
Las GPU basada en chiplets son un tema que se lleva rumoreando desde hace tiempo, especialmente porque uno de los problemas con los que tanto NVIDIA como AMD se han enfrentado en los últimos años es a la hora de escalar sus GPUs más allá de los limites físicos. ¿Cómo serán y cual es la motivacion para esta nueva forma de diseñar las GPUs?
Si hacemos una observación de las GPUs lanzadas en los últimos tiempos tanto por parte de AMD, pero especialmente por parte de NVIDIA, podremos observar que el área que ocupan es cada vez mayor y si hace unos años una GPU de más 400 mm2 era visto como algo de gran tamaño, ahora las tenemos por encima de los 600 mm2.

Esta tendencia hace que exista el peligro en que se alcance el limite de la retícula llegados a un momento determinado, dicho limite es el área limite que puede tener un chip en un nodo de fabricación dado y de manera peligrosa, y la cosa se complica si aumentamos de manera indiscriminada la cantidad de núcleos que componen una GPU.
El símil de las estaciones y los trenes

Suponed que tenemos una red ferroviaria con varias estaciones de tren, cada una de ellas es un procesador y los trenes son los paquetes de datos que se van enviando.
Obviamente si nuestra red ferroviaría incluye cada vez más número de estaciones entonces vamos a necesitar cada vez más vías y una infraestructura más compleja. Pues en el caso de un procesador es igual ya que aumentar la cantidad de elementos supone aumentar la cantidad de vías de comunicación entre los diferentes elementos.
El problema es que esas vías de tren adicionales también van a suponer un aumento del consumo energético, por lo que quien se dedique a diseñar la red ferroviaría no solo tiene que tener en cuenta cuantas vías puede colocar en la infraestructura sino también el consumo energético de la misma.
La Ley de Moore no escala tanto como se cree
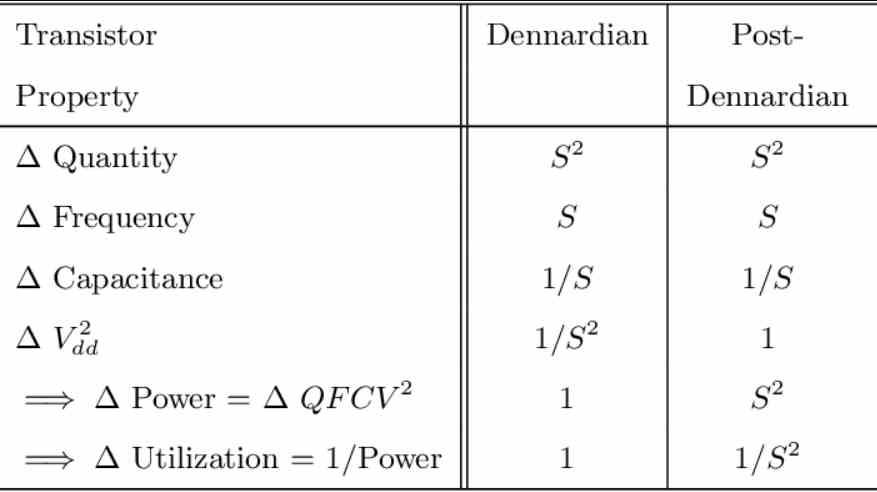
Según la Ley de Moore la densidad en número de transistores por área se duplicaba cada x tiempo de manera regular, esto iba acompañado de la escala de Dennard, que nos indicaba que velocidad de reloj pueden escalar con cada nuevo nodo de fabricación. La escala de Dennard original cambio su métrica a partir del nodo de 65 nm en adelante.
El problema viene cuando aumentamos la cantidad de elementos/trenes y las vías de comunicación, podemos colocar el doble de elementos pero lo que no podemos hacer es asegurarnos es tener el ancho de banda necesario para comunicar todos esos elementos al mismo tiempo bajo el mismo consumo dado, cosa que es imposible y esto limita la cantidad de núcleos, en el caso de las GPUs la cantidad de Compute Units.

¿La solución que se ha tomado siempre? En vez de añadir más elementos lo que se ha hecho es hacer estos cada vez más complejos,por ejemplo en el caso de las GPUs es el camino que tomo NVIDIA a partir de Turing, en vez de aumentar la cantidad de SMs respecto a Pascal lo que hizo fue añadir elementos como los RT Cores, Tensor Cores y hacer cambios profundos en las unidades, ya que aumentar la cantidad de núcleos supone aumentar la cantidad de interconexiones.
