
Mucho han cambiado las cosas en cuanto a la arquitectura de las GPUs NVIDIA en las últimas dos décadas, pero un importante punto de inflexión fue cuando los de verde lanzaron la arquitectura Tesla, allá por el año 2006. En este artículo vamos a echar la vista atrás para ver cómo ha evolucionado la arquitectura de NVIDIA desde Tesla hasta Turing, la arquitectura actual (a falta de la llegada de Ampere), y más concretamente cómo lo han hecho sus SM (Stream Multiprocessors).
En este artículo vamos a repasar cómo ha ido evolucionando la arquitectura de NVIDIA desde Tesla hasta Turing, así que es un buen momento para ponernos en antecedentes y ver qué tenía de particular cada una de estas arquitecturas, las cuales podéis encontrar resumidas en la siguiente tabla.
| Año | Arquitectura | Serie | Die | Proceso litográfico | Gráfica más representativa |
|---|---|---|---|---|---|
| 2006 | Tesla | GeForce 8 | G80 | 90 nm | 8800 GTX |
| 2010 | Fermi | GeForce 400 | GF100 | 40 nm | GTX 480 |
| 2012 | Kepler | GeForce 600 | GK104 | 28 nm | GTX 680 |
| 2014 | Maxwell | GeForce 900 | GM204 | 28 nm | GTX 980 Ti |
| 2016 | Pascal | GeForce 10 | GP102 | 16 nm | GTX 1080 Ti |
| 2018 | Turing | GeForce 20 | TU102 | 12 nm | RTX 2080 Ti |
El punto muerto: la era anterior a NVIDIA Tesla
Hasta la llegada de Tesla en 2006, el diseño de GPUs de NVIDIA iba correlacionado a los estados lógicos de su API de renderizado. La GeForce 7900 GTX, potenciada por el die G71, estaba fabricado en tres secciones (una dedicada al procesado de vértices (8 unidades), otra para la generación de fragmentos (24 unidades) y otra para la unión de estos (16 unidades)).
Esta correlación obligó a los diseñadores e ingenieros a tener que imaginar la localización de los cuellos de botella para poder equilibrar cada capa adecuadamente. A esto había que sumarle la llegada de DirectX 10 con el sombreado de geometría, así que los ingenieros de NVIDIA se encontraron entre la espada y la pared con la difícil tarea de equilibrar el die sin saber cuándo y de qué manera se iba a adoptar la siguiente etapa de las APIs gráficas.
Era el momento de cambiar la forma de diseñar su arquitectura.
La arquitectura NVIDIA Tesla
NVIDIA resolvió el problema de la creciente complejidad con su arquitectura Tesla, la primera «unificada», en 2006. Con su die G80 ya no había distinción entre capas. Los Stream Multiprocessor (SM) reemplazaron todas las unidades anteriores gracias a su capacidad de ejecutar procesado de vértices, generación de fragmentos y unión de fragmentos sin distinción en un único kernel. Así, además, la carga se equilibra automáticamente al intercambiar los «núcleos» ejecutados por cada SM dependiendo de las necesidades de cada momento.
Así pues, los Shader Units ahora son los «cores» (ya no compatibles con SIMD) que son capaces de gestionar un entero o una instrucción float32 por sí mismos (los SM reciben hilos en grupos de 32 llamados warps). Idealmente, todos los hilos de un warp ejecutarán la misma instrucción al mismo tiempo solo que con diferentes datos (de ahí el nombre SIMT). La unidad de instrucción de subprocesos múltiples (MT) se encarga de habilitar y deshabilitar hilos en cada warp en el caso de que los punteros de instrucciones (IP) converjan o difieran.
