
El nuevo gran procesador de AMD denominado Summit Ridge que incorporará la nueva arquitectura Zen en la que este fabricante lleva ya cuatro años trabajando, está a punto de ver la luz y AMD nos invitó a una conferencia donde se desveló cuál será el funcionamiento interno de esta nueva arquitectura y cómo se compara frente a arquitecturas de procesadores anteriores de AMD, especialmente a Bulldozer.
Quizás el mayor problema al que se enfrentaba AMD a la hora de desarrollar la arquitectura Zen era el bajo rendimiento por IPC que tenía su arquitectura previa, Bulldozer. AMD sabía que debía aumentar el rendimiento de su procesador por cada ciclo de reloj para volver a ser una alternativa competitiva frente a Intel. Aunque las sucesivas iteraciones de Bulldozer habían aumentado su rendimiento bastante frente al modelo original, estos todavía quedaban bastante lejos del rendimiento que tienen ahora mismo los procesadores de Intel.
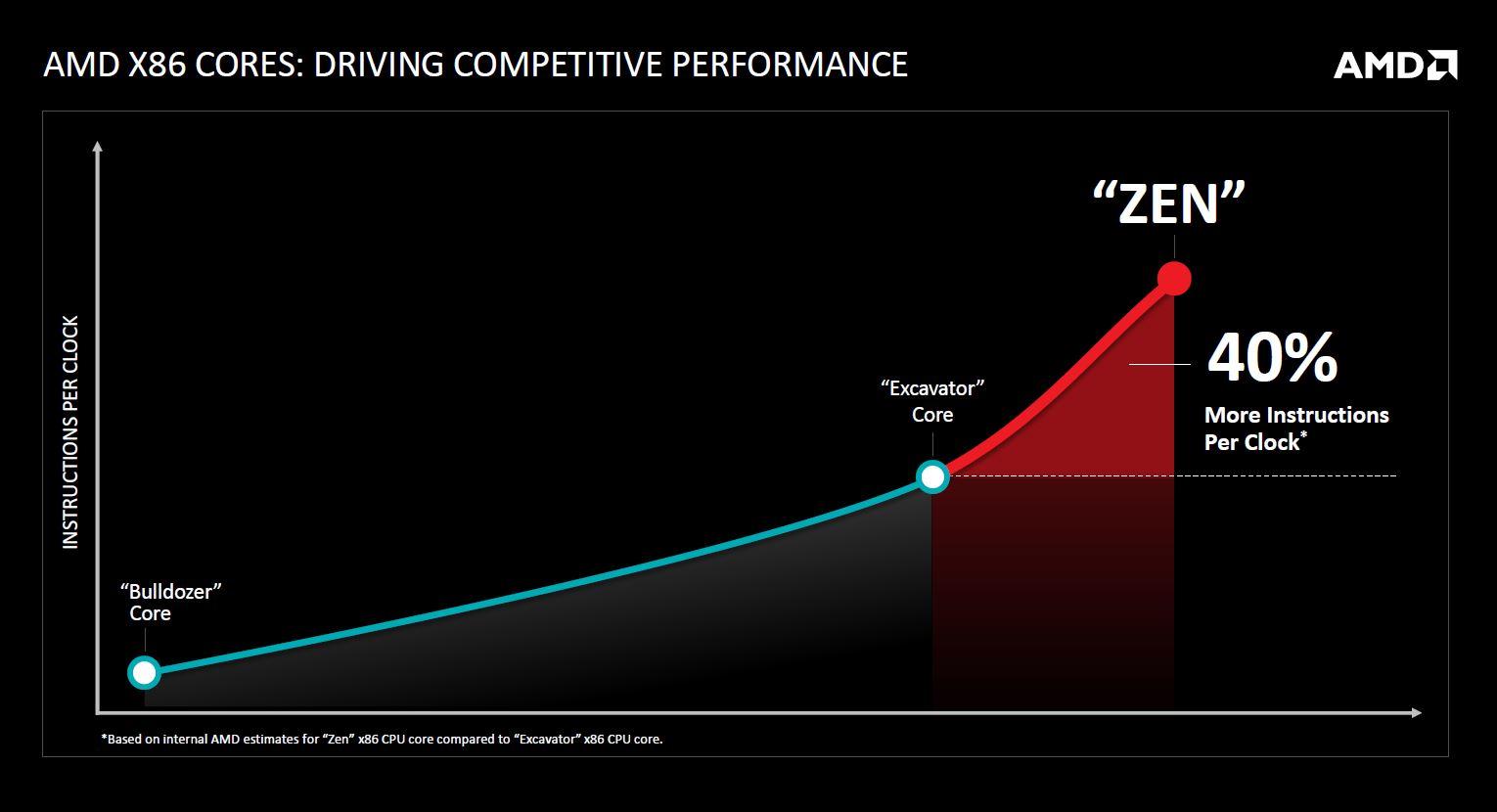
La cuestión estribaba también en conseguir dicho incremento pero sin que la eficiencia del procesador se fuera a ver gravemente mermada, dado que es un antiguo mantra en el que, a mayor rendimiento para una determinada arquitectura, mayor consumo de potencia. Si ya el consumo de potencia de los Bulldozer era bastante elevado, aumentar éste en un 40% lo hubiera convertido en una opción no válida para el mercado, así que AMD tenía que buscar una solución que aunara ambos factores: rendimiento y potencia.
