
VLIW son las siglas de Very Long Instruction Word, lo que se traduce como instrucción de palabra muy larga. En el mundo de la arquitectura de procesadores se utiliza para definir un tipo de CPU o procesador que alcanza el paralelismo de instrucciones o ILP, pero con una metodología distinta a la utilizada en los procesadores superescalares que es la que se utiliza habitualmente en las CPUs.
Las CPU del tipo VLIW tienen una serie de ventajas y desventajas en comparación con el resto de procesadores y no solo se han visto siendo utilizadas en CPUs, sino también como unidades shader de las GPU y también en los DSP.
A día de hoy los diseños VLIW parece que han desaparecido del hardware del PC, no obstante siguen siendo una opción válida en el diseño de nuevos procesadores para los diferentes ámbitos del mercado del hardware pese a su desuso.
¿Cómo funciona un procesador VLIW?
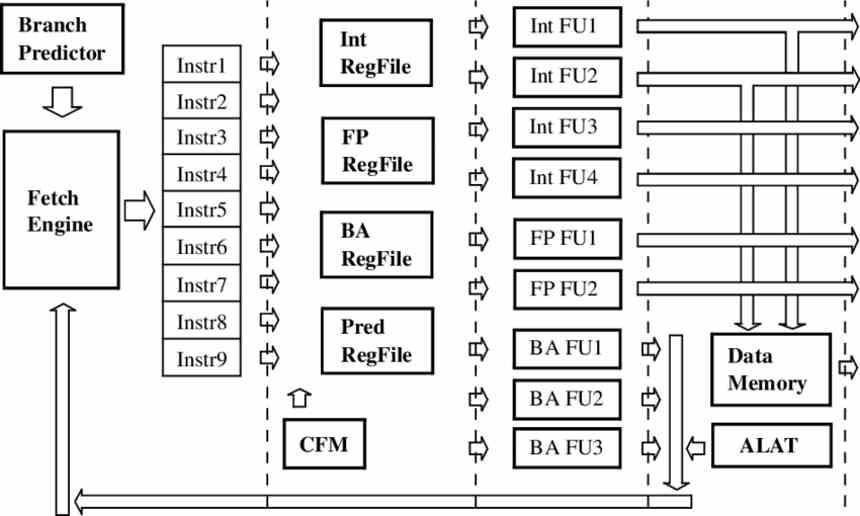
En un procesador superescalar o ILP convencional las instrucciones son captadas y tratadas individualmente durante el ciclo de instrucción de cada una. Ya sea si estamos hablando de una ejecución in-order o de una out-of-order. En el caso de un procesador VLIW lo que se hace es agrupar varias instrucciones en una sola y enviarlas en conjunto a las diferentes unidades que hay disponibles en el procesador.
Para conseguir esto los procesadores VLIW dependen enormemente del compilador a la hora de generar el código binario, el cual agrupará las diferentes instrucciones en una sola instrucción, siempre teniendo en cuenta el nivel de ocupación de cada una de las unidades de ejecución en cada momento de la ejecución, lo cual dependerá de la cantidad de ciclos de reloj que requiere cada una de las instrucciones.
Dado que las instrucciones pueden tener diferentes grados de duración en cuanto a ciclos de reloj esto supone un problema de rendimiento, ya que durante varios ciclos de reloj tendremos unidades de ejecución que no harán nada y que estarán ejecutando una instrucción NOP, lo cual significa que durante ese ciclo de reloj dicha unidad no realiza ninguna operación. Esto hace que los procesadores VLIW dependan enormemente del compilador para su máxima eficiencia.
Ventajas y desventajas de un diseño VLIW