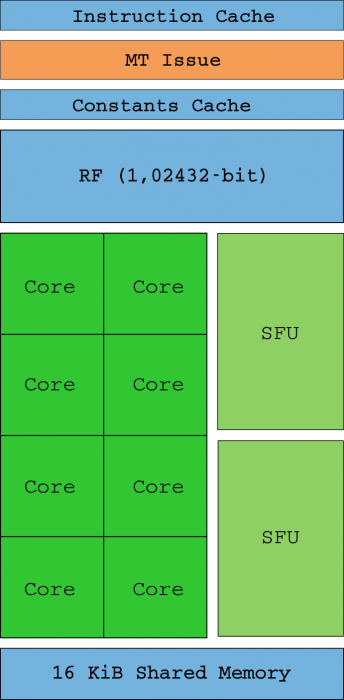
Dos unidades SFU (podéis verlas en el diagrama de arriba) son las encargadas de ayudar con los cálculos matemáticos complejos como raíces cuadradas inversas, senos, cosenos, exp y rcp. Estas unidades también son capaces de ejecutar una instrucción por cada ciclo de reloj pero dado que solo hay dos, la velocidad de ejecución se divide entre cuatro por cada una de ellas (es decir, hay un SFU por cada cuatro cores). No hay soporte de hardware para cálculos de float64, y estos se realizan por software reduciendo sensiblemente el rendimiento.
Un SM funciona a su máximo potencial cuando se puede eliminar la latencia de la memoria al tener siempre warps programables en la cola de ejecución, pero también cuando el hilo de un warp no tiene divergencias (para eso está el flujo de control, que los mantiene siempre en la misma ruta de instrucciones). El archivo de registro (RF de 4 KB) es donde se almacenan los estados del hilo, y los subprocesos que consumen demasiada cola de ejecución reducen cuántos de ellos se pueden mantener en dicho registro, reduciendo también el rendimiento.
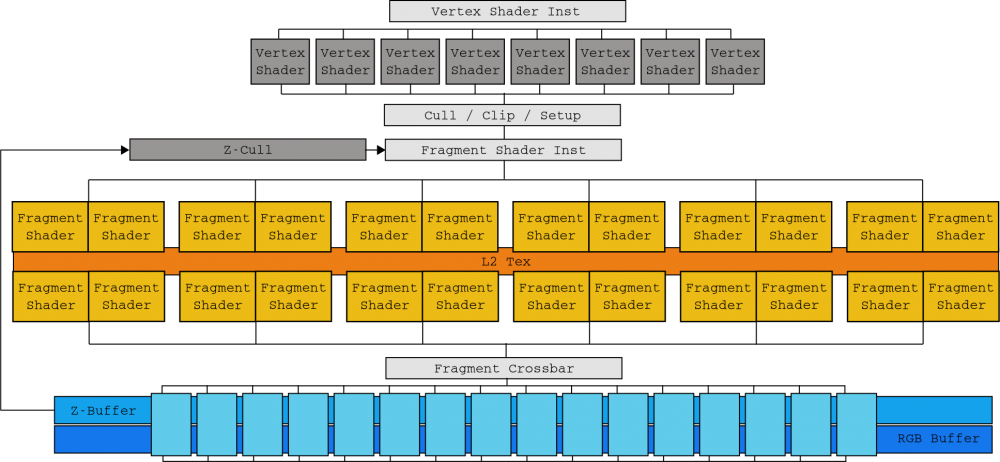
El die «buque insignia» de esta arquitectura NVIDIA Tesla fue el G90 basado en un proceso litográfico de 90 nanómetros, presentado con las famosas GeForce 8800 GTX. Dos SM se agrupan en un clúster de procesador de texturas (TPC) junto con una unidad de texturas y caché Tex L1. Con 8 TPC, el G80 contaba con 128 cores generando 345,6 GFLOPs de potencia bruta. La GeForce 8800 GTX fue inmensamente popular en aquellos tiempos.
Con la arquitectura Tesla, NVIDIA también introdujo el lenguaje de programación CUDA (Compute Unified Devide Architecture) en C, un superconjunto de C99, que representó todo un alivio para los entusiastas de GPGPU que dieron la bienvenida a una alternativa para engañar a la GPU con sombreadores y texturas GLSL.
