
La Infinity Cache es la diferencia más notable entre las tarjetas gráficas de la serie RX 6000 que se han presentado recientemente (RX 6800, RX 6800 XT y RX 6900) con la GPU del SoC de Xbox Series X, basada también en RDNA 2. ¿Pero qué es exactamente la Infinity Cache, cuál es su utilidad y cómo funciona? Os vamos a desgranar todos sus secretos.
Desde las semanas previas a la presentación de las RX 6000 hemos sabido de la existencia de este enorme pozo de memoria dentro de la GPU, enorme porque estamos hablando de la cache más grande en la historia de las GPUs con unos 128 MB de capacidad. Pero AMD no ha dado muchos datos sobre la misma, simplemente nos ha hablado de su existencia.
Es por ello que se hace necesaria una explicación detallada para entender el motivo por el cual AMD ha colocado una cache de semejante tamaño en la versión de su RDNA 2 para PC.
Localizando a la Infinity Cache

El primer punto que es necesario para entender cuál es la función de una pieza dentro del hardware es deducir su función a partir de la localización de la misma dentro del sistema.
Dado que RDNA 2 es una evolución de RDNA, antes de nada, tenemos que hacer una ojeada a la primera generación de la actual arquitectura gráfica de AMD, de la cual conocemos dos chips que son Navi 10 y Navi 14.
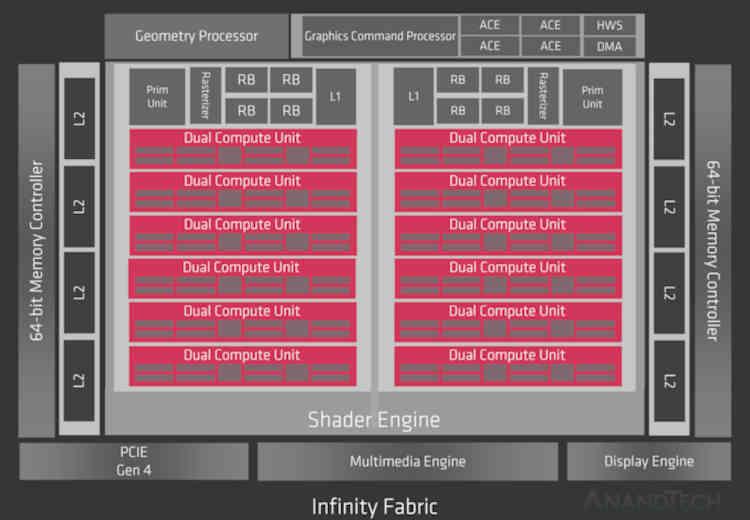
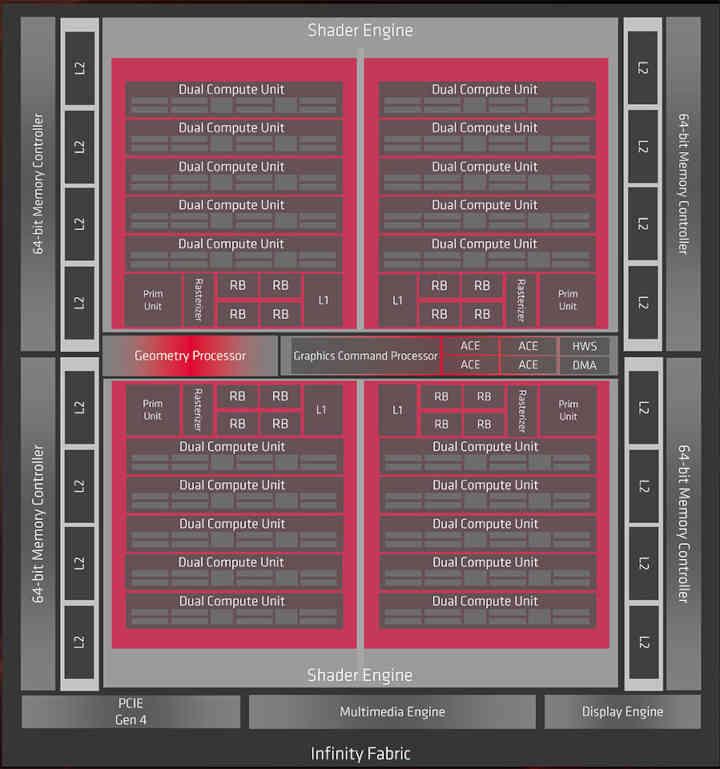
