
Ha aparecido publicado un paper de NVIDIA donde se explica un cambio a nivel de hardware que veremos a partir de las RTX 40 con arquitectura Ada Lovelace. Se trata de una importante mejora bajo el nombre de Subwarp Interleaving. ¿En qué consiste y qué cambios en rendimiento y arquitectura supone para las GPU?
Uno de los problemas más comunes de todo procesador es la latencia a la hora de ejecutar las instrucciones, ya que tradicionalmente las GPU han utilizado métodos para ocultar este problema que podrían haberse quedado desfasadas y de ahí el desarrollo del llamado Subwarp Interleaving. Pero, ¿en qué consiste?
¿Cómo ejecuta instrucciones una GPU?

Hemos de partir de la base que pese a que una GPU también ejecuta programas su comportamiento es diferente al de una CPU. Es por ello que hemos de tener en cuenta que el concepto de hilo de ejecución es diferente. Mientras que en una CPU cada hilo es una larga lista de instrucciones sucesivas, en el caso de un procesador gráfico esta puede ser tan corta como una sola instrucción y su dato correspondiente, pero para que lo entendáis mucho mejor y de manera clara y meridiana os vamos a dar un símil con la vida real.
Supongamos que cada hilo de ejecución en la GPU es un espectador que entra en el cine con una entrada para ver una película en concreto. Se trata de un establecimiento con una sola sala, pero que proyecta diferentes películas al día donde cada una de ellas representa una instrucción con una duración en ciclos de reloj concreta. Lo que hace el planificador de la GPU es sentar a los hilos en sus butacas, que serían los registros, para resolverlos, es decir, organiza y dispone el trabajo del hilo de ejecución. Mientras tanto en la sala de espera están los espectadores de la siguiente película/instrucción esperando a ejecutarse.
¿Qué ocurre si el técnico de proyección no puede mostrar la película o un espectador llega tarde? Dado que el tiempo de proyección es limitado lo que se hace es enviar ese grupo de hilos de nuevo a la cola. Por lo que se trata de un tipo de arquitectura preparada para realizar cálculos con enormes cantidades de datos en paralelo, ya sean píxeles, vértices o cualquier otra primitiva gráfica.
El concepto de Warp
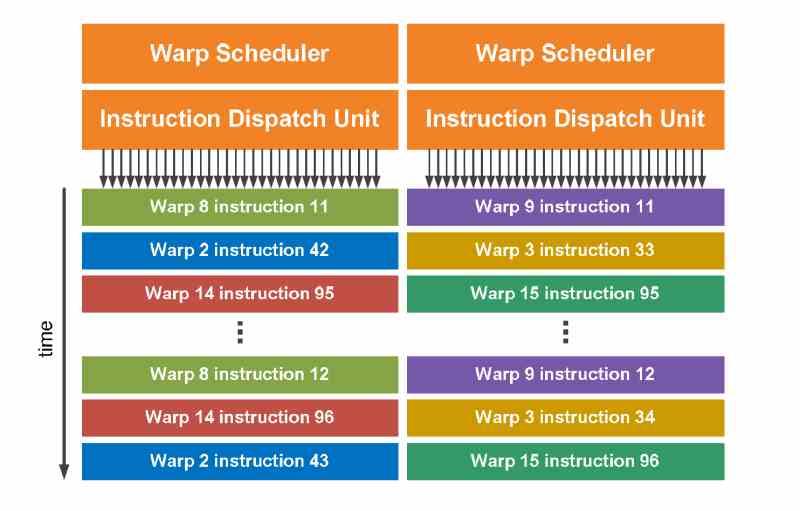
Las GPU de NVIDIA agrupan los hilos de ejecución en bloques llamados Warp, los cuales pueden ser de cualquier tamaño, pero que de manera estándar suelen ser de 32 hilos de ejecución cada uno. Estos se almacenan en los registros del subcore y se ejecutan en cascada donde cada grupo de los espectadores que hemos explicado en la sección anterior entran en grupo, siendo estos un Warp.
Se ha de tener en cuenta que cada subcore puede almacenar en sus registros varios warp para una futura ejecución de los mismos dado que estos son distribuidos por el procesador de comandos de la GPU dividiendo los Threadgroups, los cuales pueden ser de hasta 1024 hilos de ejecución, límite marcado por DirectX.
¿Qué es el subwarp interleaving?