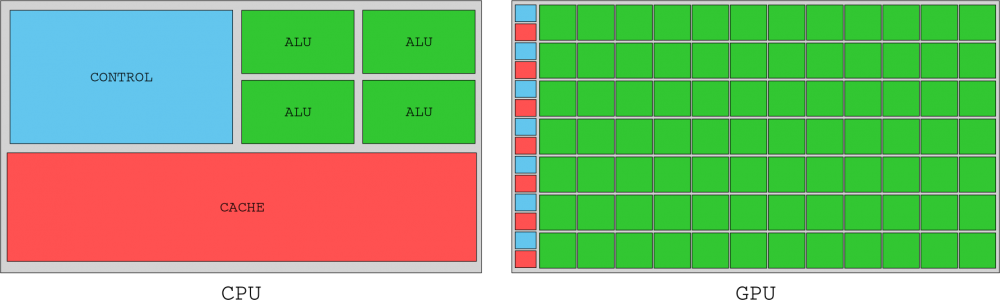
Aunque esta sección se centraba ampliamente en los SM, eran solo la mitad del sistema. Los SM necesitan ser alimentados con instrucciones y datos que residen en la memoria gráfica de la GPU, así que para evitar el estancamiento, las GPU no evitan los «viajes» de memoria con un montón de memoria caché como hacen los procesadores (CPU), sino que saturan el bus de memoria para las peticiones de E/S de los miles de subprocesos que gestionan. Para esto, en el chip G80 se implementó un alto rendimiento de memoria a través de seis canales de memoria DRAM bidireccionales.
Arquitectura Fermi
Tesla fue un movimiento muy arriesgado pero que resultó ser muy bueno, y tuvo tanto éxito que se convirtió en la base de las arquitecturas de NVIDIA durante las próximas dos décadas. En 2010, NVIDIA lanzó el die GF100 basado en la nueva arquitectura Fermi, con numerosas novedades en su interior.
El modelo de ejecución todavía gira en torno a warps de 32 hilos programados en un SM, y fue solo gracias a su litografía a 40 nm (frente a los 90 nm de Tesla) que NVIDIA cuadruplicó prácticamente todo. Un SM ahora puede programar dos medios-warps (16 hilos) de manera simultánea gracias a dos conjuntos de 16 núcleos CUDA. Con cada núcleo ejecutando una instrucción por ciclo de reloj, un solo SM era capaz de ejecutar una instrucción warp por ciclo (y esto es 4 veces la capacidad de los SM de Tesla).

El recuento de SFU también se reforzó, aunque menos porque «solo» se multiplicó por dos, con cuatro unidades en total. También se incorporó soporte de hardware para cálculos float64, cosa de lo que carecía Tesla, llevados a cabo por dos núcleos CUDA combinados. El GF100 podía hacer una multiplicación de enteros en un solo ciclo de reloj gracias a una ALU de 32 bits (frente a 24 bits en Tesla) y tiene una mayor precisión float32.
Desde la perspectiva de la programación, el sistema de memoria unificado de Fermi permitió que CUDA C se aumentara con características de C++ como objetos y métodos virtuales.