Por lo que nos encontramos con el problema del coste energético de la transmisión de datos/trenes, con cada nuevo nodo de fabricación podemos aumentar la cantidad de elementos en un chip pero nos encontramos con que la velocidad de transferencia que necesitamos es cada vez más alta, lo que aumenta el consumo energético, provocando que buena parte de la potencia energética que le damos al procesador cada vez vaya más a la transferencia de datos en vez del procesamiento de datos.
Construyendo una GPU con chiplets a partir de otra conocida
La idea de una construcción de una GPU por chiplets es conseguir construir una GPU que no sea posible fabricar a partir de una construcción monolítica y por tanto basada en un solo chip, por lo que el área de una GPU construida con chiplets ha de ser mayor que lo que permitiría el límite de la retícula, ya que entonces no tendría sentido una GPU de este tipo.
Esto significa que las GPUs compuestas por chiplets estarán reservadas exclusivamente para las gamas más altas y es posible que inicialmente las veamos solamente en el mercado de las GPUs para computación de alto rendimiento, HPC, mientras que en el doméstico estemos unos años más con GPUs mucho más simples en configuración y por tanto monolíticas.
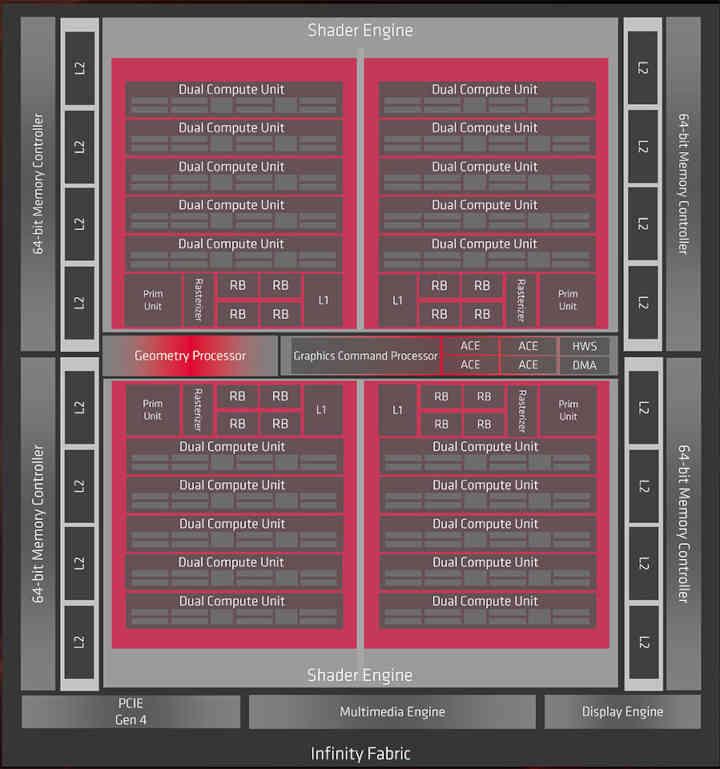
No obstante, hemos decidido tomar el chip Navi 10, con arquitectura RDNA de primera generación como ejemplo pera deconstruirla y crear nuestra GPU compuesta por chiplets, más que nada porque es de las GPUs de última generación la que más datos tenemos encima de la mesa, las GPUs que AMD y/o NVIDIA construyan tendrán mucha más complejidad que este ejemplo, el cual es orientativo para que tengáis una imagen mental de como se construiría una GPU de este tipo.
La primera idea es que cada chiplet sea un Shader Array, los cuales son los conjuntos de elementos que están sobre los recuadros rosados, los cuales están conectados a la cache L1, mientras que vamos a dejar la Cache L2 en un chip central aparte.
