
La coherencia de caché es una de las características comunes en cualquier sistema multinúcleo, ya estemos hablando de una CPU, una GPU o cualquier tipo de unidad especializada que requiera que varios procesadores ejecuten de manera coordinada un mismo código. ¿Cómo funciona este proceso?
Según la Real Academia de la Lengua Española, la primera definición de coherencia es: conexión, relación o unión de unas cosas con otras. Y en el caso de los procesadores la coherencia de caché se ha convertido en un elemento clave del diseño de un procesador, el cual muchas veces se ignora por el hecho que no nos da más rendimiento, pero sin ella el desarrollo de programas sería mucho más complejo y un verdadero infierno.
¿Qué es la coherencia de caché?
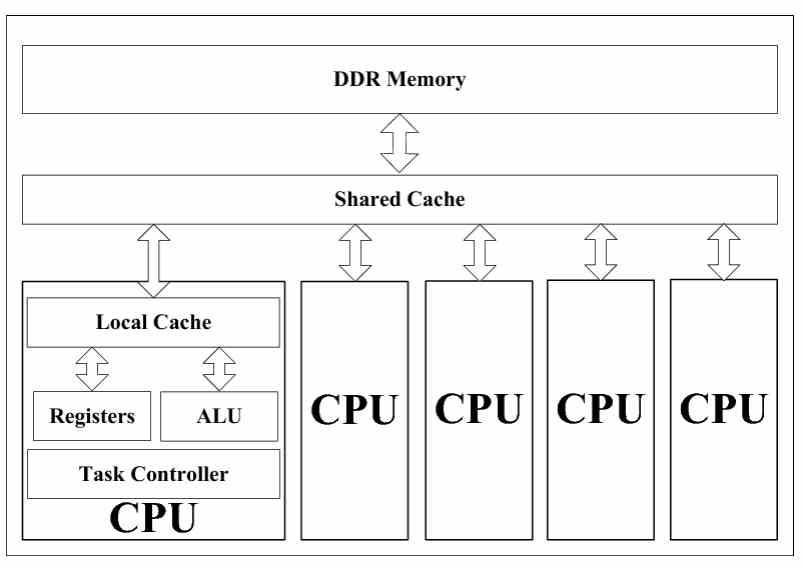
Si habéis visto cualquier diagrama de cualquier CPU multinúcleo, independientemente del diseñador, fabricante e incluso el tipo de sistema siempre os habréis encontrado con el diagrama que veis arriba, aunque hay excepciones como es el caso del procesador de PlayStation 3, el Cell Broadband Engine, pero no son la norma.
Una de las cosas en un sistema multinúcleo es la llamada coherencia de caché y para entender el concepto tenemos que imaginarnos la siguiente situación: vamos a suponer que hay varias personas cada una delante de una terminal, todas ellas editando el mismo archivo que se encuentra en el servidor. Si una de estas personas cambia una parte del documento entonces se refleja en la pantalla del resto de los editores.

Pero para ello hace falta un sistema que lo que haga que cada vez que se realice un cambio en el documento transmita la información al resto de pantallas de tal manera que el cambio se pueda ver a tiempo real. Por otra parte un día ese sistema falla y de repente todo queda descoordinado, pese a que sus ojos están editando el mismo documento en realidad cada una de las personas tiene su versión del mismo y cualquier cambio que realicen sobre el documento será independiente al que hagan otros, lo cual puede acabar siendo un desastre
Aplicad esto a un programa informático y entonces tenemos el caos absoluto, donde un pequeño cambio realizado por un núcleo en la memoria RAM del que el resto no sean conscientes puede suponer un fallo crítico en el sistema o la ejecución de datos erróneos.