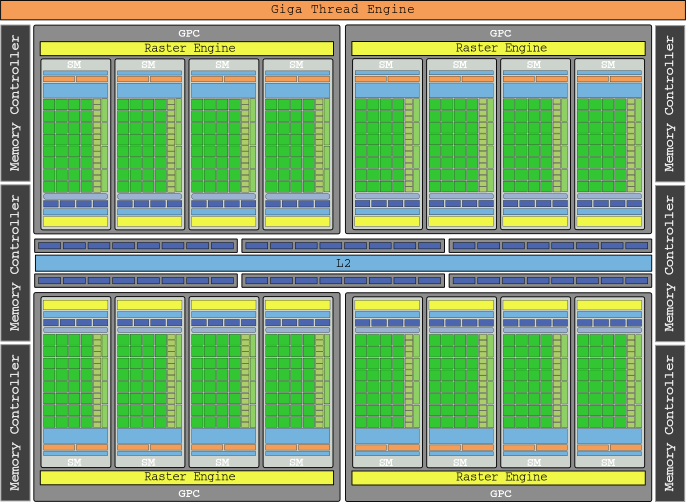
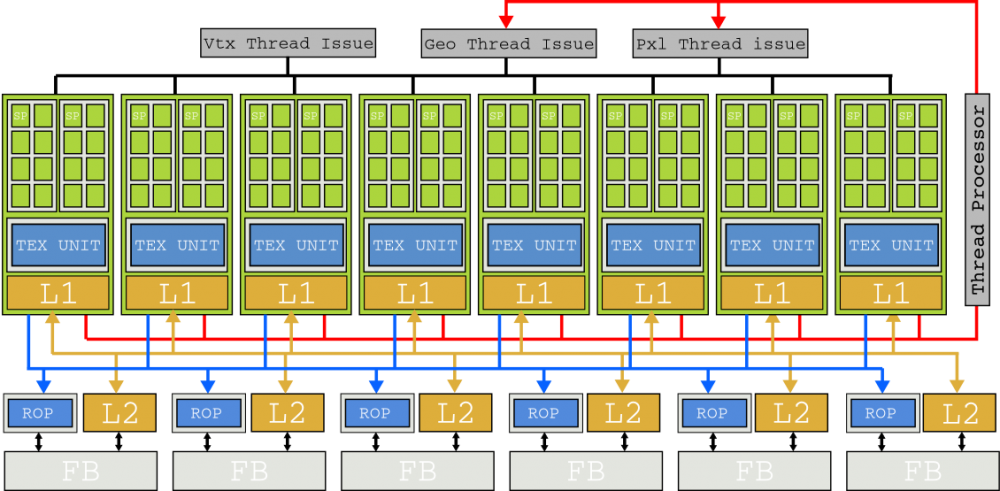
Con las unidades de texturas ahora parte de los SM, el concepto de TPC desapareció, reemplazado por los clústeres de procesador de gráficos (GPC) que cuentan con cuatro SM. Por último pero no menos importante, se añadió un motor «Polymorph» que se encarga de la obtención de vértices de los objetos, la transformación de la vista y el teselado. La gráfica buque insignia de esta generación fue la GTX 480, que con sus 512 cores tenía 1.345 GFLOPs de potencia bruta.
Arquitectura NVIDIA Kepler
En 2012 llegó la arquitectura NVIDIA Kepler, con la que se mejoró drásticamente la eficiencia energética de su die bajando su velocidad de reloj y unificando el reloj central con el de la tarjeta (solían tener una frecuencia del doble), solucionando así el problema de las GTX 480 de generación anterior (se calentaban mucho y tenían un consumo muy elevado).
Estos cambios deberían haber resultado en un rendimiento más bajo, pero gracias a la implementación del proceso litográfico a 28 nm y la eliminación del programador por hardware en favor de uno por software, NVIDIA pudo no solo meter más cantidad de SM sino también mejorar su diseño.

El «multiprocesador de transmisión de próxima generación», conocido como SMX, resultó ser un monstruo donde casi todo se había duplicado o incluso triplicado. Con cuatro programadores de warp capaces de procesar un warp completo en un ciclo de reloj (en comparación con el diseño de dos mitades de Fermi), el SMX ahora contiene 196 núcleos. Cada programador tiene un despacho doble para ejecutar una segunda instrucción en un warp si es independiente de la instrucción actualmente ejecutada, aunque esta doble programación no siempre era factible.
Este enfoque hizo la lógica de programación más complicada, pero con hasta seis instrucciones de warp por reloj, un SMX Kepler proporción el doble de rendimiento que un SM de Fermi.