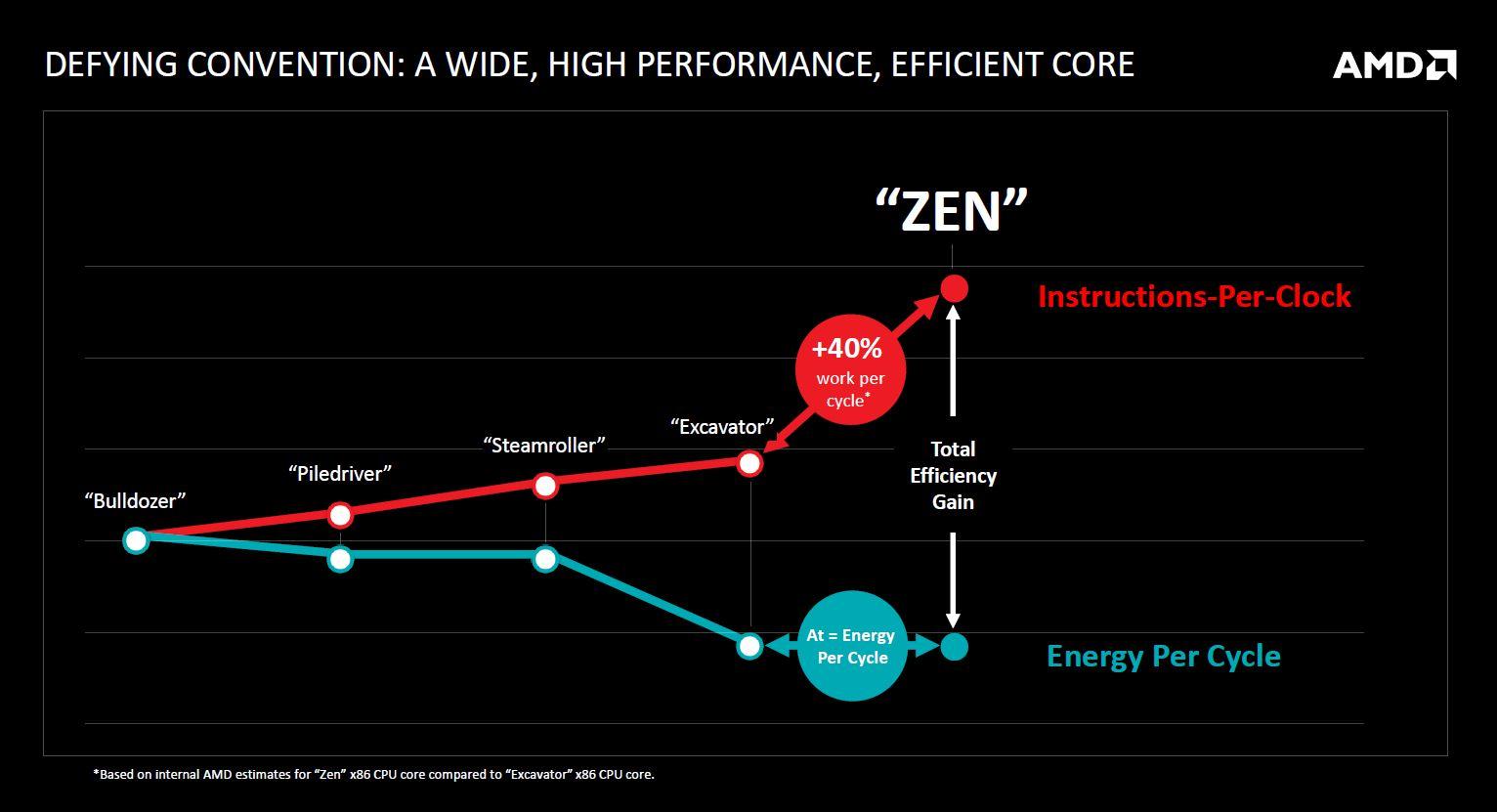
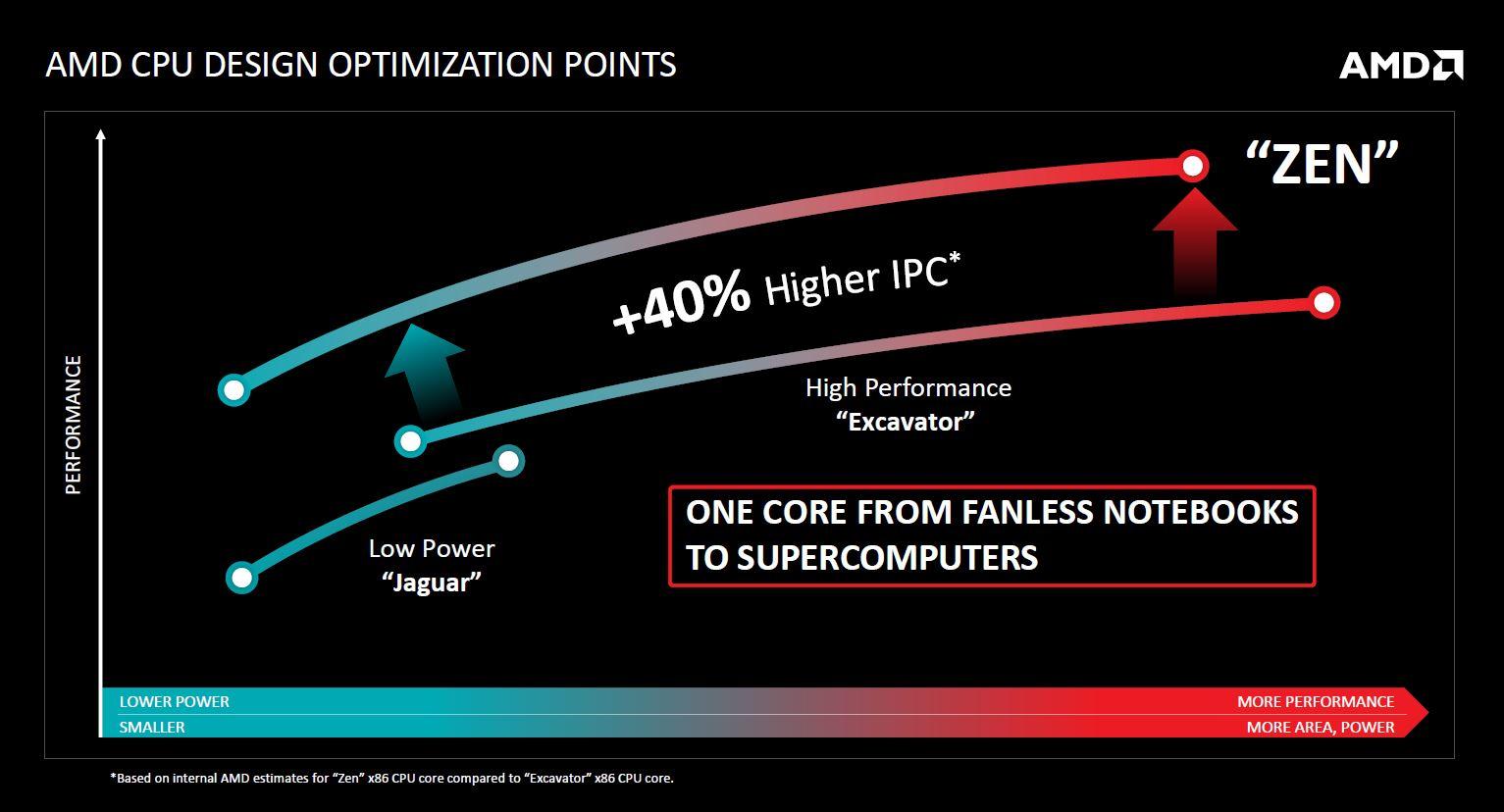
Es en este punto donde entra el nuevo nodo de fabricación de 14 nm FinFET de Samsung, cuya licencia compró Global Foundries en su momento. La reducción del nodo de fabricación, junto con ciertas mejoras internas de la arquitectura, es lo que permitiría a Zen mantenerse dentro del margen de eficiencia necesario para crear un procesador realmente competitivo.
