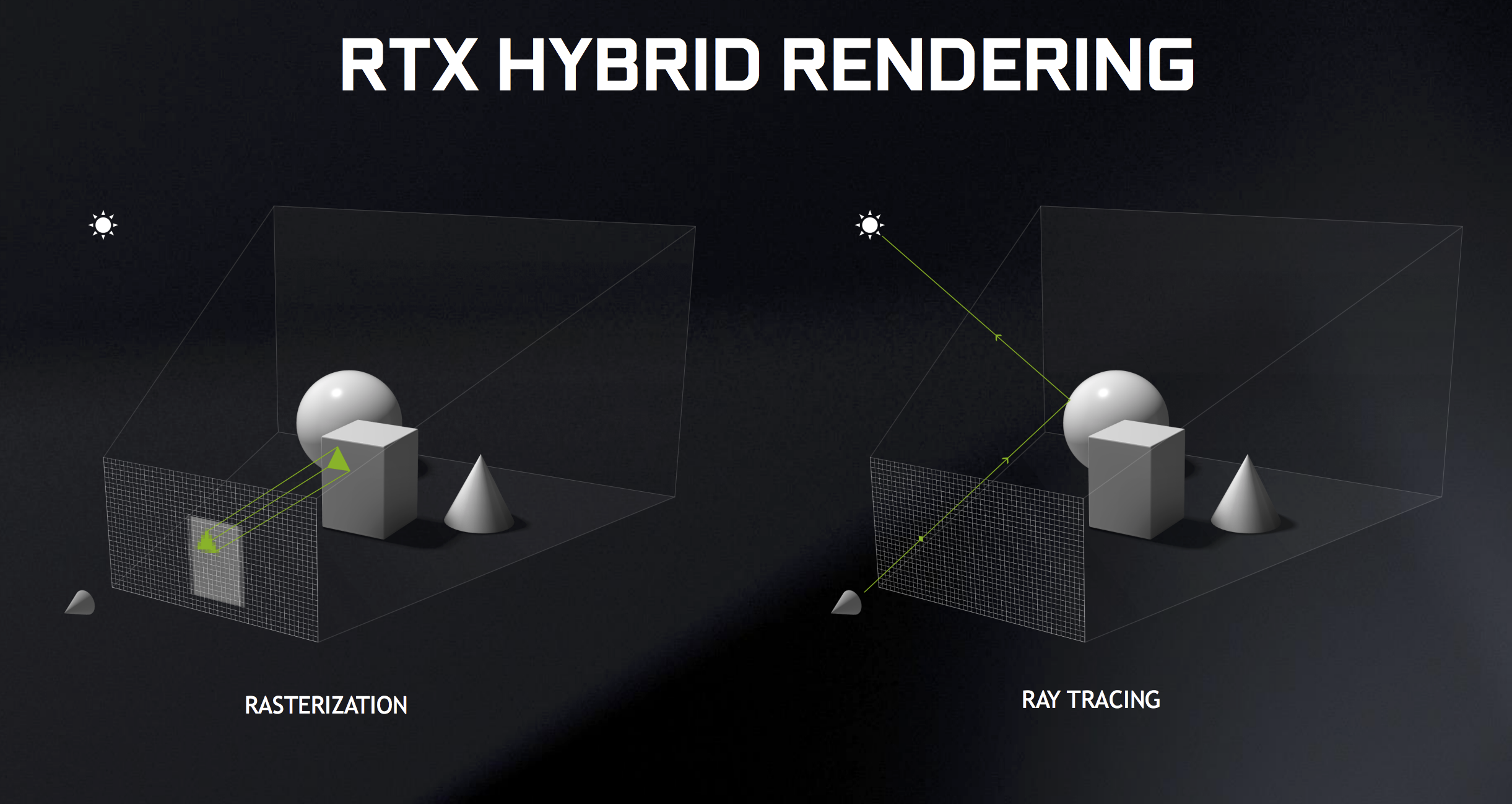
Digamos que no es un trazado de rayos o Ray Tracing «puro o al completo» sino eso, un híbrido que necesita NVIDIA para salir del paso debido a la falta de potencia existente de momento.