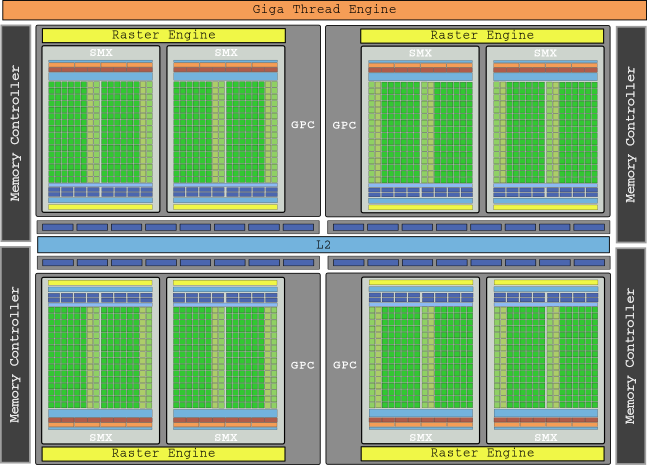
La gráfica buque insignia de esta generación fue la GeForce GTX 680 con su die GK104 y 8 SMX, que contenían la increíble cantidad de 1536 núcleos y que proporcionaban en total hasta 3.250 GFLOPs de potencia bruta.
Arquitectura NVIDIA Maxwell
En 2014 llegó la arquitectura NVIDIA Maxwell, sus GPU de décima generación. Como explicaban en su documentación técnica, el alma de estas GPUs era una «eficiencia energética extrema y un rendimiento excepcional por vatio consumido», y es que NVIDIA orientó esta generación a sistemas de energía limitada como mini PCs y portátiles.
La decisión principal fue abandonar el enfoque de Kepler del SMX y volver a la filosofía de Fermi de trabajar con medios warps. Así, por primera vez en su historia, el SMM presenta menos núcleos que su predecesor con «solo» 128 núcleos. Tener el número de núcleos ajustado al tamaño del warp mejoró la estructura del die, lo que resultó en un gran ahorro de espacio ocupado y de energía consumida.
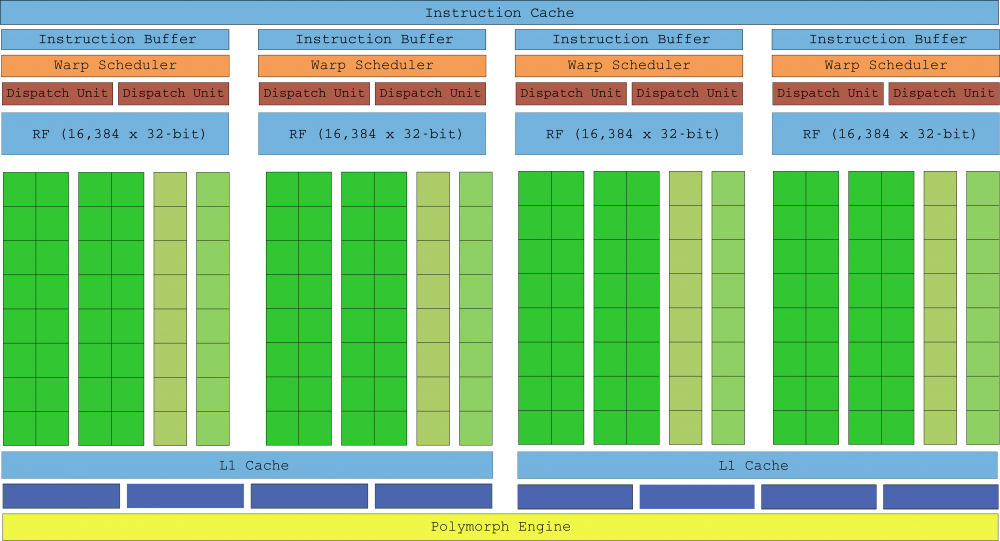
La segunda generación de Maxwell mejoró significativamente el rendimiento al tiempo que conservó la eficiencia energética de la primera generación. Con el proceso litográfico todavía estancado en los 28 nm, los ingenieros de NVIDIA no podían confiar en la miniaturización de los transistores para mejorar el rendimiento, y sin embargo menos núcleos por SMM redujeron su tamaño, lo que les permitió poder meter mayor número de SMM en el mismo die. Maxwell Gen 2 contiene el doble de SMM que Kepler con solo un 25% más de área en su die.