Otro aspecto que AMD decidió optimizar era el tener dos líneas de productos, cada una con sus propias placas base, socket y chipsets asociados. Desde el punto de vista empresarial, esta fue una mala jugada dado que obliga a dividir los recursos entre varias plataformas con el objetivo de mantenerlas actualizadas. Por tanto, AMD ha decidido crear una única plataforma que compartirá placas base, socket, chipsets y características entre sus modelos, permitiendo un uso optimizado de los recursos de la empresa.
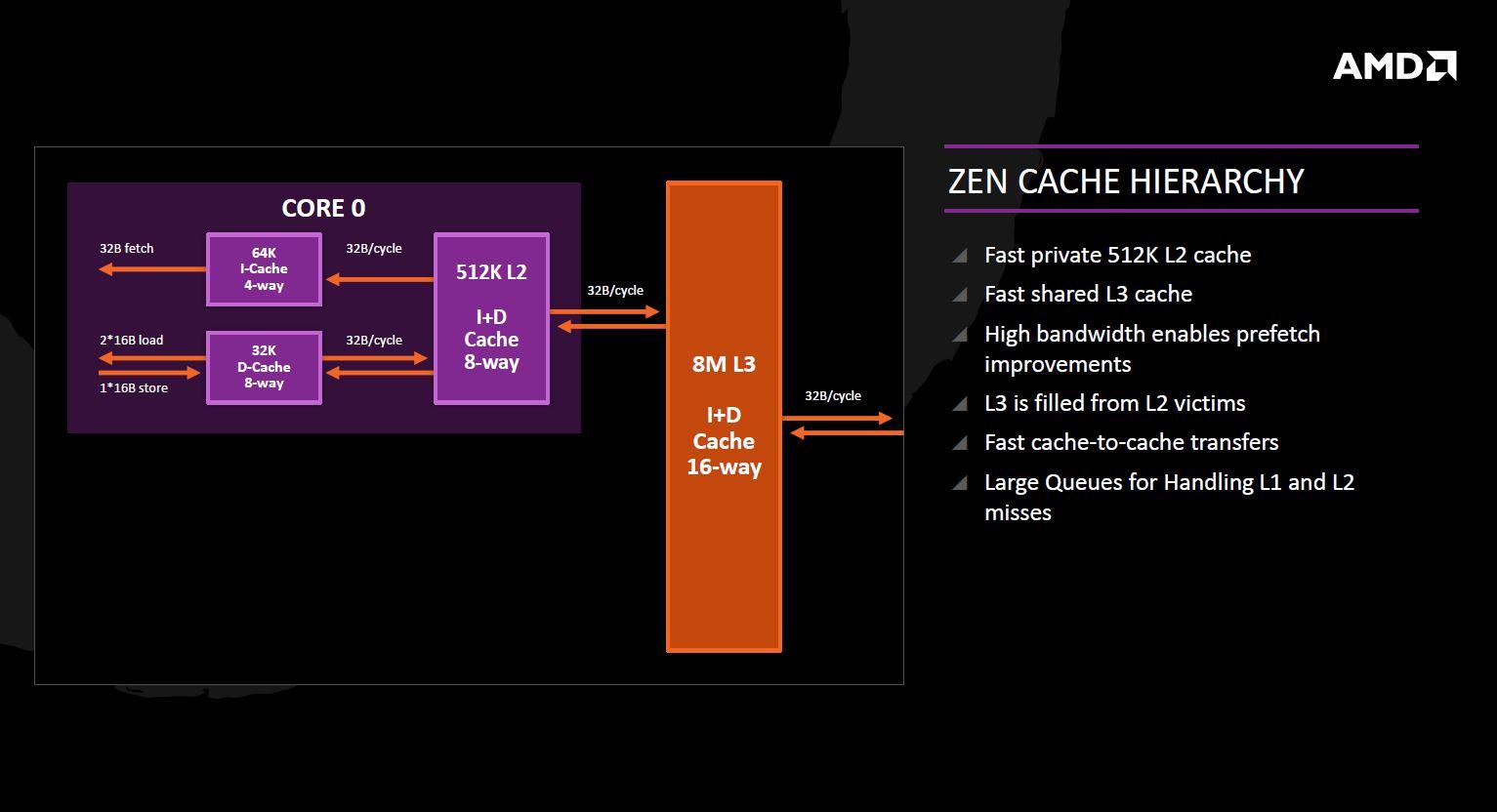
El bloque de construcción básico de Zen se denomina «Core complex» y engloba 4 núcleos independientes que se hayan conectados a una caché L3 de 8 MB compartida entre los cuatro núcleos, dando un reparto de 2 MB por cada uno de ellos. Las cachés L1 y L2 han aumentado de tamaño frente a Bulldozer, siendo