A esto se le suma que la cantidad de objetos con la capacidad de refractar y reflejar será al principio limitada. Los juegos, motores y desarrolladoras no van a implementar una cantidad brutal de rayos por el simple hecho de que el rendimiento cae exponencialmente, por lo que a medida que la tecnología madure y las GPUs aumenten sus RT Cores y Shaders, frecuencias y transistores se convertirá, si no se ha convertido ya, en un estándar para la industria.
No es fácil de comprender todo esto, pero esperamos que haya quedado claro (o más o menos claro). Dicho esto, pasemos al DLSS.
Deep Learning Super Sampling (DLSS)
Unos párrafos más arriba hemos citado el uso de los Tensor Cores con el Deep Learning Super Sampling, pero ¿qué es realmente el DLSS?
Actualmente en los juegos modernos, los fotogramas renderizados no se muestran directamente, sino que pasan por un paso de mejora de la imagen posterior al procesamiento que combina la entrada de múltiples fotogramas renderizados, tratando de eliminar artefactos visuales como alias mientras preserva los detalles. Por ejemplo, el Anti-Aliasing temporal (TAA), un algoritmo basado en sombreado que combina dos cuadros utilizando vectores de movimiento para determinar dónde muestrear el fotograma anterior, es uno de los algoritmos de mejora de imagen más comunes actualmente en uso. Sin embargo, este proceso de mejora de la imagen es fundamentalmente muy difícil de hacer bien.

Los investigadores de NVIDIA reconocieron que este tipo de problema, un problema de análisis y optimización de imágenes sin una solución algorítmica limpia, sería una aplicación perfecta para la inteligencia artificial sin duda.
La red neuronal profunda (DNN) que se desarrolló para resolver este desafío se llama Supermuestreo de aprendizaje profundo (DLSS por sus siglas en inglés). DLSS produce un resultado de calidad mucho mayor que TAA a partir de un conjunto determinado de muestras de entrada, y aprovechando esta capacidad para mejorar el rendimiento general.
Mientras que TAA renderiza en la resolución final del objetivo y luego combina cuadros, restando detalles, DLSS permite un procesamiento más rápido con un conteo de muestras de entrada más bajo, y luego infiere un resultado que a la resolución del objetivo es similar al resultado del TAA, pero con la mitad del trabajo de sombreado.
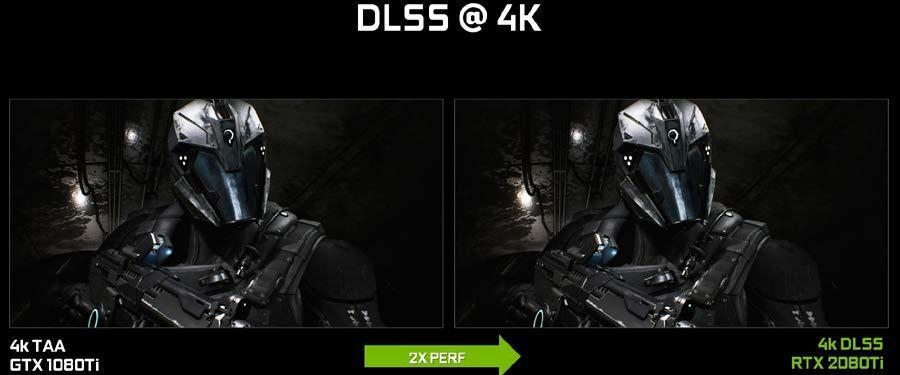
La clave de este resultado es el proceso de capacitación para DLSS, donde se obtiene la oportunidad de aprender a producir el resultado deseado en base a un gran número de ejemplos de súper alta calidad. Para entrenar a la red (NVIDIA lo llama directamente así, network), se recopilan miles de imágenes de referencia «en el terreno» procesadas con el método estándar para una calidad de imagen perfecta con supermuestreo 64x (64xSS). El supermuestreo 64x significa que en lugar de sombrear cada píxel una vez, se sombrean 64 desplazamientos diferentes dentro del píxel, y luego se combinan las salidas, produciendo una imagen resultante con un detalle ideal y una calidad anti-aliasing. También se capturan las imágenes de entrada sin procesar que se representan normalmente. A continuación, se capacita a la red DLSS para que coincida con los marcos de salida 64xSS, revisando cada entrada, solicitando a DLSS que produzca una salida, midiendo la diferencia entre su salida y el objetivo 64xSS.