En la lista de mejoras también debemos mencionar una lógica de programación más simplificada que redujo el recálculo redundante de las decisiones de programación, lo cual redujo la latencia de cálculo para proporcionar una mejor ocupación de warps. El reloj de memoria también se aumentó un 15% de media.
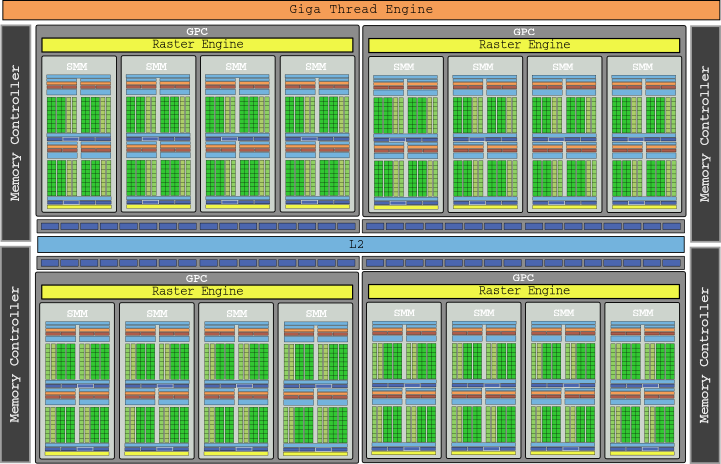
El diagrama del chip GM200 que vemos arriba ya empieza casi a hacer daño a la vista, ¿verdad? Es el die que incorporaban las GTX 980 Ti, con 3072 núcleos en 24 SMM y que proporcionaban una potencia bruta de 6.060 GLOPs.
Arquitectura NVIDIA Pascal
En 2016 llegó la siguiente generación, NVIDIA Pascal, y la documentación técnica parecía casi un calco de los SMM de Maxwell. Pero que no haya cambios en los SM no significa que no hubiera mejoras, y de hecho el proceso de 16 nm utilizado en estos chips mejoró sustancialmente el rendimiento al poder meter más SM en el mismo chip.
Otras mejoras importantes a destacar fueron el sistema de memoria GDDR5X, toda una novedad que proporcionaba velocidades de transferencia de hasta 10 Gbps gracias a ocho controladores de memoria, con su interfaz de 256 bits proporcionando un 43% más de ancho de banda que la generación anterior.
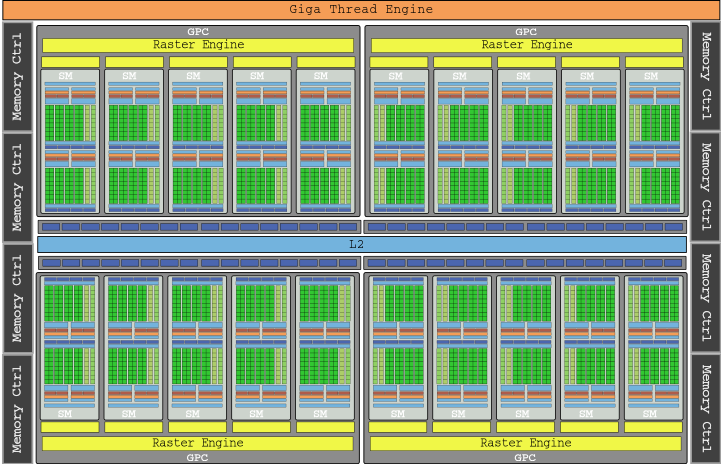
La gráfica buque insignia de la generación Pascal fue la GTX 1080 Ti, con su die GP102 que podéis ver en la imagen de arriba y sus 28 SM, empacando en total 3584 núcleos para una potencia bruta de 11.340 GLOPs (ya estamos en 11,3 TFLOPs).
