
La arquitectura Von Neumann es la arquitectura común de todos los procesadores para PC. Todas y cada una de las CPU, desde ARM a x86, desde el mítico 8086 a los AMD Ryzen pasando por los Pentium y los Intel Core. Todas ellas son arquitecturas Von Neumann y todas ellas heredan los mismos principios de organización. Veamos, por tanto, en qué consiste y el secreto de que se hayan mantenido vigente durante tantas décadas.
John Von Neumann fue un matemático de origen húngaro que es famoso por dos cosas: la primera fue por haber trabajado en el Proyecto Manhattan, donde se desarrollaron las bombas atómicas que los Estados Unidos lanzaron contra Japón a finales de la Segunda Guerra Mundial. La segunda fue por ser el responsable del desarrollo de la arquitectura base que hoy en día utilizan nuestros PC, sean del tamaño que sean, desde móviles a grandes superordenadores, así como también la forma en la que los programas que estos ejecutan.
Por lo que su impacto en nuestra vida ha sido brutal, porque gracias a su trabajo existe todo lo que tenemos a nuestro alrededor. No ya la revolución informática de los años 70 y 80, sino también la de internet a mediados de los 90 y la actual que tiene a la inteligencia artifical en el centro del foco. Todo, absolutamente todo lo que nos rodea actualmente está construido en base a los principios que marcó John Von Neumann el siglo pasado.
¿Qué es la arquitectura Von Neumann?
La arquitectura Von Neumann es una de las dos arquitecturas generales en la que se basan los ordenadores y es la más utilizada en PC, consolas, tabletas y teléfonos móviles a día de hoy, dado que todos ellos se encuentran organizados entre ellos usando una serie de tipos de componentes en común.
El símil más claro para entenderlo es el de un coche: no todos los coches son iguales, pero todos ellos comparten una serie de elementos con una función e interacción específica, creando un sistema más complejo que es el coche. Dicho de otra manera, todos los coches tienen cuatro ruedas, un chasis, asientos, volante, frenos, acelerador, etc., sean de la marca que sean y tengan el precio que tengan. Un 600 y un Ferrari comparten estos mismos denominadores comunes.
De la misma manera, un ser vivo es un conjunto de células diferenciadas que de forma combinada crean un individuo. Pues bien, en este caso hablamos de una de las dos organizaciones más comunes para montar un sistema informático, la otra es la llamada Harvard, pero en PC, consolas y dispositivos móviles es la arquitectura Von Neumann la que más se utiliza.
Cómo se organiza un ordenador Von Neumann
Sea cual sea el ordenador que usas, sea este una consola de videojuegos, un PC completo, un teléfono móvil o incluso una Smart TV, todas ellas tienen su hardware organizado de la siguiente manera, como te indicamos en el gráfico que tienes justo aquí debajo:
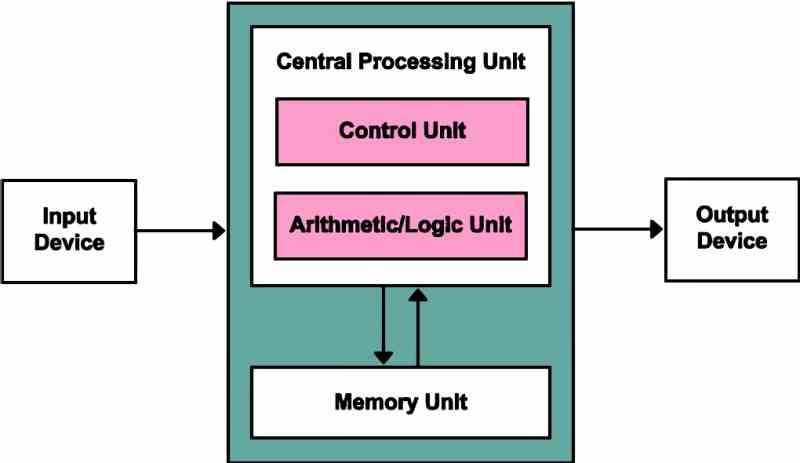
De forma muy resumida, el trabajo de cada una de las partes del diagrama es la siguiente:
- Unidad de Control: Encargada de las etapas de captación y descodificación del ciclo de instrucción.
- Unidad lógico-aritmética o ALU: Encargada de realizar las operaciones matemáticas y de lógica que requieren los programas.
- Memoria: La memoria en la que se almacena el programa, la cual la conocemos como memoria RAM
- Dispositivo de entrada: Desde el que nos comunicamos con el ordenador.
- Dispositivo de Salida: Desde el que el ordenador se comunica con nosotros.
Como podéis ver se trata de la arquitectura común en todos los procesadores y todos los elementos descritos arriba los encontraréis que cualquier chip con la capacidad de procesar datos e instrucciones en forma de un programa ordenado. Sean estos una CPU, una GPU o cualquier otro procesador, ya sea principal o de apoyo, la arquitectura Von Neumann es un denominador común.