Principalmente las ventajas que aporta son las siguientes:
- El hardware encargado de la descodificación de las instrucciones es mucho más simple que una CPU ILP o TLP, esto permite dejar más espacio libre en el chip para unidades de ejecución y por tanto poder ejecutar más instrucciones al mismo tiempo.
- El tener un mayor espacio permite también colocar una mayor cantidad de registros, lo cual es ideal para facilitar la ejecución especulativa típica de los procesadores fuera de orden sin la necesidad de un búfer de ordenación.
En cuanto a sus desventajas la primera de ellas está en el hecho de que se requiere un compilador mucho más complejo, siendo la segunda la que os hemos comentado antes y que se basa en que hay un mayor desaprovechamiento de las diferentes unidades de ejecución, ya que la mayoría se van a pasar un buen tiempo desocupadas.
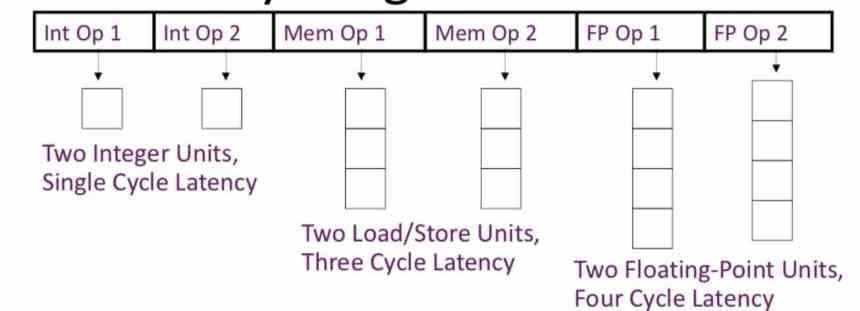
Para entenderlo mejor, imaginad que tenéis agrupadas en un VLIW 3 instrucciones que necesitan la primera 4 ciclos de ejecutarse, la segunda 7 ciclos y la tercera 10 ciclos. La unidad de ejecución encargada de realizar la primera instrucción estará 6 ciclos de reloj sin hacer nada, la segunda 3 y todo ello porque la tercera necesitará 10 ciclos para funcionar.
Por otro lado, hemos de agregar el hecho que aunque a nivel de instrucción los binarios no cambien, a la hora de desarrollar una nueva CPU es posible que una instrucción ya existe aumente o disminuya la cantidad de ciclos. Esto hace que sea necesario un compilador distinto incluso para nuevas iteraciones de un nuevo procesador, lo cual hace difícil poder lanzar versiones más avanzadas de un procesador y se requiere en muchos casos la creación de un compilador binario a binario, el cual reordena las instrucciones para la nueva CPU.
Generación de instrucciones por el compilador

Para que podáis entenderlo mejor, hemos preparado un par de listas, la primera es la ejecución en un procesador superescalar o conocido como ILP, la segunda es una CPU del tipo VLIW.
Empezando por un procesador del tipo ILP, un listado de sus instrucciones sería la siguiente:
- Carga A1
- Carga B1
- Carga A2
- Carga B2
- Multiplica los valores de A1 y B1
- Suma los valores de A2 y B2
- Suma A1 y A2
- Carga A3
- Carga B3
- Multiplica A3 por B3
- Suma B1 y B2.
Un procesador VLIW en cambio agrupará varias de las instrucciones en una sola:
- Se carga de manera simultánea las A2 y B2
- Carga A2 y B2, multiplica A1 y B1, suma A2 y B2.
- Carga A3, B3, multiplica A3 por B3 y suma B1 y B2.
El hecho de que hayamos conseguido agrupar las 11 instrucciones en solo 3 instrucciones muy grandes supone que la cantidad de tiempo que requerirá cada una de las instrucciones VLIW como mucho será el tiempo que tarde la instrucción más compleja de la agrupación de instrucciones.
Acceso a memoria de este tipo de procesadores

Como hemos comentado antes, los procesadores VLIW dependen del compilador y muchas veces estos agregan instrucciones NOP al código durante la compilación. El motivo de hacerlo es porque crear una CPU VLIW con instrucciones de tamaño variable es sumamente complejo, por lo que se hace es crear un tamaño fijo de bits al que la CPU lee las instrucciones y captar desde la memoria en cada ciclo esa cantidad de datos e instrucciones.
Esto se traduce en que los procesadores VLIW requieren buses de datos mucho más anchos que las CPUs convencionales por el hecho que agrupan una gran cantidad de bits cada vez que captan nuevas instrucciones a ejecutar. Siendo este su gran talón de Aquiles, ya que en los procesadores ILP, comunes en las CPUs de PC, se utilizan anchos de datos más estrechos y por tanto controladores de memoria más sencillos.
Lo normal en los procesadores VLIW es que estos vayan captando las siguientes instrucciones a ejecutar mientras se ejecuta la actual instrucción VLIW. Ya que al agrupar varias instrucciones en una sola, el tiempo de captación de cada una de ellas por separado se reduce.