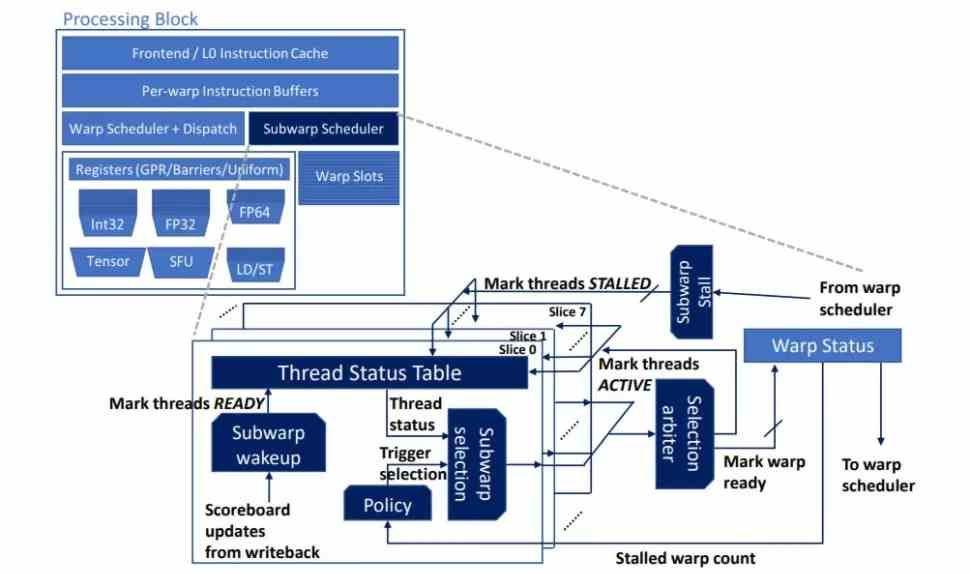
A través de un paper publicado por la propia NVIDIA hemos podido saber de una mejora sobre sus futuras arquitecturas que supondrá un cambio en el planificador incluido en cada uno de los subcore dentro del SM o unidades shader de cada una de sus GPU, pero que integra un concepto con más de una década que tenemos en los núcleos de CPU, el multihilo. Lo cual a muchos os confundirá, por lo tanto, es importante tener en cuenta que a nivel de hardware estamos ante dos conceptos distintos.
En una CPU el multihilo se consigue duplicando la unidad de control de cada uno de sus núcleos, donde la segunda unidad de este tipo aparece cuando se da una parada o burbuja, la cual surge cuando por latencia con la memoria la resolución de una instrucción tarda demasiado en llegar. En las GPU esto no se da por el hecho de que estas utilizan el algoritmo Round-Robin, que consiste en enviar a la cola los hilos de ejecución no resueltos y tomar el siguiente. Por eso se dice que los chips gráficos son menos dependientes de la latencia que las CPU.
Pues bien, el subwarp interleaving se basa en colocar un doble planificador donde el segundo se active cuando exista una parada o burbuja en la GPU para tomar el otro conjunto de Warp almacenados en los registros. Lo que supone no solo duplicar el planificador, sino también los propios registros de cada subcore. Todo ello para obtener un rendimiento adicional entre el 6,3% y el 20% según cuál sea la situación, al menos eso afirma NVIDIA.
¿Qué problema busca solucionar?
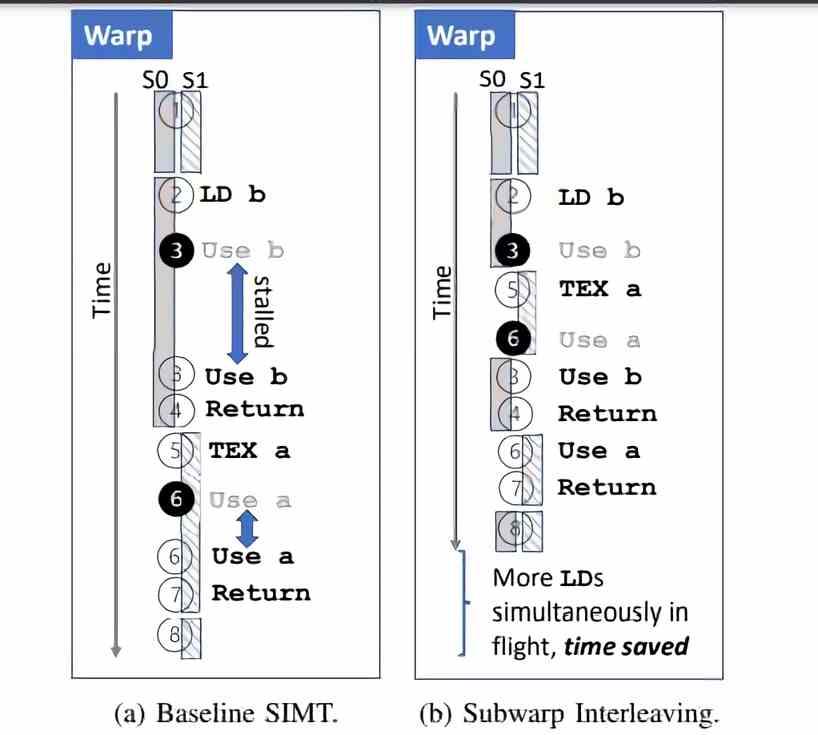
El cambio en el subwarp interleaving no es otro que poder tener 2 Warp ejecutándose simultáneamente en cada subcore del SM de cada GPU y cada uno son su propio contador de programa, el cual es otro elemento de la unidad de control. Si tomamos cualquier arquitectura gráfica actual que tiene que ejecutar dos Warp distintos veremos que estos los ejecutará en serie y, por tanto, uno detrás de otro (ejemplo de la izquierda en la imagen superior). En cambip, con el nuevo método (parte derecha de la imagen) lo que ocurrirá es que si hay una parada en el primer Warp entonces cambiará al segundo de manera inmediata para acelerar la ejecución del mismo. Por eso el nombre es subwarp intercalado.