Pues bien, si se hubiese implementado la Infinity Cache en RDNA, esta se encontraría en la parte que dice Infinity Fabric del diagrama, por lo que a nivel de organización de la caché pasaríamos de esto: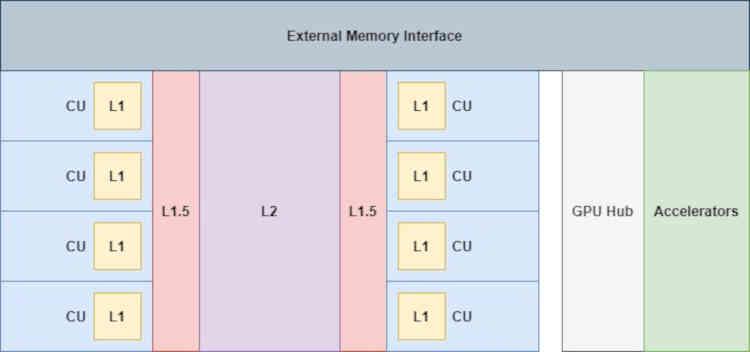
Donde los aceleradores conectados al GPU Hub ( el códec de vídeo, el controlador de pantalla, las unidades DMA, etc) no tienen ningún acceso directo con las cachés, ni tan siquiera con la caché L2.
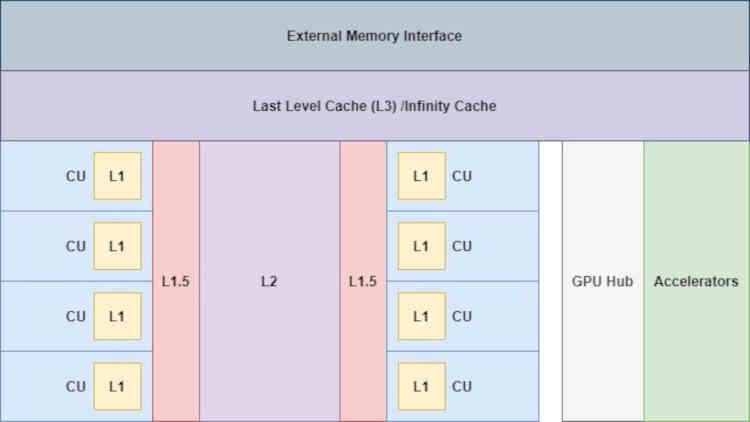
Con el añadido de la Infinity Cache la cosa ya cambia «un poco», ya que ahora los aceleradores tienen acceso a dicha memoria,
Esto es muy importante, especialmente de cara al Display Core Next que se encarga de leer el búfer de imagen final y transmitirlo hacía la interfaz Display Port o HDMI correspondiente para que se muestre la imagen en pantalla, esto es importante de cara a reducir los accesos a la VRAM por parte de estas unidades.
Recordando el sistema de cachés de RDNA

En RDNA las cachés se encuentran conectadas entre ellas de la siguiente manera:

La cache L2 esta conectada de cara al exterior a 16 canales de 32 Bytes/ciclo cada uno, si miramos el diagrama de Navi 10 entonces veréis como esta GPU tiene unas 16 particiones de Caché L2 y un bus de 256 bits GDDR6 a la que están conectadas.
Hay que tener en cuenta que la GDDR6 utiliza 2 canales por chip que operan en paralelo, cada uno de 16 bits.
