NVIDIA acaba de publicar un paper a partir del cual se pueden incidir los cambios que podrían sufrir las GPUs de la compañía. En especial aquellos modelos dirigidas de cara a la inteligencia artificial y a la computación de alto rendimiento. Desde el lanzamiento de Volta que NVIDIA ha utilizado una misma COPA-GPU para ambos mercados, pero esto podría cambiar a partir de la siguiente generación.
La poca información que tenemos acerca de la siguiente generación de GPUs de NVIDIA es que podríamos ver dos arquitecturas distintas al mismo tiempo. Por un lado Lovelace sería para el mercado de las GPUs de escritorio y por tanto para la gama GeForce, mientras que Hopper sería para el mercado HPC, alto rendimiento, y el de la inteligencia artificial.
COPA-GPU, el futuro de NVIDIA en IA y HPC
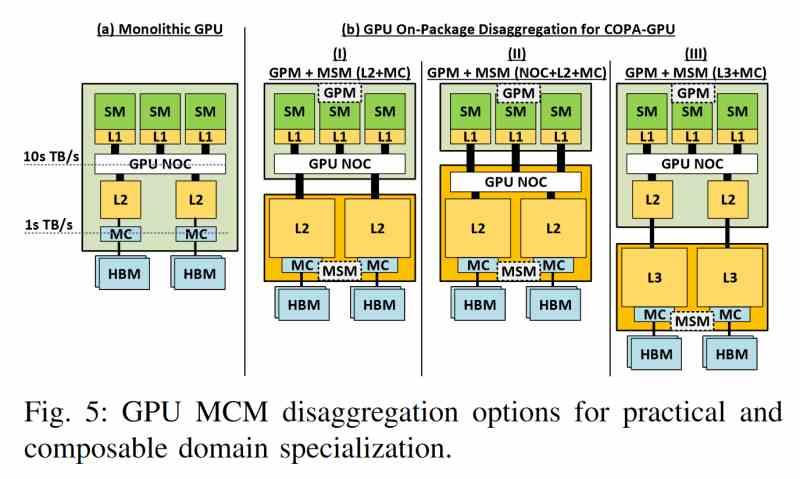
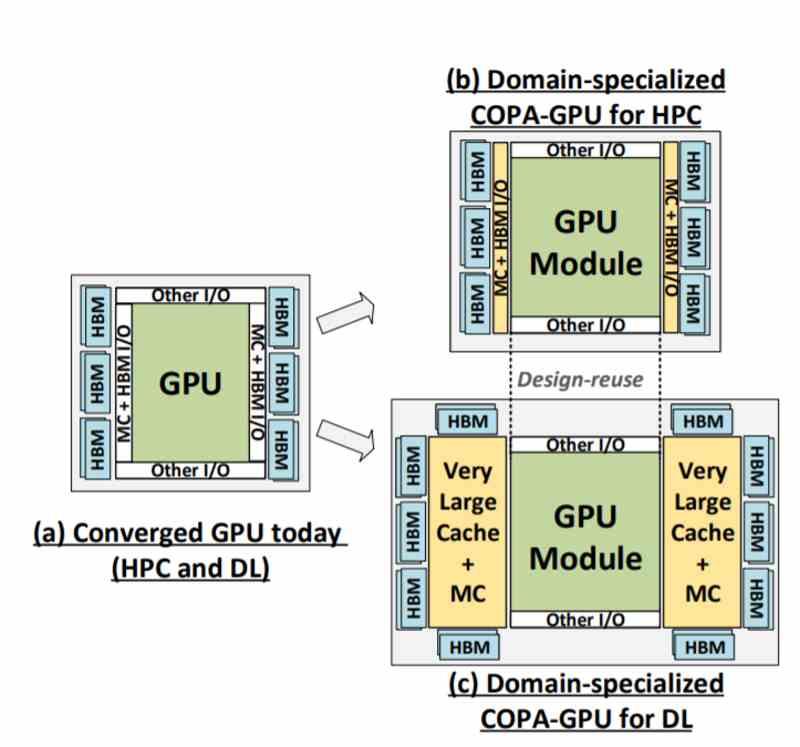
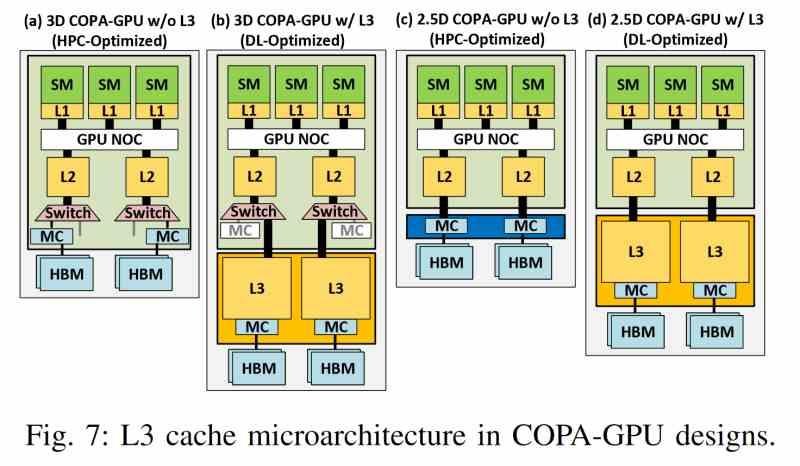
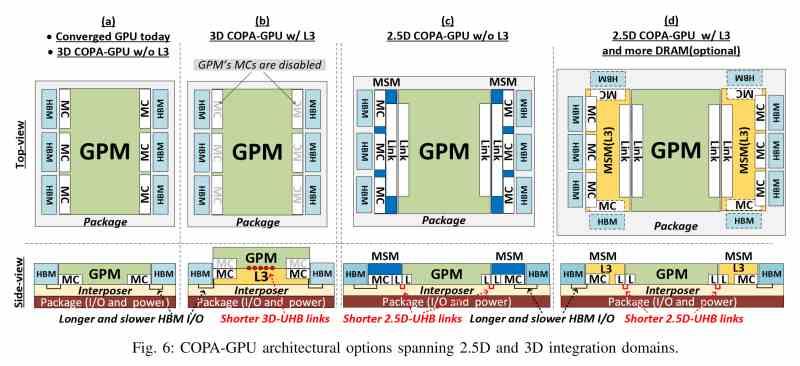
Tanto el chip GV100 como el GA100 son lo que NVIDIA llama Composable On-PAckage o COPA, en realidad no es más que una forma de hablar de un circuito integrado 2.5DIC en el que la GPU está conectada a la memoria HBM a través de un interposer común. Pues bien, NVIDIA podría lanzar dos GPUs distintas esta vez. Donde la diferencia entre ambos diseños vendría por el añadido de una caché L3 por parte de NVIDIA para el modelo de GPU optimizado para Deep Learning.
Mientras que los algoritmos de inteligencia artificial hacen uso de los Tensor Cores, en el caso del mercado HPC son las unidades de coma flotante de 64 bits y su alta precisión lo importante, pero con el tamaño de las GPUs creciendo cada vez más NVIDIA se va a ver obligada a tener que dividir su gama de GPUs Tesla en dos variantes distintas, una para cada uno de los mercados.
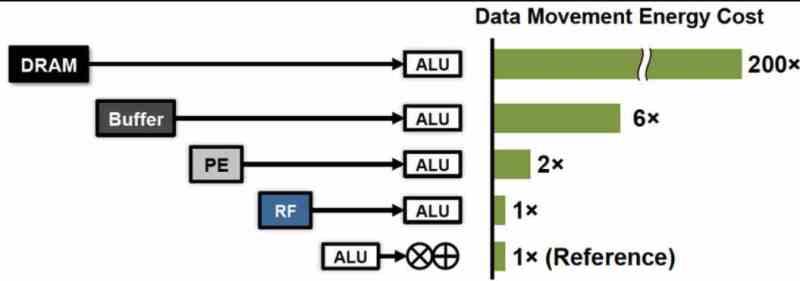
