
No hay ninguna duda que lo que son llamadas unidades especializadas para inteligencia artificial se han convertido en una de las piezas de hardware más importantes, especialmente si hablamos del mercado de los dispositivos PostPC donde todos sus SoCs tienen una unidad de este tipo, pero no es el caso del PC pero la cosa podría cambiar por completo esta situación gracias a las extensiones Intel AMX.
En estos momentos si tenemos un PC la única manera que tenemos de tener una unidad especializada para la IA es comprando hardware aparte, ya sea adquiriendo una GPU de las familia NVIDIA RTX o comprando un FPGA montado en un puerto PCI Express.
El Intel GNA, un precedente
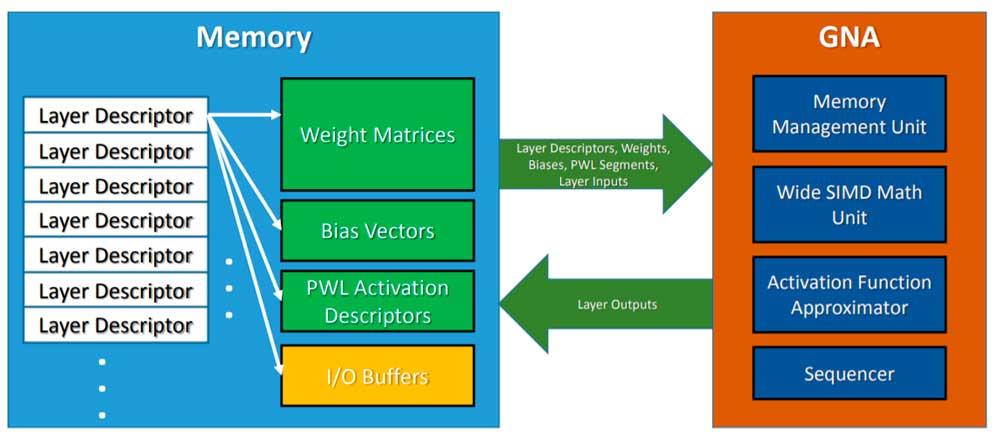
Intel tiene integrada en estos momentos una unidad llamada GNA que puede ejecutar algunos algoritmos basados en IA pero no de la misma manera que un array sistólico desde el momento en que GNA es coprocesador con configuración SIMD. Por otro lado Intel también vende soluciones basadas en FPGAs y con sus GPUs Intel Xe HP promete integrar unidades al estilo Tensor Core.
Pero de lo que estamos hablando es precisamente de integrar este tipo de unidades en una CPU, de tal manera que una mayor cantidad de aplicaciones puedan tomar provecho de este tipo de unidades.
Una respuesta al M1 de Apple

Una de las ventajas del M1 de Apple no es el hecho que el conjunto de registros e instrucciones ARM tenga una mayor eficiencia energética, sino que para ciertas aplicaciones y funciones su Neural Engine es extremadamente eficiente.
Este tipo de unidades se han hecho clave en el mercado de los smartphones y tablets porque permiten realizar tareas muy complejas en poco tiempo y con muy pocos recursos, lo que ha hecho que las CPUs de PC se queden atrás en ese aspecto.
Intel AMX
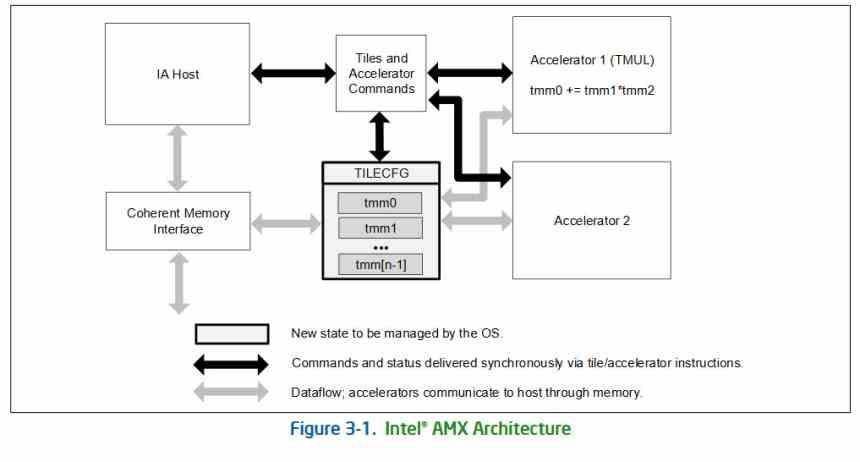
Al igual que cuando las unidades SIMD trajeron consigo la implementación de nuevas instrucciones x86, la implementación de unidades matriciales o tensoriales traen consigo un nuevo tipo de instrucción, llamadas AMX o Advanced Matrix Extensions, las cuales serán implementadas por primera vez el Intel Xeon con arquitectura Sapphire Rapids.