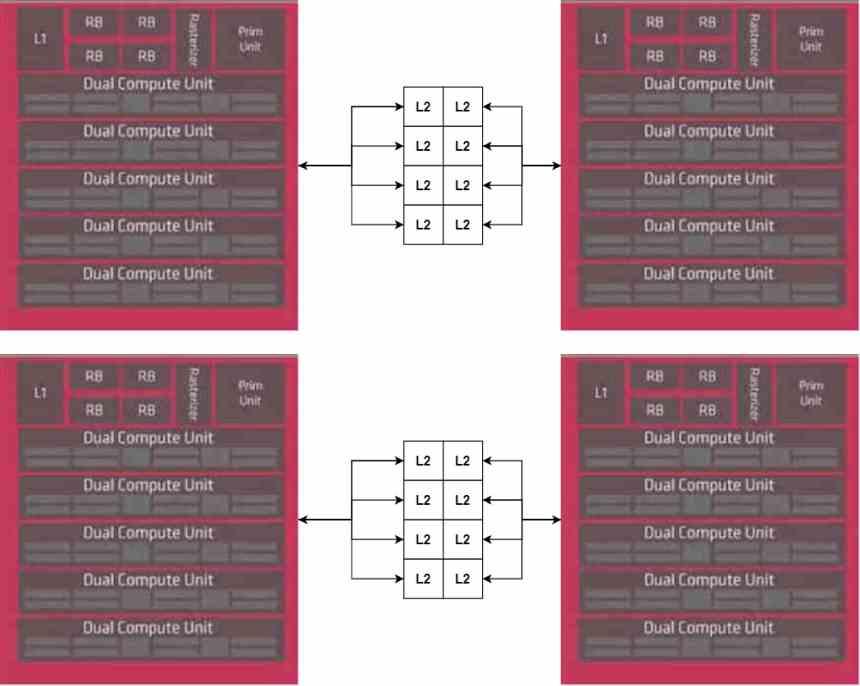
Pero no tenemos la GPU completa, ya que nos falta la parte central de la misma que es el procesador de comandos, el cual al ser una parte única no vamos a duplicar, por la que la colocaremos en la parte central del MCM.
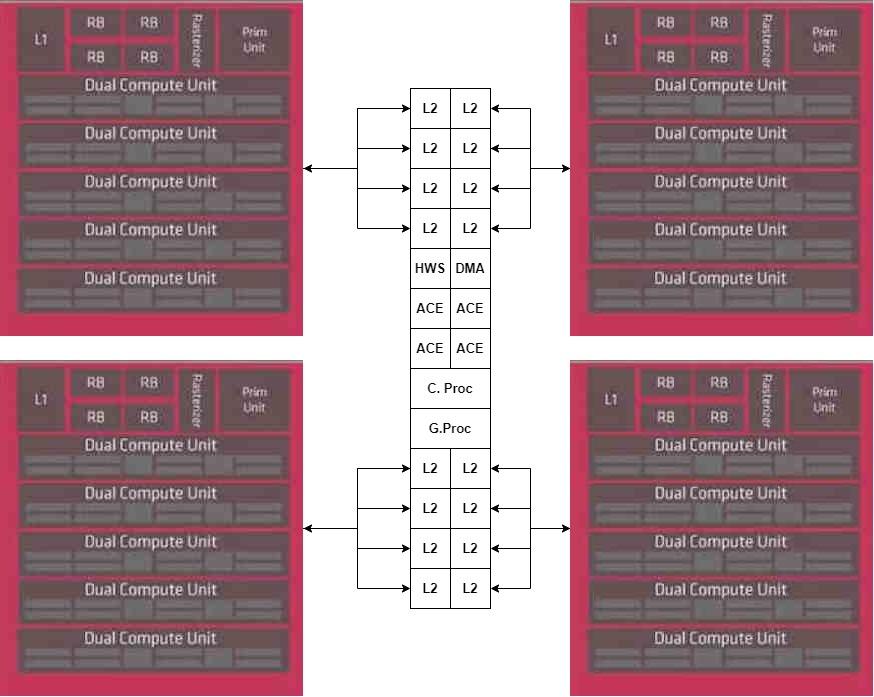
En cuanto a los aceleradores, los colocaremos en un otro chiplet, conectados de manera directa a la unidad DMA del chiplet central.