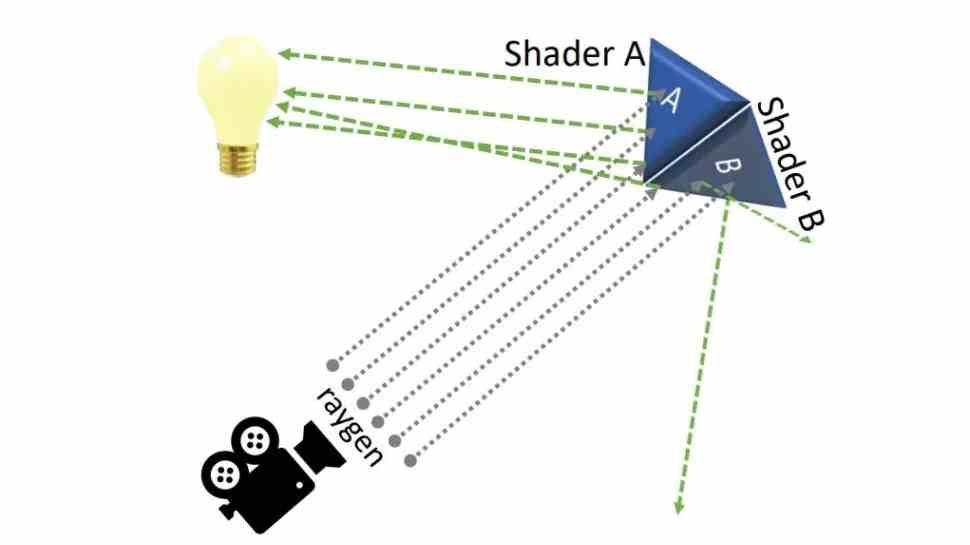
Esto tiene una utilidad concreta de cara al Ray Tracing, pero para ello hemos de entender que una vez el RT Core ha dado la solución sobre si el rayo colisiona o no con el objeto se activa un shader según la condición Booleana que retorna. Por lo que en una misma superficie se pueden ejecutar dos shaders distintos al mismo tiempo, los cuales se ejecutarían por separado, pero con el subwarp interleaving al intercalarse ocurre en menos ciclos de reloj y, por tanto, supone un aumento del IPC en este aspecto.
Mejoras no especificadas en el paper
Una de las cosas que no quedan claras, pero que nos preguntamos, es si las unidades que se encuentran inactivas se podrán beneficiar del subwarp interleaving. En especial los Tensor Cores, los cuales pese a su gran velocidad se encuentran buena parte del tiempo inactivos por compartir los registros y el planificador con el resto del subcore del SM. Es posible que veamos nuevos algoritmos al estilo DLSS que funcionen en paralelo con la ejecución SIMT convencional de las GPU en vez de hacerlo de forma conmutada como hasta ahora.
Subwarp Interleaving para RTX 40

Dado que este cambio es a nivel de hardware no se puede aplicar a las GPU de NVIDIA de las familias inferiores a la RTX 40 a nivel de driver, por lo que vamos a ver el subwarp interleaving siendo implementado en la arquitectura Lovelace, siendo el primer cambio importante que conocemos que tienen respecto a generaciones anteriores.
En todo caso resulta curioso ver implementado un concepto que lleva más de diez años en las CPU de Intel y AMD, pero a nivel de GPU, lo cual también nos hace pensar que los sistemas de ocultación de la latencia típicos en este tipo de procesadores se están quedando atrás. No olvidemos que el precio a pagar a cambio de tener más ancho de banda con las nuevas VRAM es siempre el aumento de la latencia.