Coherencia de caches y jerarquía
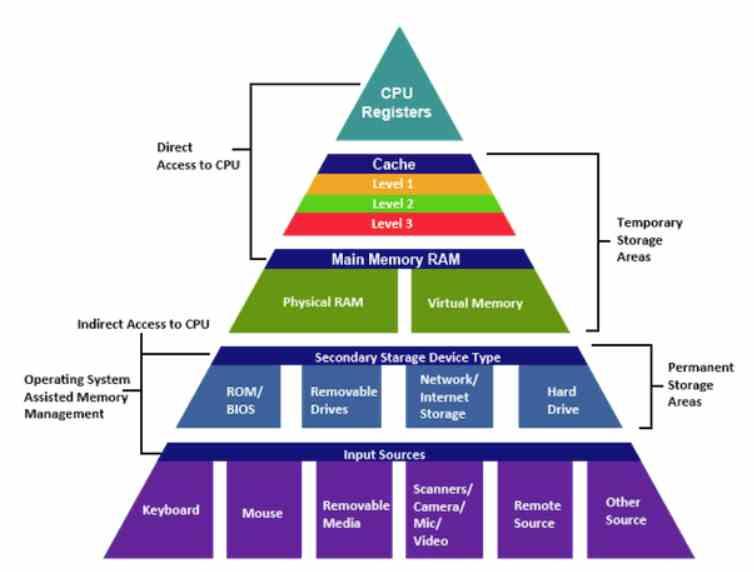
El hecho de tener que comprobar todas las líneas de la caché de una CPU (o GPU) con el contenido de la memoria RAM sería un trabajo titánico que haría sumamente lento ay complejo al procesador, pero es necesario desde el momento en que en la caché se almacenan copias del contenido de la RAM y esta por tanto se tiene que actualizar.
¿Entonces como se realiza el proceso de actualización de la caché de un procesador? Se añaden una serie de bits a cada línea de caché que le marcaran al procesador si el contenido de la misma puede ser utilizado. Estos cuatro bits tienen los siguientes valores:
- Inválida/Válida: dependiendo del valor de este bit se sabe si se ha realizado una comprobación del contenido de dicha línea de caché.
- Reservada: se está ejecutando una instrucción teniendo acceso a dicha línea de caché, el sistema de coherencia esperará a que acabe para realizar el proceso de coherencia.
- Sucia: una línea de caché que esta sucia es aquella sobre la que no ha dado tiempo a realizar el proceso de comprobación de la coherencia de caché, pero tiene la versión más actualizada generada por el procesador. Esto lo que provocará es una actualización de todas las líneas de caché y de la información de la RAM.
En el último caso lo que se hace es actualizar primero el contenido en la RAM y se va subiendo en la jerarquía de memoria, esto es debido a que cada nivel de jerarquía para comprobar que sus datos están bien no ven todo el conjunto, sino el siguiente nivel, de esta manera se simplifica el hardware relacionado.
Requiere un gran ancho de banda interno

En todo caso, corregir la información que almacena la caché interna de un procesador requiere grandes anchos de banda internos y varios accesos simultáneos a dicha memoria dentro del procesador. Si comparamos una caché con una RAM convencional veremos no solo que la primera tiene mayores anchos de banda, lo cual se puede permitir, sino que ha de alimentar a una gran cantidad de clientes al mismo tiempo y no solo los núcleos de la CPU, también otras unidades y el resto de niveles de la jerarquía.
A la hora de diseñar un procesador multinúcleo uno de los elementos que se tiene más en cuenta es la infraestructura interna, y no solo se tiene muy en cuenta es el ancho de banda interno que van a necesitar los diferentes núcleos para comunicarse, sino también la implementación de la coherencia de caché, pero desde el momento en que le facilita el trabajo a los creadores de software y todo el que hay en el mercado funciona bajo ese paradigma se trata de algo que continuará estando implementado en los procesadores.
¿Quién hace del trabajo de la coherencia de caché?
Lo siguiente que nos toca resolver es acerca del hardware encargado de la coherencia, es decir, el sistema que va línea por línea de caché a comprobar que existe coherencia con el resto de líneas en el procesador que almacenan la misma copia del contenido en memoria. Obviamente esto no lo hace la CPU y pese a que existen métodos para implementar una caché por software nadie lo hace por efectos prácticos que ya hemos comentado.
Pues bien, para realizar dicha tarea se utiliza hardware de función fija o microcableada, el cual según los datos de entrada que recibe actúa de una manera u otra, pero siempre ejecuta el mismo programa que es el que le permiten hacer su combinación de transistores. Esto es preferente por el hecho que tienen muy pocos transistores en comparación con colocar una unidad mucho más compleja que ejecute un programa que realice la misma función. Cuando el procesador encuentra el contenido que busca dentro de una línea de caché el proceso de lectura sobre los bits que marcan si hay coherencia o no es llevado a cabo por estas unidades de función fija, las cuales se encuentran para cada uno de los niveles de la jerarquía.
Otra de las piezas de hardware es la encargada de realizar el proceso de actualización a todos los niveles, el cual se realiza primero sobre la RAM para luego ir de manera ascendente hasta llegar a la caché de primer nivel.