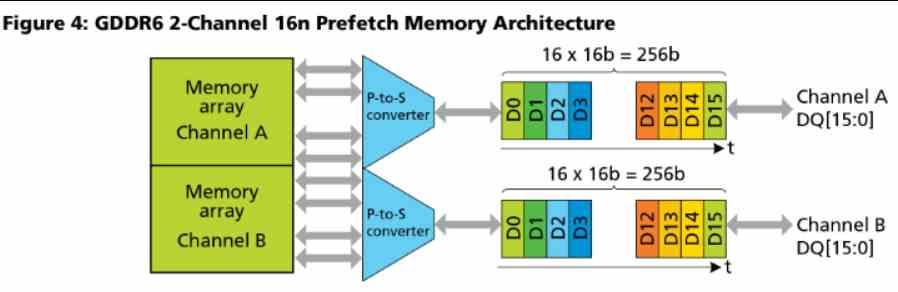
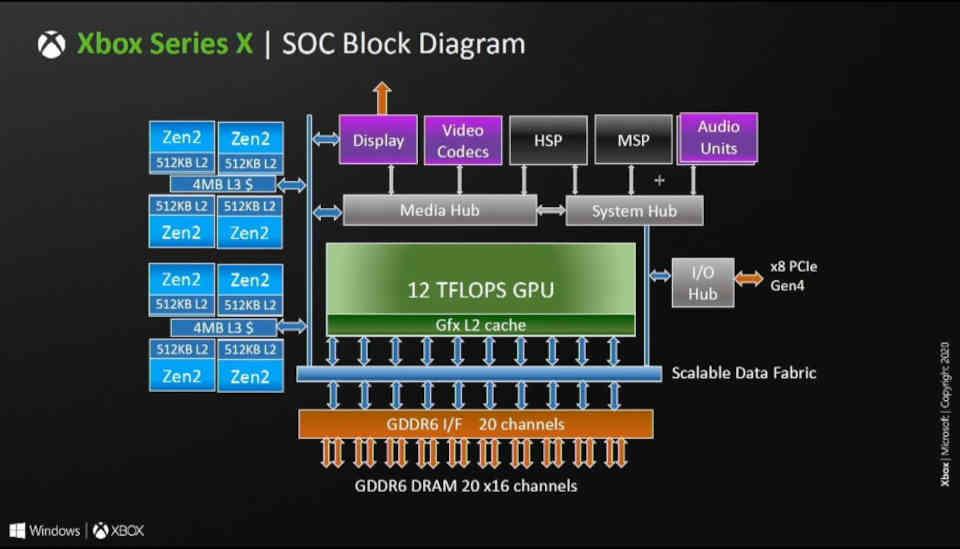
Es decir, la cantidad de particiones de caché L2 en las arquitecturas RDNA equivale a la cantidad de canales GDDR6 de 16 bits que hay conectados al procesador gráfico. En RDNA y RDNA 2 cada partición es de 256 KB, este es el motivo por el cual la Xbox Series X que dispone de un bus de 320 bits y por tanto 20 canales GDDR6 tiene unos 5 MB de Caché L2.
Un nuevo nivel de caché: la Infinity Cache

Dado que es un nivel adicional de caché, la Infinity Cache tiene que estar conectada a la caché L2 de manera directa, el cual es el nivel anterior en la jerarquía de caches, esto nos es confirmado por la propia AMD en un pie de página:
Medición calculada por los ingenieros de AMD, en una tarjeta de la serie Radeon RX 6000 con AMD Infinity Cache de 128 MB y GDDR6 de 256 bits. Midiendo las tasas de éxito promedio de AMD Infinity Cache en juegos 4k del 58% en los principales títulos de juegos, multiplicado por el ancho de banda máximo teórico de los 16 canales AMD Infinity Fabric de 64B que conectan la caché al motor de gráficos a una frecuencia de impulso de hasta 1.94 GHz.
La GPU utilizada en RX 6800, RX 6800 XT y RX 6900 es Navi 21 que tiene un bus de 256 bits GDDR6, ergo tiene 16 canales y de ahí las 16 particiones de Caché L2 estando cada una conectada a una partición de la Infinity Cache.
