
Una de las confusiones creadas por el marketing de los fabricantes de tarjetas gráficas es a la hora de hablar de la cantidad de núcleos que tiene una GPU, os adelantamos que mienten para exagerar los números. ¿Pero qué entendemos por núcleo en una GPU, podemos compararlos con los de una CPU y que diferencias hay?
Cuando vas a comprar la tarjeta gráfica último modelo lo primero que ves es que te hablan de cantidades ingentes de núcleos o de procesadores, pero, ¿qué ocurre si te decimos que es una nomenclatura errónea?
La trampa que hacen los fabricantes es llamar a simples ALUs o unidades de ejecución bajo el nombre de núcleos, por ejemplo NVIDIA llama núcleos CUDA a sus ALUs que operan en coma flotante de 32 bits, pero si somos estrictos no podemos llamarlos núcleos ni procesadores ya que no cumplen con los requisitos básicos para ser considerados de tal manera.
¿Entonces qué es un núcleo o procesador en una GPU?
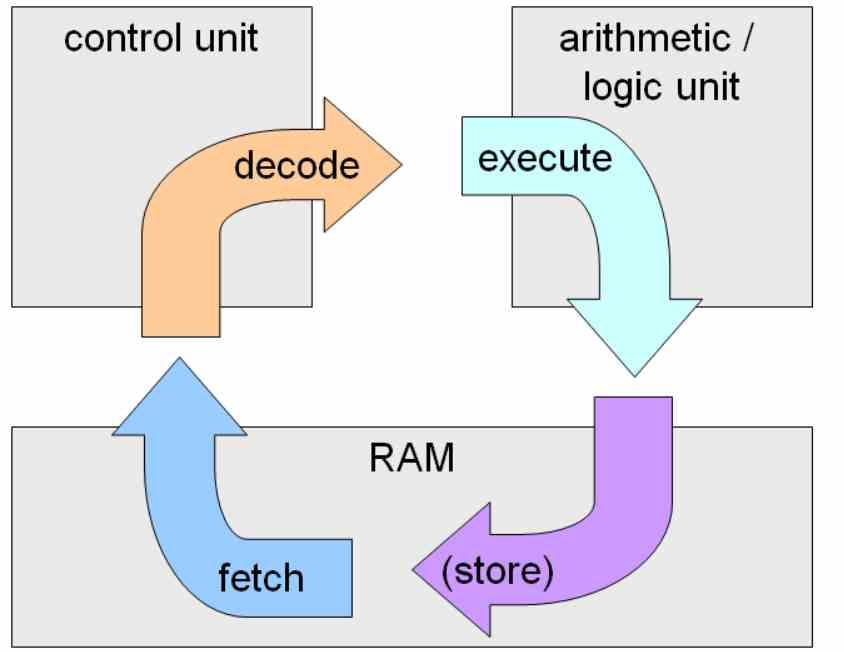
Un núcleo o procesador es todo circuito integrado o parte del mismo que en conjunto puede ejecutar un ciclo de instrucción completo, esto es la captación de instrucciones desde una memoria, la descodificación y la ejecución de las mismas.
Una ALU solo es una unidad de ejecución por lo que necesita una unidad de control para ser un núcleo completo. ¿Y que consideremos un núcleo completo? Pues lo que NVIDIA llama SM, Intel llama Sub-Slice y AMD Compute Unit.
El motivo de ello es que es en estas unidades donde se produce el ciclo de instrucción al completo, y no en las ALUs o unidades de ejecución, las cuales solo se encargan de una parte del ciclo de instrucción.
Las GPUs no “ejecutan” programas

Hay que tener en cuenta que las GPUs no ejecutan programas tal y como los conocemos, siendo estos una secuencia de instrucciones. La excepción son los programas shader que se ejecutan en lo que son realmente los núcleos de la GPU.
Los programas shader lo que hacen es manipular conjuntos de datos o primitivas gráficas en las diferentes etapas. Pero a nivel de funcionalidad del hardware estos se presentan en forma de kernels.
Los kernels, no confundir con los de los sistemas operativos, son conjuntos de un dato+una instrucción autocontenidos, los cuales son también llamados hilos de ejecución en el contexto de una GPU.
¿En que se diferencia el núcleo de una GPU del de una CPU?

La diferencia principal es que las CPUs están sobretodo diseñadas para el paralelismo a nivel de instrucción, mientras que las GPUs están especializadas en el paralelismo a nivel de hilo.
El paralelismo a nivel de instrucción lo que busca es reducir el tiempo de instrucción de un programa a base de que se ejecuten varias instrucciones del mismo de manera simultánea. Los núcleos basados en el paralelismo a nivel de hilo cogen varios programas al mismo tiempo y los ejecutan en paralelo,
Las CPUs contemporáneas combinan ILP y TLP en sus arquitecturas mientras que las GPUs siguen siendo puramente TLP sin ningún tipo de ILP con tal de simplificar la unidad de control y poder colocar la mayor cantidad de núcleos posibles.
Ejecución en una GPU versus ejecución en una CPU
La mayoría de veces, cuando un hilo llega a las ALUs del núcleo de la GPU contiene la instrucción y el dato de manera directa, pero hay momentos en que el dato se ha de buscar en las caches y en memoria, para evitar retrasos en la ejecución el planificador del núcleo de la GPU lo que hace es lo que se llama un Round-Robin y pasa ese hilo a ejecutar a posteriori.
En una CPU esto no se puede hacer, el motivo de ello es que los hilos son conjuntos de instrucciones muy complejos y con una alta dependencia entre ellos, mientras que en una GPU no hay problema para ello, dado que los hilos de ejecución son extremadamente pequeños al estar autocontenidos en «kernels» muchas veces de una sola instrucción de duración.
En realidad las GPUs lo que hacen es reunir un conjunto de kernels en lo que se llama ola, asignando cada ola a una ALU de la GPU, estas se ejecutan en cascada y en orden. Cada núcleo tiene un limite de hilos o kernels, los cuales lo mantendrán ocupado un tiempo hasta que necesite una nueva lista, de esta manera se evitar que la ingente cantidad de núcleos este todo el rato haciendo peticiones a memoria.