Arquitectura NVIDIA Turing
Lanzada en 2018, la arquitectura Turing supuso el «mayor salto arquitectónico en más de una década» (según palabras de NVIDIA). No solo se añadieron los SM Turing, sino que se introdujo por primera vez hardware para Ray Tracing dedicado, con los Tensor Cores y los núcleos RayTracing. Esto diseño supone que se volvió a «fragmentar» el die, al estilo de capas de la era pre-Tesla de la que os hemos hablado al principio.
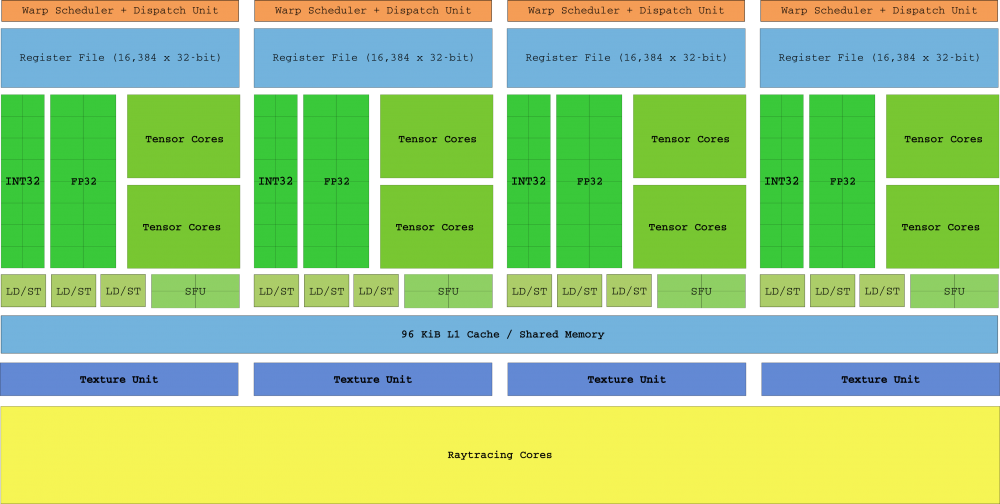
Además de los nuevos núcleos, Turing añadió tres características principales: primero, el núcleo CUDA ahora es escalable y capaz de ejecutar tanto intrucciones de enteros como de coma flotante en paralelo (esto a muchos os recordará a la arquitectura «revolucionaria» Intel Pentium allá por el año 1996). En segundo lugar, el nuevo sistema de memoria GDDR6 respaldado por 16 controladoras, que ahora puede alcanzar los 14 Gbps, y finalmente los hilos que ya no comparten punteros de instrucciones en los warp.
Gracias a la programación de hilos independientes introducida en Volta (que no incluimos aquí ya que es una arquitectura no enfocada al usuario), cada hilo tiene su propia IP y, como resultado, los SM son libres de programar hilos en un warp sin necesidad de esperar a que converjan los antes posible.

La gráfica tope de gama de esta generación es la RTX 2080 Ti, con su die TU102 y 68 TSM que contiene 4352 núcleos, con una potencia bruta de 13,45 TFLOPs. No ponemos su diagrama completo de bloques como en las anteriores porque para que cupiera en la pantalla habría que encogerlo tanto que sería una mancha borrosa.
¿Y qué viene después?
Como bien sabéis la próxima arquitectura de NVIDIA se llama Ampere, y llegará seguramente ya con el nodo de fabricación a 7 nm de TSMC. Actualizaremos este artículo en el momento en el que estén disponibles todos los datos.