Esto es fantástico sin duda, es una tecnología totalmente nueva, que mejora muchísimo a TAA a un coste menor.
Ya explicadas ambas tecnologías queda centrarnos en lo realmente importante de este artículo.
¿Pueden llegar tanto Ray Tracing como DLSS que poseen las RTX a las GPUs de AMD?
Bueno, como hemos visto Ray Tracing no es algo propietario, de hecho, Microsoft tiene su propia API llamada DirectX R o DXR, la cual soporta de inicio el trazado de rayos.
Pero aquí encontramos un problema, AMD siguió las pautas que tanto Vulkan como Microsoft le dieron para sus respectivas APIs, de manera que cualquier GPU actual con shaders, ya sean CU o CUDAs, pueden renderizarlo. El problema es que tanto Vulkan como Microsoft afirmaban que sería posible un trazado de rayos a tiempo real con un rendimiento decente (no dicen alto siquiera) y que tiene como pilares básicos cuatro nuevos conceptos:
- La estructura de aceleración es un objeto que representa un entorno 3D completo en un formato óptimo para el recorrido por la GPU. Representada como una jerarquía de dos niveles, la estructura permite el cruce de rayos optimizado por la GPU, así como la modificación eficiente por parte de la aplicación de objetos dinámicos.
- Un nuevo método de lista de comandos, DispatchRays, es el punto de partida para rastrear rayos en la escena. Así es como el juego realmente envía cargas de trabajo DXR a la GPU.
- Un conjunto de nuevos tipos de sombreado HLSL, incluidos ray-generation, closest-hit, any-hit, and miss shaders. Estos especifican lo que la carga de trabajo DXR realmente hace computacionalmente. Cuando se llama a DispatchRays, se ejecuta el sombreador de generación de rayos. Usando la nueva función intrínseca TraceRay en HLSL, el sombreador de generación de rayos hace que los rayos sean rastreados en la escena. Dependiendo de dónde entra el rayo en la escena, se puede invocar uno de varios sombreadores para acertar o fallar en el punto de intersección. Esto permite que un juego asigne a cada objeto su propio conjunto de sombreadores y texturas, lo que da como resultado un material único.
- El raytracing pipeline state, un compañero «en espíritu» para los objetos de estado de tuberías de Computación y Gráficos actuales, encapsula los sombreadores de trazado de rayos y otro estado relevante para las cargas de trabajo de trazado de rayos.
El problema ahora está en que NVIDIA acaba de demostrar empíricamente que se necesitan unidades de cómputo dedicadas (RT Cores) para poder agilizar el trazado de rayos en tiempo real.

Esto a AMD le ha pillado, como se suele decir, con el pie cambiado, su arquitectura NAVI mantiene GCN como base y de momento no hay datos que ofrezcan nada acerca de unidades dedicadas para el trazado de rayos.
Entonces ¿qué podría hacer AMD para añadir RT a su arquitectura? Partamos de la base de que los CUs no son muy distintos al funcionamiento de los SM.
Ya sabemos que los RT se encuentran dentro del SM y que tienen acceso a la caché L2 al igual que los ROPS (unidades de rasterizado). Esto es extensible tanto a AMD Vega como a NVIDIA (excepto lógicamente por los RT) el problema es que los shaders tienen acceso solo a sus registros/cachés y necesitan traer de vuelta las cadenas de instrucciones para que las ALUs de los CUDA (en el caso de NVIDIA) puedan procesarlos.
Y ahí radica la primera diferencia, en NVIDIA cada sub-núcleo tiene ahora una caché de instrucciones L0 (como pasó en Volta) con un archivo de registro de 64 KB, detalle que logra reducir la latencia al entrar en juego los Tensor Cores. Ahora en Turing parecen favorecer a los RT Cores ya que los SM tienen 4 unidades de carga/almacenamiento por subcore.