Arquitectura Harvard
Existe otro tipo de arquitectura conocida como arquitectura Harvard en la que la memoria RAM se encuentra dividida en dos pozos distintos. En uno de ellos se almacenan las instrucciones del programa y en la otra memoria los datos, teniendo buses separados tanto para el direccionamiento de la memoria como para las instrucciones.
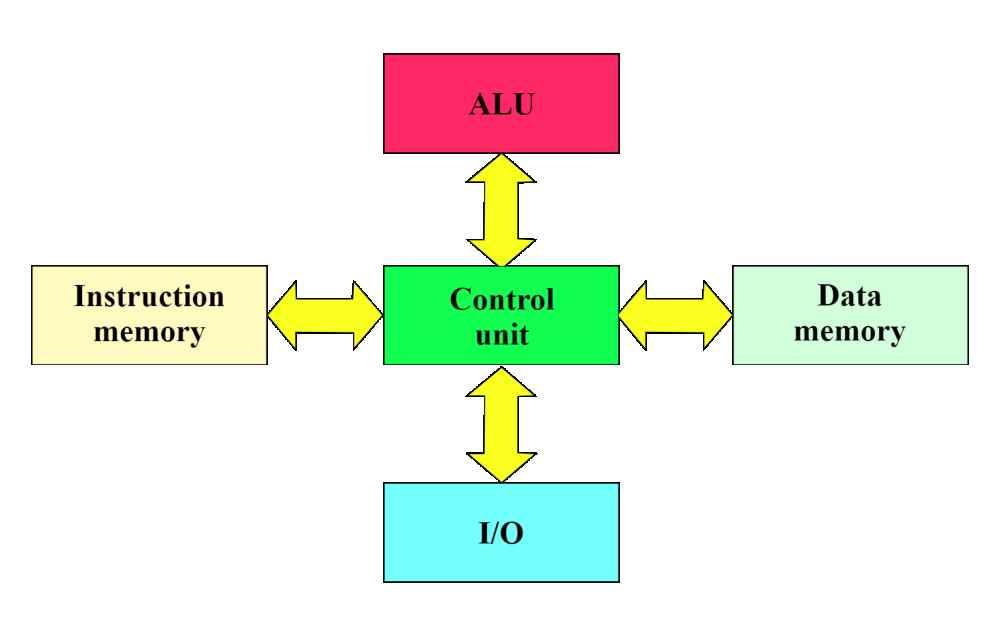
Esta suele ser común entre microcontroladores y no en procesadores para ordenador, sin embargo, tal y como contaremos después, a nivel interno y en el caso de las cachés privadas de niveles más bajos y cercanos a los núcleos, estas usan una estructura Harvard con tal de reducir la latencia al máximo.
Podríamos decir que la arquitectura Harvard tiene una separación en la memoria para poder tener los datos más ordenados, y podríamos pensar que al ser así el rendimiento será mejor, ¿no? Pues no, realmente no. Pensad que simplemente es otra manera de gestionar, ni más ni menos, pero vamos a verlo con mayor detalle en el siguiente apartado, ya que existen limitaciones.
Limitaciones de la arquitectura Von Neumann
La principal desventaja de la arquitectura Von Neumann respecto a las Harvard es que utiliza un pozo de RAM único en el que almacenan instrucciones y datos. Por lo que compran un mismo bus de datos y direccionamiento. Por lo que las instrucciones y los datos han de ser captados de manera secuencial desde la memoria al mismo tiempo. Este es el llamado cuello de botella de Von Neumann. Es por ello que los diferentes microprocesadores tienen la caché más cercana al procesador, dividida en dos tipos, una para datos y otra para instrucciones. Así que, como veis, tampoco es una solución perfecta, pero sí la que más se acerca.
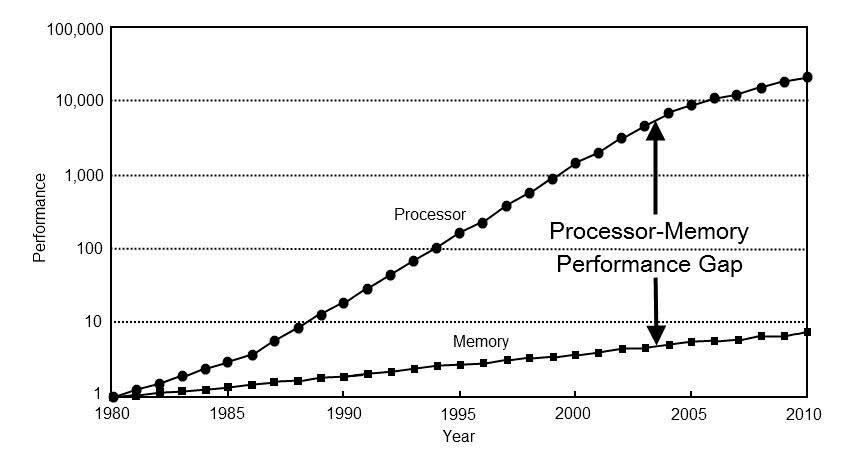
En los años recientes, las velocidades de los procesadores ha ido aumentando de manera mucho más rápida que la memoria RAM, por lo que se ha aumentado el tiempo en que los datos tardan en ser comunicados desde hacia la memoria. Lo que ha obligado a desarrollar soluciones para paliar este problema, producto del cuello de botella de Von Neumann.