Esta caché sería obviamente de tercer nivel y se situaría cercana al área del controlador de memoria con la VRAM. Lo que significa que NVIDIA va a integrar el mismo concepto que la Infinity Cache de AMD. El concepto tras ello es bien sencillo, cuanto más alejado esta la memoria que contiene un dato de la unidad que lo ha de calcular mayor es el consumo energético de la operación.
Desde la llegada de Bill Dally como científico jefe de NVIDIA, la actual líder en el mercado de las GPUs ha centrado su trabajo en reducir el coste energético a la hora de realizar las diferentes instrucciones de sus GPUs. Lo cual es en estos momentos no una preocupación exclusiva de NVIDIA sino de todo el sector en su carrera para llegar al ExaFLOP.
¿Caché L3 en NVIDIA Lovelace?
El paper que se ha publicado hace referencia a diseños COPA-GPU por parte de NVIDIA, 2.5DIC, los cuales son utilizados exclusivamente para su gama Tesla y no para las GeForce para los PCs Gaming. Por lo que si pensáis que el nuevo nivel de caché lo vais a ver en las futuras RTX 4000 bajo arquitectura Lovelace, iros olvidando.
Los rumores sobre Lovelace hablan de un aumento increíble en la cantidad de SMs en comparación con las actuales GeForce Ampere o RTX 3000. Esto supone un gran aumento del ancho de banda necesario, así como de la necesidad de tener una interfaz de memoria mucho más rápida. El hecho de aumentar los SM supone buscar formas de aumentar el ancho de banda con la memoria sin aumentar el consumo, pero por el momento desconocemos cuál será la solución de NVIDIA.

Podemos caer en la trampa de que el paper de NVIDIA confirma el equivalente a la Infinity Cache de AMD en sus GPU, tendría sentido si tenemos en cuenta que las RX 6800 (XT) y RX 6900 XT hacen uso de una interfaz de 256 bits cuando lo normal en una GPU de su calibre sería una interfaz de 384 bits.
No obstante NVIDIA centra su paper de sus COPA-GPU a mercados distintos al del gaming para PC, por lo que sea como sea Lovelace aún tendremos que esperar hasta bien entrado el 2022 para conocer los detalles intrínsecos de su arquitectura.