En cuanto al tema de los «hit rates» de un 58% es más complicado y es lo que intentaremos explicar a continuación.
Tile Caching en las GPUs de NVIDIA

Antes de continuar con la Infinity Cache hemos de entender los motivos de su existencia y para ello nos tenemos que fijar cómo han evolucionado las GPUs en los últimos años.
A partir de las NVIDIA Maxwell, Serie 900 de las GeForce, en NVIDIA realizaron un cambio importante en sus GPUs que bautizaron como Tile Caching, cuyo cambio supuso conectar los ROPS y la unidad de rasterizado a la caché L2.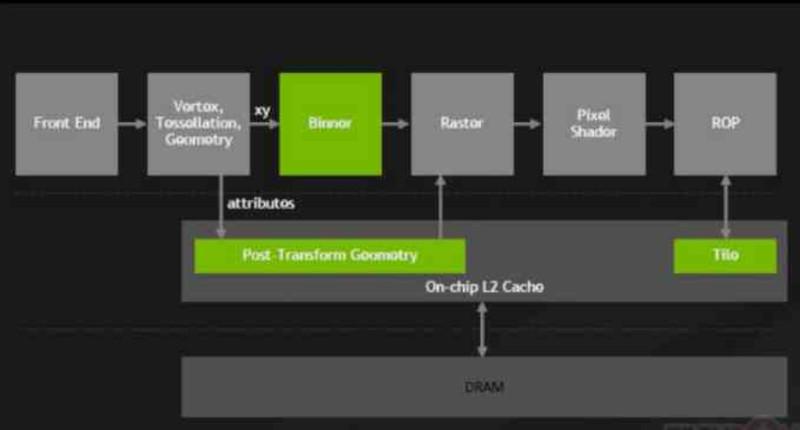
Con este cambio los ROPS dejaban de escribir a la VRAM de manera directa, los ROPS son comunes en todas las GPUs y se encargan de crear los búferes de imagen en memoria.
Gracias a este cambio, NVIDIA consiguió reducir el impacto energético sobre el bus de memoria reduciendo la cantidad de transferencias que se hacían desde y hacia la VRAM y con ello NVIDIA consiguieron ganar en eficiencia energética a AMD con las arquitecturas Maxwell y Pascal.
DSBR, el Tile Caching en las GPUs de AMD
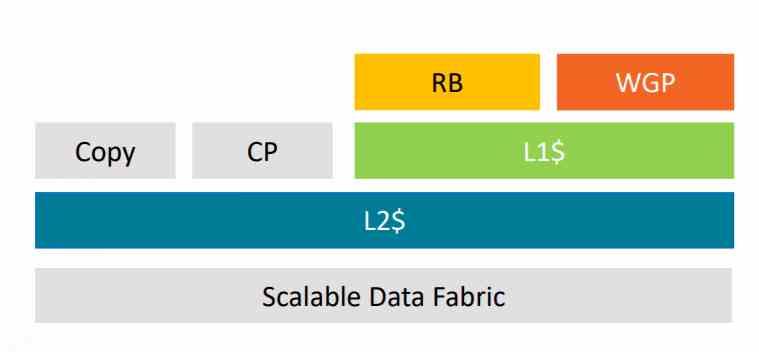
AMD en cambio durante todas las generaciones de la arquitectura GCN previas a Vega conectaba los Render Backends (RB) de manera directa al controlador de memoria.

Pero a partir de la AMD Vega hizo dos cambios en la arquitectura para añadir el Tile Caching a sus GPUs, el primero de ellos fue renovar la unidad de rasterizado, a la cual renombro como DSBR, Draw Stream Binning Rasterizer.

El segundo cambio fue que conectaron la unidad de rasterizado y los ROPS a la caché L2, cambio que perdura todavía en RDNA y RDNA 2.
La utilidad del DSBR o Tile Caching
El Tile Caching o DSBR es eficiente por el hecho que ordena la geometría de la escena según su posición en pantalla antes de que esta sea rasterizada, esto fue un cambio importante ya que las GPUs antes de la implementación de esta técnica ordenaban los fragmentos ya texturizados justo antes de enviarlos al búfer de imagen.