La extensión añade dos elementos adicionales, por un lado un set de registros en dos dimensiones compuestos por registros llamados «tiles» y una serie de aceleradores capaces de operar en esos tiles. Dichos aceleradores comparten el acceso a la memoria de manera coherente con el resto de elementos de la CPU y pueden funcionar de manera intercalada con otras unidades de ejecución x86 y en paralelo con estas.
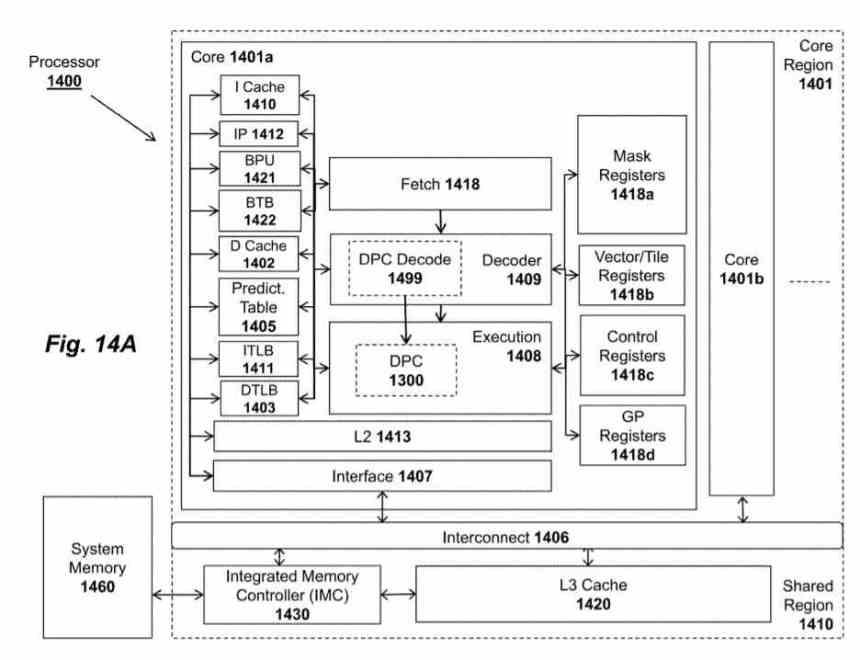
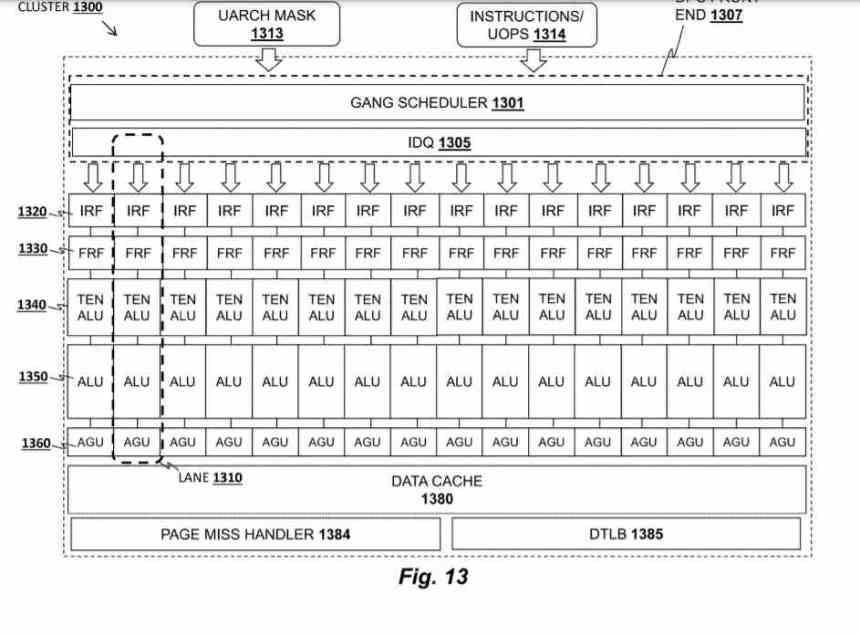
El acelerador recibe el nombre de Tile Matrix Multiply o TMUL, se trata de un array sistólico en forma de malla de ALUs capaces de realizar la instrucción FMA (Suma y Multiplicación) en un solo ciclo, que utiliza como registros los tiles de los que os hemos hablado en el párrafo anterior.
En las patentes de AMD la unidad TMUL recibe el nombre de Data Parallel Cluster y es una unidad que se encuentra dentro de cada uno de los núcleos del procesador, pese a que Intel lo va a implementar por primera vez en Sapphire Rapids, no hay duda que vamos a verlo implementado en el resto de procesadores de Intel en el futuro.