
Hopper es el nombre en clave con el que se conoce desde hace un par de años una futura GPU compuesta por chiplets por parte de NVIDIA. Pues bien, parece ser que NVIDIA ha finalizado el diseño de Hopper y por tanto estaría ya lista para la preproducción. Lo que nos indica que estamos a menos de un año de su presentación y lanzamiento.
Las GPU de alto rendimiento están cambiando, ya que están evolucionando de ser chips monolíticos a ser diseños por varios chips o chiplets. Tenemos el caso de los siguientes CDNA de AMD con arquitectura Aldebaran que se componen de dos GPU conectadas entre sí, pero el máximo exponente son los Intel Xe-HP y Xe-HPC que también serán GPUs compuestas por varios chips. Lo cual no se debe confundir con varias GPUs en un MCM.
¿Y qué hay de NVIDIA? Pues parece ser que su arquitectura de GPU basada en chiplets con nombre en clave Hopper podría haber finalizado ya si diseño. Veamos cuáles son los detalles.
La NVIDIA Hopper habría llegado al final de su fase de diseño
De la arquitectura NVIDIA Hopper empezamos a oír a hablar hace más de dos años. Siendo en realidad la primera vez que oímos hablar de una GPU descompuesta en varios chips o chiplets en una configuración MCM. Algo que por aquel entonces nos parecía una solución exótica, pero que con la inminente salida de AMD CDNA 2 y los Intel Xe-HP y Xe-HPC ya no es algo que parezca de ciencia ficción, sino que se trata de una tendencia clara.
Pues bien, ayer un tal Greymon55 quien se ha hecho famoso con el tiempo a la hora de filtrar los mapas de ruta AMD ha dejado ir que NVIDIA Hopper tras un largo tiempo, había pasado la fase de diseño previa a la prefabricación y por tanto la arquitectura final se habría terminado. Dada la existencia de Lovelace como la arquitectura rumoreada para la RTX 40, se espera que Hopper vaya al mercado de la computación de alto rendimiento. Siendo el sucesor del chip A100, el cual fue lanzado en mayo de 2020. Por lo que estaríamos hablando de una cadencia de dos años.
El lanzamiento por tanto coincidiría con el lanzamiento de Lovelace, de la que se dice que compartirá el nodo de 5 nm de TSMC en su fabricación. Al igual que ocurre con las GPU HPC y las GPU gaming de NVIDIA, estas podrían tener diferencias sustanciales en cuanto a su organización interna.
¿Se trata realmente de una nueva arquitectura?
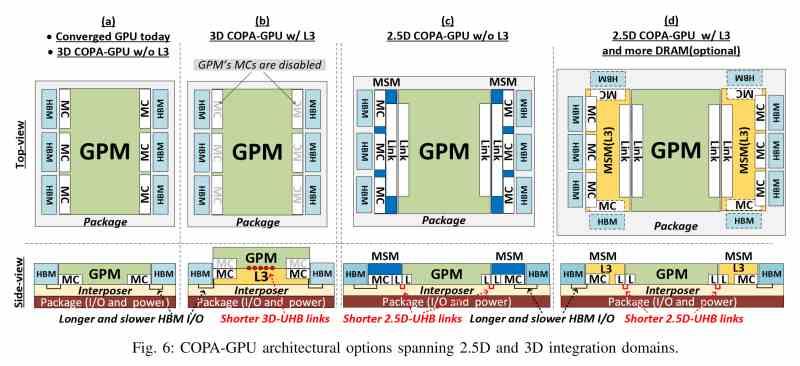
La respuesta es que todavía no lo sabemos, pero hace unos meses aparecieron referencias de nuevo a un diseño de GPU MCM por parte de NVIDIA, en concreto en un paper donde lo bautizaron como COPA-GPU. Dado que Hopper es la única arquitectura futura de NVIDIA que conocemos de esta naturaleza entonces está claro que en el paper se hacía referencia a Hopper. ¿La principal novedad? El añadido de un nivel adicional de caché en la organización de la memoria.