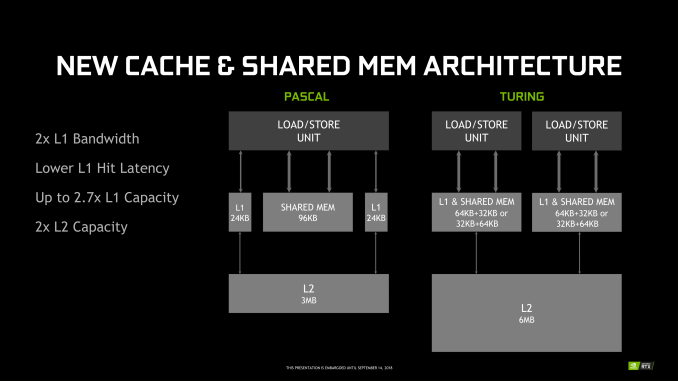
Esto es importante puesto que los RT Cores vuelcan la información en esta L0 de manera que no tienen que acceder a memorias más lentas o a mayores subniveles, acelerando el proceso de búsqueda y resolución.
La implementación de unas unidades como los RT Cores en AMD pasan en mi opinión por incluirlas dentro de los CU como ha hecho NVIDIA:

Creando una caché pequeña de interconexión justo por encima de la L1 con entrada y salida al Export Bus (interconectadas) que también conecta con los ROPS, L2 y SIMD pero al mismo tiempo tendría acceso a las unidades de filtros de texturas, tal y como se aprecia en la siguiente imagen de un CU:
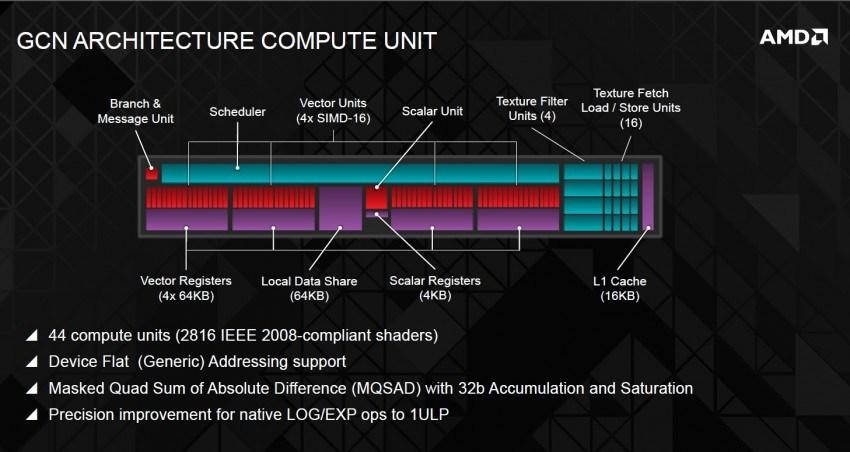
Realmente es retocar la arquitectura siguiendo pasos similares a lo que ha hecho NVIDIA y que son exportables a AMD, lo que le otorgaría Compute Units más complejos, pero más potentes y a la vez eficientes.
Solucionado esto, ¿qué hay del DLSS en AMD?
Bueno, esto es un poco más complejo de desarrollar para los de Lisa Su. Deep Learning Super Sampling es una tecnología PROPIETARIA de NVIDIA, es decir, AMD no puede usarla (y NVIDIA dudo que quiera).
Pero hay más y seguro que es interesante para los no conocedores de esto: para usar DLSS los desarrolladores deben proporcionar datos a NVIDIA para capacitar el modelo DLSS. Este proceso tiene que ser realizado en el super computador Saturno V.

Este super ordenador cuenta con 60.512 núcleos basados en NVIDIA P100 y 63.488 GB de RAM lo que le otorga un rendimiento teórico de 4.898,51 TFLOP/S.
En otras palabras, los desarrolladores mandan el código de sus motores y juegos para que NVIDIA pueda trabajar en el DLSS mediante su Saturno V, y después devuelve dicho código optimizado al desarrollador para que puedan trabajar sus tarjetas gráficas de forma óptima.
Esto a día de hoy es imposible e impensable para AMD, no solo no puede acceder a la tecnología de NVIDIA para un posible competidor del DLSS, sino que ni siquiera ha desarrollado algo similar (de momento).
Así que la respuesta es NO, AMD no va a tener DLSS, en todo caso podrá crear algo que se le asemeje y que funcione de una manera similar, pero eso lo tendremos que ver en un futuro, ya que quizás este tipo de tecnologías no le sean atractivas.