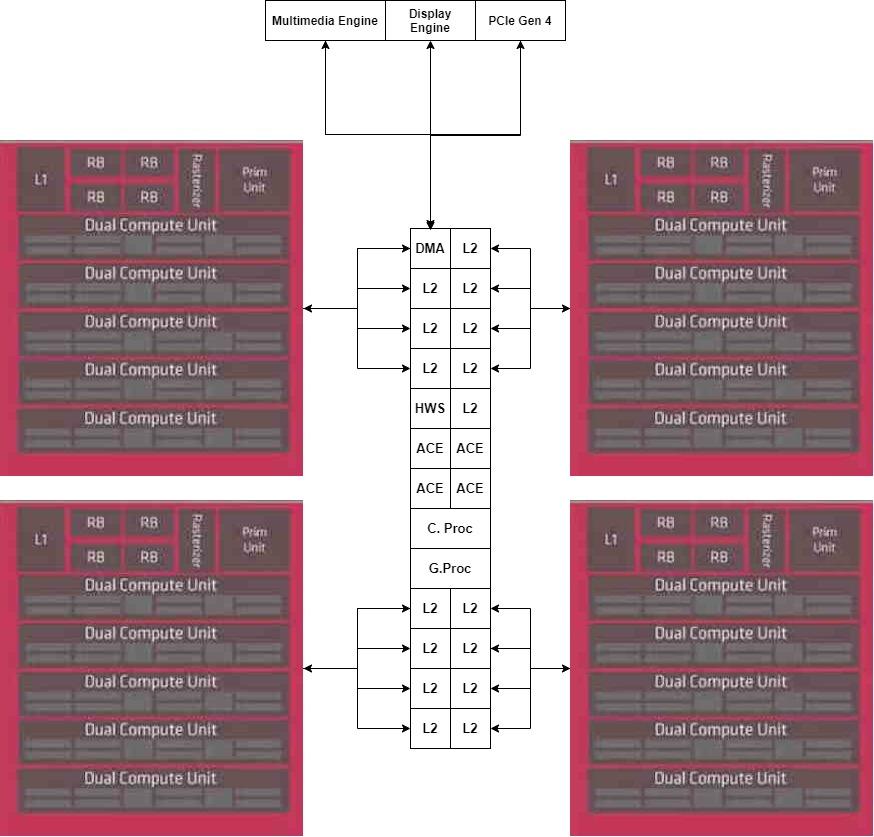
Una vez tenemos ya la GPU descompuesta en varias partes, lo que nos interesa ahora es la comunicación con la memoria externa, de ello se encargará el Interposer, que tendrá integrado el controlador de memoria en su interior. Dado que Navi 10 utiliza una interfaz GDDR6 de 256 bits, 8 chips, hemos decidido mantener dicha configuración en nuestro ejemplo.
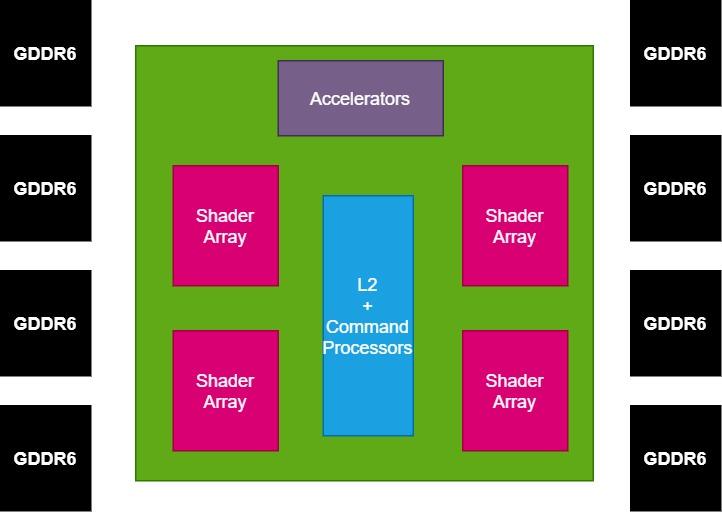
GPU basada en chiplets y consumo energético
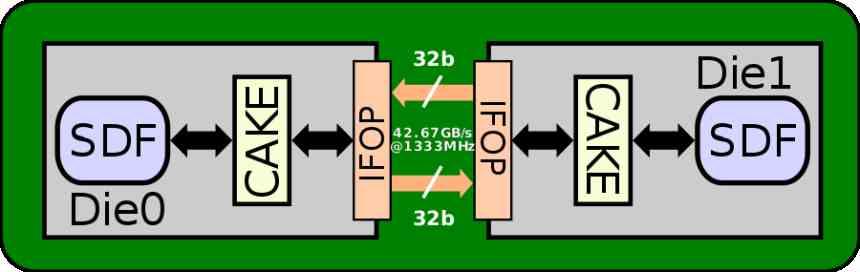
La interfaz utilizada para comunicar elementos de los diferentes chiplets es los MCM de AMD es la interfaz IFOP, la cual tiene un consumo energético de 2 pJ/bit, si miramos las especificaciones técnicas veremos que la cache L2 tiene un ancho de banda 1.95 TB/s a 1905 MHz de velocidad, lo cual son unos 1024 bytes, lo que cuadra con 16 interfaces de 64 bytes/ciclo, 32B/ciclo por dirección.