la L1 de 64 KB y la L2 de 512 KB. También se ha cambiado el tipo de caché pasando a ser del tipo «write-back» frente al tipo «write-through» que empleaba Bulldozer. Este cambio permite unas menores latencias a la hora de acceder a la caché de operaciones y una alta tasa de generación de datos para aplicaciones que requieren una alta tasa de escrituras.
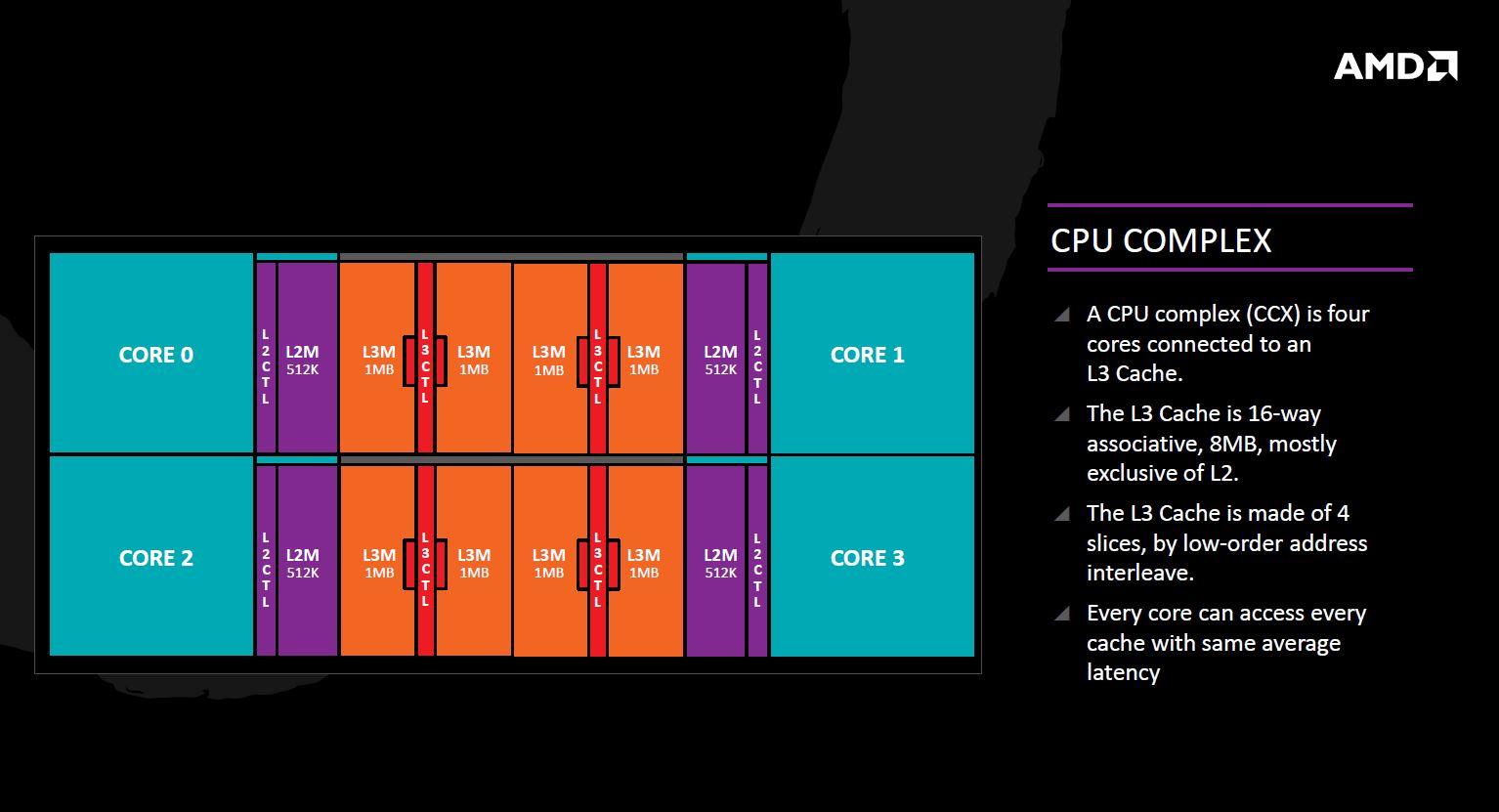
Cada núcleo tendrá acceso directo a su caché privada L2, y su parte de los 8 MB de caché L3, que como dijimos antes estará dividido en bloques por núcleo. La caché L3 es en realidad una memoria caché víctima, tomando los datos de L1 y L2 no utilizados en lugar de recoger datos de las instrucciones de captación previa, es decir, no se comunicará directamente con los núcleos sino con las memorias caché anteriores (L1 y L2). Éste sistema hará que la caché L3 sea menos eficaz que si tuviera comunicación directa con los núcleos, pero según AMD ésto en Zen no importará gracias a la caché L2 de alto rendimiento que tendrá cada núcleo.
Zen incorporará por primera vez el Simultaneous Multithreading en sus núcleos. Existen varios modos con los que se puede lidiar con este tipo de arquitecturas. En este caso, con cada hilo AMD lleva a cabo un análisis interno de la secuencia de datos para cada uno para ver cuál de ellos tiene prioridad algorítmica. Esto significa que ciertos hilos requerirán más recursos, o que se pierda la rama que debe ser priorizada para evitar retrasos largos por parada. Los elementos en azul (predicción de saltos, INT / FP Rename) operan en esta metodología. Es como el Hyperthreading de Intel, pero con otro tipo de algoritmos para priorizar las operaciones que realizan.