En los procesadores donde normalmente se utiliza la arquitectura Harvard es en los que estos se encuentran autocontenidos y, por tanto, no tienen acceso a la memoria RAM en común del sistema, sino que ejecutan su propia memoria y programa de manera aislada a la CPU principal. Estos procesadores reciben la lista de datos e instrucciones en dos ramales de datos distintos. Uno para la memoria de instrucciones y el otro para la memoria de datos de dicho procesador.
¿Por qué es la empleada en CPU y GPU?
El motivo principal es el hecho que aumentar la cantidad de buses significa aumentar el perímetro del propio procesador, ya que para comunicarse con la memoria externa es necesario que la interfaz se encuentre en la parte exterior del mismo. Esto lleva a procesadores mucho más grandes y mucho más caros. Por lo que el principal motivo por el cual la arquitectura Von Neumann se ha estandarizado es por los costes.

El segundo motivo es que se necesita que los dos pozos de memoria estén sincronizados para que un una instrucción no se aplique a un dato erróneo. Lo que lleva a tener que crear sistemas de coordinación entre ambos pozos de memoria. Eso sí, buena parte de los cuellos de botella se eliminarían al separar ambos buses. Pero tampoco reduciría del todo el cuello de botella de Von Neumann.
Esto se debe a que el cuello de botella de Von Neumann, pese a ser una consecuencia del almacenamiento de datos e instrucciones en una misma memoria, también se puede dar en una arquitectura Harvard si esta no es lo suficientemente rápida como para alimentar al procesador. Es por ello que las arquitecturas Harvard se ha reducido en especial a microcontroladores y DSP. Mientras que Von Neumann es común en CPU y GPU
La caché de primer nivel, el escenario en el que se rompe el modelo
Habréis observado que tanto en CPU como en GPU, la caché de nivel más bajo está siempre dividida en instrucciones y datos, lo cual rompe la definición de arquitectura de lo que es una arquitectura Von Neumann. El motivo de hacer esto es muy simple y es que esto tiene que ver con el objetivo de facilitar la descodificación de las instrucciones, por lo que habitualmente cuando se copia de la caché del segundo nivel más bajo al más alto lo que se hace es separar el dato de la instrucción.

Esto lo podemos ver en todo tipo de procesadores, por lo que es igual que estemos hablando de una CPU o una GPU (al fin y al cabo una GPU sigue siendo un procesador, solo que orientado a gráficos), dado que esto ocurre en cualquier procesador que, por tanto, tenga que ejecutar un programa. Al fin y a cabo, esto sirve para tener una unidad de descodificación de las instrucciones más simple. Ya que recordemos que son los primeros bits de cada una los que interpretados como instrucción.
Además, esto permite la implementación de instrucciones del tipo vectorial o SIMD de manera más sencilla en el procesador. Estas últimas son ampliamente utilizadas para acelerar algoritmos en paralelo. De ahí a que sean las unidades de ejecución que más se encuentran en las GPU.
Todavía le quedan décadas de vida
Ya como resumen y para terminar, entender cómo funciona la arquitectura Von Neumann significa entender cómo funciona casi cualquier sistema informático a excepción de los microcontroladores. Dado que todos se basan en estos principios es como comparar un motor Ferrari con un McLaren: ambos son de marcas distintas, pero se basan en una serie de principios y normas comunes y con el mundo de los procesadores ocurre lo mismo. Así que recordad todo lo que os contamos en este artículo porque será una información clave para entender mejor cómo funciona vuestro PC. ¿Te imaginabas algo así?
En cualquier caso, tal y como te hemos ido diciendo a lo largo de todo este artículo, la arquitectura Von Neumann es tan importante que incluso aunque tenga ya décadas de vida, es la que se sigue utilizando en todos los PC y dispositivos actuales que dependan de un procesador, y tal y como están las cosas hay muchísimas probabilidades de que se siga utilizando… durante décadas. Y sí, como en prácticamente todos los órdenes de la vida, es la economía y el mayor o menor coste de una solución, la que termina marcando su uso masivo y su éxito. Que no su calidad o blindaje ante problemas que tienen una solución a nivel de ingeniería.