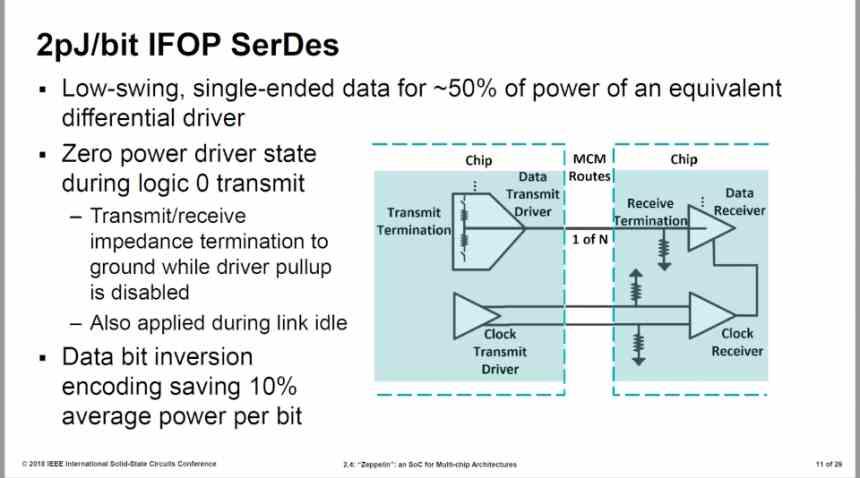
La primera versión del Infinity Fabric hacía uso de interfaces de 32B/ciclo con un consumo de 2 pJ/bit, no obstante AMD mejoro en un 27%
La interfaz IFOP tiene un consumo energético de 1.47 pJ/bit, a una velocidad de 1333 MHz. Si la interfaz fuera a 1905 MHz entonces el consumo energético sería mucho más alto ya que no solo aumentaría la velocidad de reloj sino también el voltaje, pero vamos a suponer que nuestra versión por chiplets de la Navi 10 funciona a esos 1333 MHz de velocidad.
(1.33*10^12)*8 bits por byte*1.47 pJ por bit = 1.56*10^13 pJ =15.6 W
Aunque los 15.6 W nos puede parecer una cifra baja, tened en cuenta que este solo es el consumo de transmitir los datos de los chiplets periféricos con el chiplet central bajo una velocidad de 1333 MHz y que el consumo energético sube cuadráticamente con la velocidad de reloj y el voltaje también aumenta con este.
Esto significa que una buena parte del consumo energético se va directamente al consumo de energía de la comunicación entre chiplets, lo que se traduce en que tanto AMD como NVIDIA tienen que solventar este problema antes de desplegar sus GPUs basadas en chiplets.
El EHP de AMD como ejemplo de GPU basada en chiplets
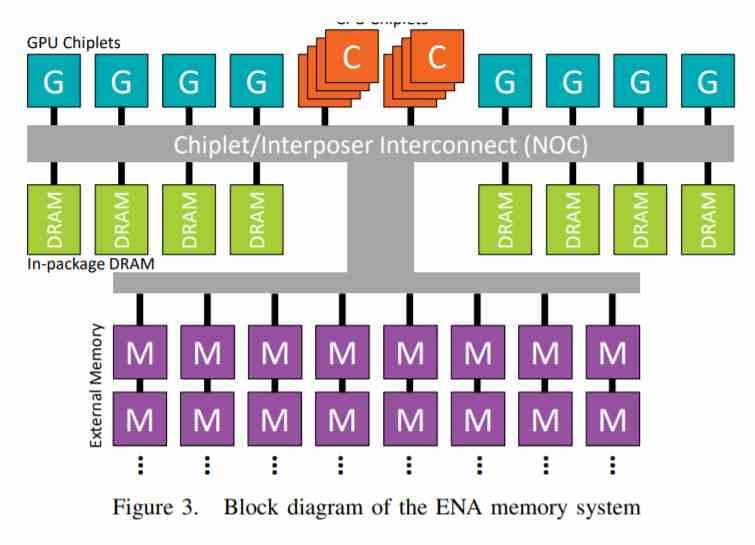
Hace unos años, AMD lanzo un paper en el que describía una procesador basado en chiplets con una GPU sumamente compleja, donde se hablaban de configuraciones de por ejemplo 320 Compute Units en 8 chiplets, lo que se traduce en 40 Compute Units por chiplet, el equivalente a una Navi 10 completa.
Es decir, estamos hablando de una una configuración 8 veces más compleja, así que imaginaos una configuración con 8 chiplets siendo cada uno como una Navi 10/RDNA y funcionando a velocidades por encima de los 2 GHz con un enorme consumo energético.

Este es el motivo por el cual AMD y NVIDIA han desarrollado tecnologías como el X3D y el GRS, las cuales son interfaces de comunicación que tiene un consumo energético por bit transmitido 10 veces inferior que el del actual Infinity Fabric o el NVLink ya que sin un tipo de interfaz de comunicación de ese tipo no es posible el futuro de las GPUs basadas en chiplets.