En el Tile Caching/DSBR lo que se hace es ordenar los polígonos de la escena antes de que sean convertidos en fragmentos por la unidad de rasterizado.
En el Tile Caching, los polígonos son ordenados según su posición de pantalla en tiles, donde cada tile es un fragmento de n*n píxeles.
Una de las ventajas que tiene esto, es que permite eliminar de antemano los píxeles no visibles de los fragmentos que se ven opacados al encontrarse en la misma situación. Algo que no se puede realizar si los elementos que componen la escena se ordenan después del texturizado.
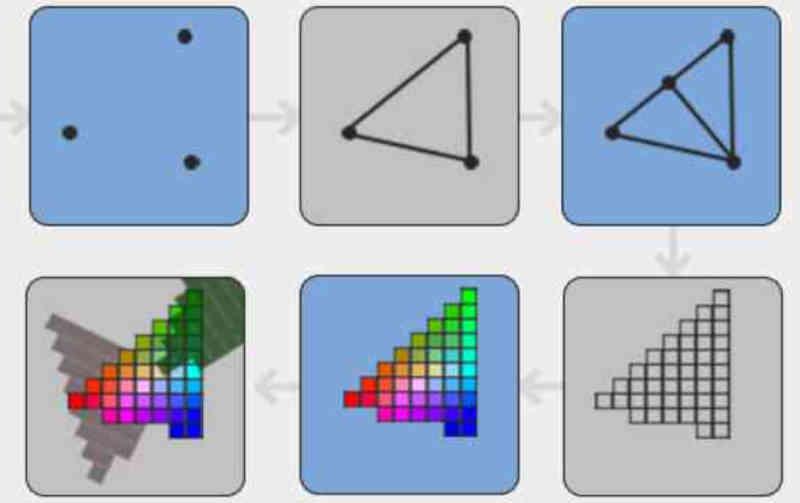
Esto hace que la GPU no pierda el tiempo en píxeles superfluos y mejora la eficiencia de la GPU. En el caso de que os parezca esto confuso, es tan simple como recordar que durante todo el pipeline gráfico las diferentes primitivas que componen la escena toman diferentes formas durante las diferentes etapas del mismo.
El Tile Caching o DSBR no equivale a Tile Rendering
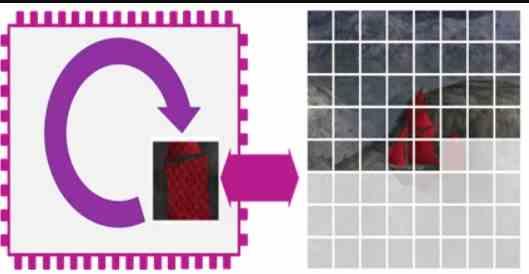
Pese a que el nombre puede dar a confusiones, el Tile Caching no equivale a Tile Rendering por los siguientes motivos:
- Los Tile renderers almacenan la geometría de la escena en memoria, la ordenan y crean listas de pantalla por cada tile. Este proceso no ocurre en el caso del Tile Caching o DSBR.
- En el Tile Rendering los ROPS están conectados a memorias scratchpad fuera de la jerarquía de cachés y no vacían su contenido en la VRAM hasta que ese tile ha sido terminado al 100%, por lo que los «hit rates» son del 100%
- En el Tile Caching/DSBR al estar los ROPS/RB conectados a la Caché L2, en cualquier momento puede producirse un descarte de la lineas de caché de la L2 a la RAM, por lo que no existe la seguridad de que el 100% de los datos se encuentren en la caché L2.
Dado que existe una alta probabilidad de las líneas de caché terminen en la VRAM, lo que ha hecho AMD con la Infinity Cache es añadir un nivel de caché adicional que recoja los datos descartados de la caché L2 de la GPU.
La Infinity Cache es una Victim Cache
La idea de la Victim Caché es una herencia de las CPUs bajo arquitecturas Zen que ha sido adaptada a RDNA 2.