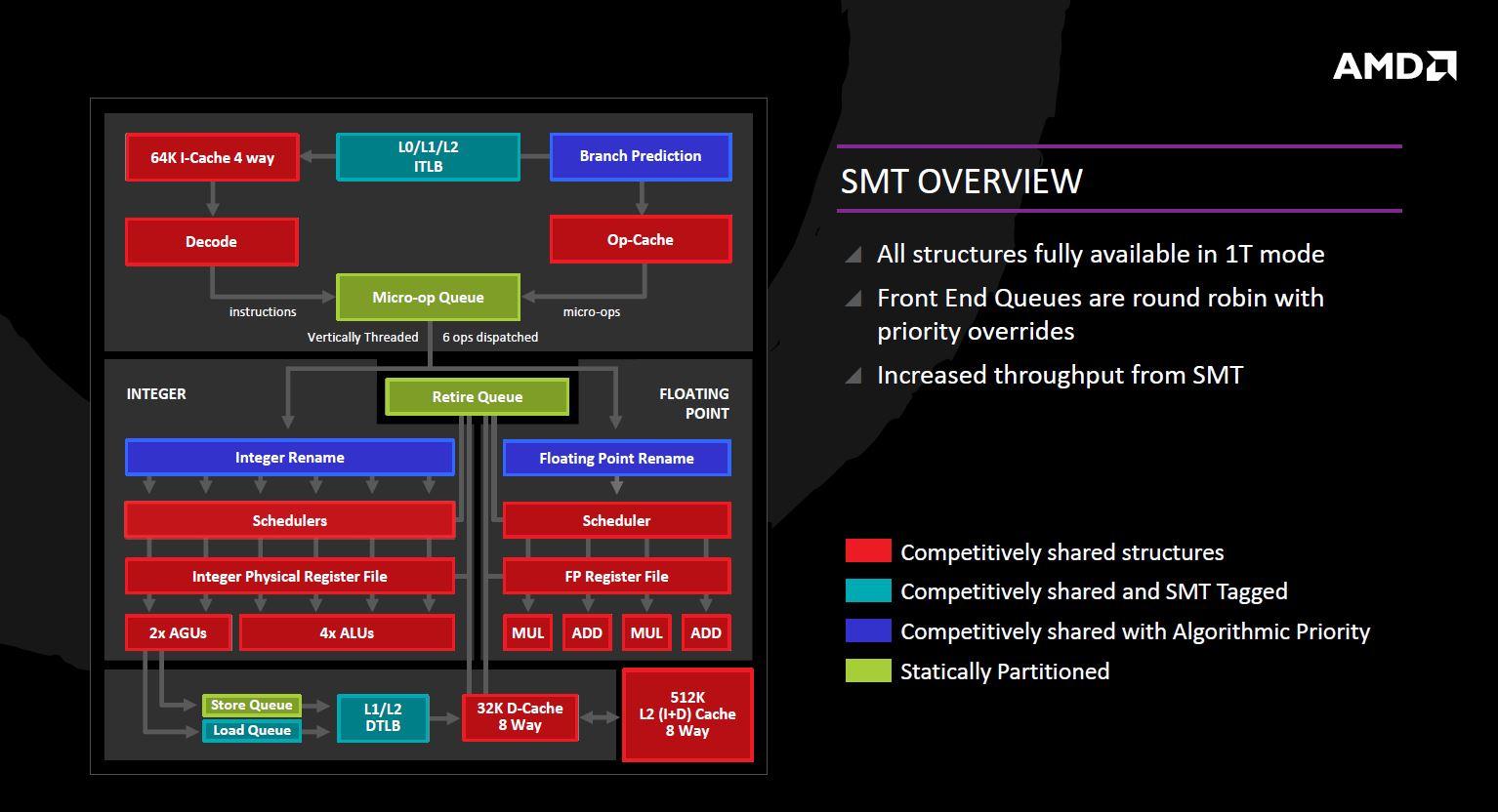
Ciertas partes del núcleo son estáticamente particionadas, dando a cada hilo el mismo tiempo. Esto se lleva a cabo sobre todo para cualquier instrucción que normalmente se procesa en orden, tal como cualquier cosa que sale de la cola de micro-op, la cola retire y la cola de almacenamiento. El resto del núcleo es competitivo, lo que significa que si un hilo exige más recursos, tratará de llegar primero si hay espacio para hacerlo en cada ciclo.
Para finalizar, solo nos queda comentar que AMD ha implementado una política muy agresiva en su control de potencia aunque en Zen no se ha implementado el block gating (apagado de bloques del procesador cuando no están en uso) si no que se ha optado por usar clock gating (reducción al mínimo de los ciclos de reloj en las partes que no están en uso).

Queremos dejar claro que la conferencia fue bastante más exhaustiva y se entró en detalle en el funcionamiento interno de cada núcleo, pero la realidad es que un artículo así hubiera acabado siendo bastante denso y complejo y hemos preferido centrarnos en las cosas que quizás más os podrían interesar. Si realmente hay demanda de ese tipo de artículo, publicaremos otro con toda la documentación técnica que se nos ha facilitado.