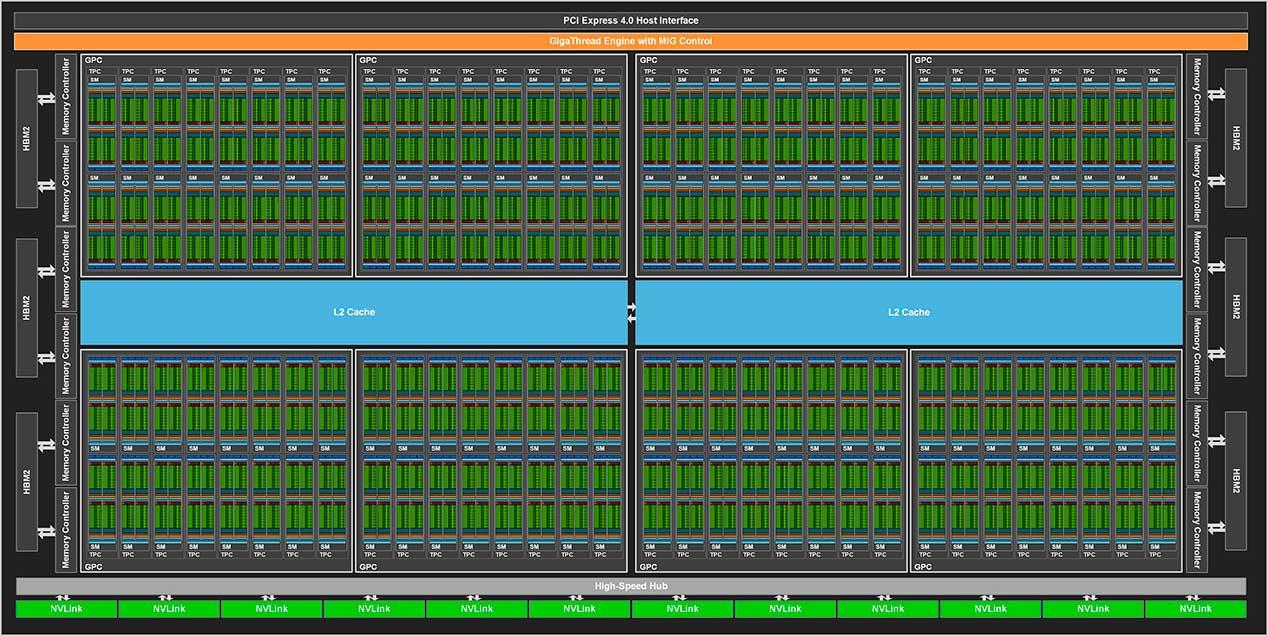
Al mismo tiempo el actual chip A100 utilizado en las NVIDIA Tesla tiene una organización curiosa, ya que está organizada internamente como si fueran dos GPUs en un solo chip. Lo cual se ve patente por el hecho que su caché L2 está separada. Si nos atenemos al diseño de la COPA-GPU entonces NVIDIA habría añadido un nivel adicional de caché, movimiento también adoptado por AMD y que permitiría una comunicación fluida y coherente entre los diferentes chiplets que formarían la GPU.
kopite7kimi@kopite7kimiI should explain that.
A GPM of GH100 could have 8(4*2, it seems like GA100)GPC*9Clusters(big changes, add CPCs).
perf: GH100=3XGA10024 de mayo, 2024 • 07:28
60
3
Según Kopite7Kimi, quien ha demostrado su fiabilidad a la hora de filtrar informaciones de NVIDIA con meses de antelación. Ya habló de la configuración que tendrá Hopper, la cual supone un cambio profundo respecto a la organización interna que las GPU de NVIDIA durante generaciones. La cual hasta ahora era GPC → TPC → SM para pasar a ser GPC → TPC → CPC→ SM. Lo que indicaría una composición de 8 GPC, 3 TPC por GPC, 3 CPC por TPC y 2 SM por CPC. Lo que indicaría un total de 144 SM por cada chiplet en Hopper. En todo caso, aún hemos de esperar la información final de NVIDIA. Pero parece ser que el diseño de Hopper ya ha sido terminado, ahora solo hace falta esperar a su presentación.