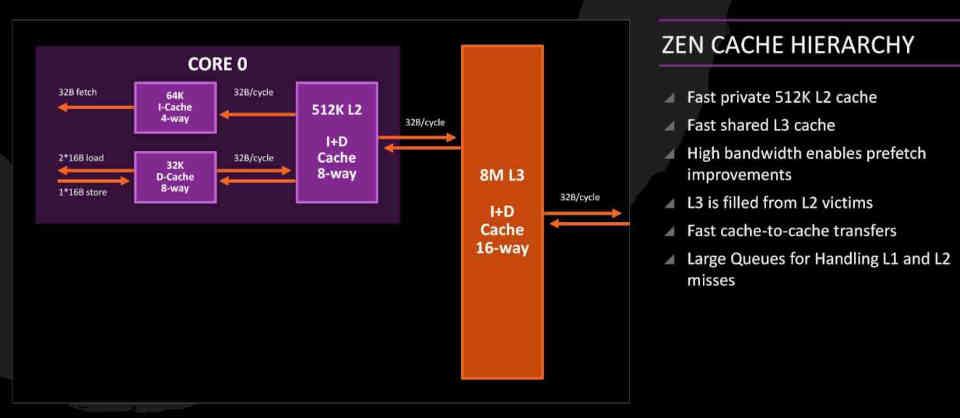

En los núcleos Zen la Caché L3 es lo que llamamos una Victim Caché, estas se encargan de recoger las lineas de caché descartadas desde la L2 en vez de encargarse de formar parte de la jerarquía de cachés habitual. Es decir, en los núcleos Zen los datos que vienen desde la RAM no hacen el camino RAM → L3 → L2 → L1 o viceversa, sino que hacen el camino RAM → L2 → L1 ya que la caché L3 hace de Victim Caché.
En el caso de la Infinity Cache, la idea es rescatar las lineas de la Caché L2 de la GPU sin tener que acceder a la VRAM, lo que permite que la energía consumida por instrucción sea mucho menor y por tanto se pueden alcanzar mayores velocidades de reloj.
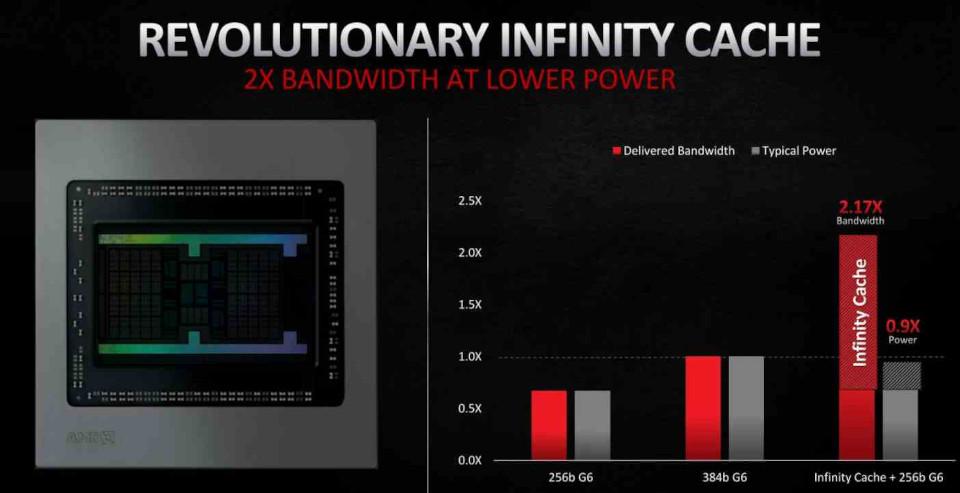
No obstante, pese a que la capacidad de 128 MB pueda parecer muy alta, no parece suficiente para evitar que todas las lineas descartadas terminen en la VRAM, ya que en el mejor de los casos solo consigue rescatar un 58%. Esto significa que en futuras iteraciones de su arquitectura RDNA es muy probable que AMD aumente la capacidad de esta Infinity Cache.