
Una de las cosas de las que se habla largo y tendido es del pobre rendimiento de las tarjetas gráficas AMD en el Ray Tracing, en especial en comparación con la de NVIDIA. Sin embargo, muchos se echan las manos a la cabeza cuando decimos que la implementación del hardware necesario por parte del Radeon Technology Group es tan pobre que parece literalmente un boicot a la adopción de esta tecnología. La cual recordemos que es ideal para solventar ciertos problemas visuales en los gráficos por ordenador y tampoco es un invento del fabricante de las GeForce.
Para nosotros la función principal de una tarjeta gráfica es que nos permita jugar a nuestros juegos con soltura y rendimiento, al mismo tiempo que si la vas a necesitar para tareas más profesionales cómo la edición de vídeo o la creación de modelados 3D que cumpla de sobras con su trabajo. Cuando hablamos que AMD tiene poco rendimiento en el Ray Tracing no estamos poniendo por las nubes a NVIDIA, sino que más bien, como usuarios que también somos, nos apena ver que algo que en las Radeon podría ser mucho mejor, no lo es.
El algoritmo del Ray Tracing
Para entender el pobre rendimiento de las tarjetas de AMD en el Ray Tracing hemos de entender que este en realidad es una algoritmo recursivo para generar una escena completa, el cual en su versión más simple se puede resumir de la siguiente manera:
- Por cada píxel en la escena
- Calcula el rayo de visualización
- Si el rayo impacta sobre un objeto, evalúa el color del objeto.
- En caso negativo, ese píxel tiene el color de fondo.
- Calcula el rayo de visualización
El rayo no es más que un vector que se mueve desde la cámara que «graba» la escena y que atraviese una matriz de puntos o una malla, donde cada uno de ellos es un píxel. Cada vez se va a realizar un efecto de comprobación sobre la escena. Pues bien, si tenemos una escena con resolución FullHD esto significa que se tendrán que realizar 2 millones de comprobaciones, si el juego va a 60 FPS esto son 120 millones de comprobaciones por segundo.
Matemáticamente, la fórmula más común para comprobarla no es una simple operación, sino que se trata de una ecuación compleja con vectores, la cual requiere cierta potencia. Tanto es así que el simple hecho de no tener una unidad en paralelo encargada de realizar dicha tarea puede reducir el rendimiento porcentual a cifras de un solo dígito.
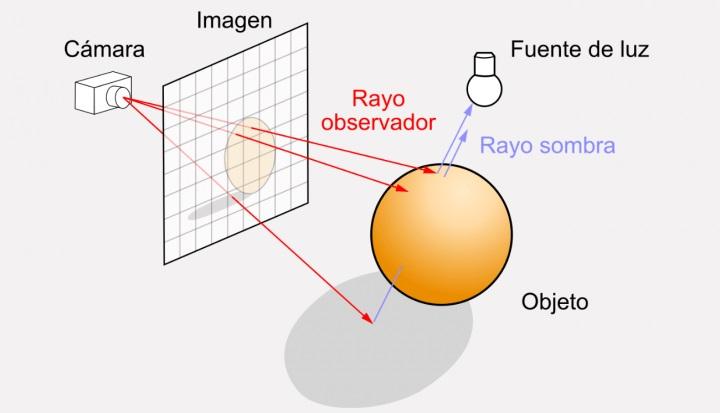
Las unidades de intersección por hardware
Es por ello que NVIDIA tiene los RT Cores y AMD los Ray Accelerator Units, son lo mismo, dado que son el mismo tipo de unidad y se usan para la misma tarea. Sin embargo, en la generación pasada, las RX 6000 tenían una limitación que por suerte el RTG ha solventado en RDNA 3 y, en consecuencia, en la gama RX 7000.

¿Cuál es el problema entonces?
- Lo bueno, y, por tanto, lo positivo, es que ahora lo que faltaba en RDNA 2 se ha incluido en RDNA 3.
- Lo malo y que hace que tengamos un pobre rendimiento del Ray Tracing en AMD es la cantidad de interacciones rayo-triángulo que puede calcular. Un salto de solo el 50% es muy pobre cuando su rival ha duplicado el rendimiento de una generación a otra.
No olvidemos que las primeras tarjetas 3D que aparecieron en el mercado se encargaron de ir acelerando cada vez más la operación de la rasterización de triángulos, la cual es la más común en ese aspecto. Lo mismo ocurre con esta parte en el trazado de rayos. Por eso el hecho de que AMD haya dado un salto tan pequeño en este aspecto, es decepcionante.
¿Cómo afecta al rendimiento global?
Si bien, la intersección de rayos es una parte del conjunto, se trata de un elemento común en todas las escenas que es imprescindible. No olvidemos que se trata de un proceso que va por etapas donde el hecho que una vaya más lenta de lo normal acaba afectando el rendimiento de las posteriores.
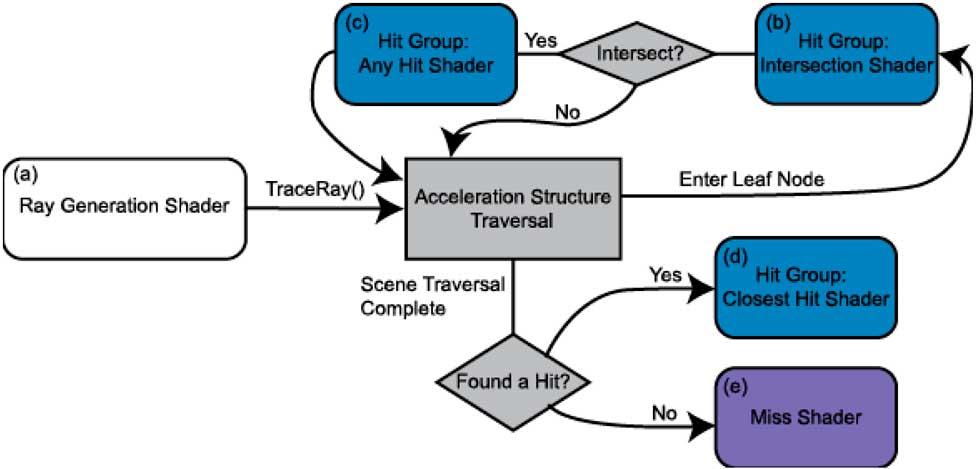
Por lo que si conseguimos acelerar una etapa obtenemos un tiempo menor en generar el mismo fotograma, es decir, se tardan menos milisegundos y esto son más frames por segundo. Lo que se tiene que quedar claro es que el proceso de intersección es recursivo y continuo en el Ray Tracing y, por tanto, es necesario que esa parte tenga un buen rendimiento.
El otro problema: el rendimiento en coma flotante
Las GPU suelen trabajar con bloques de datos al unísono, a los que se les aplica la misma instrucción. Es por ello que su tipo de unidad por antonomasia son lo que llamamos unidades SIMD, las cuales, como su nombre indica, aplican la misma instrucción a varios datos distintos al mismo tiempo. Pues bien, NVIDIA en las RTX 30 hizo una mejora bastante curiosa que le permite calcular el doble de operaciones en coma flotante de 32 bits por ciclo de reloj y núcleo.
El truco consistió en añadir una segunda unidad SIMD de 16 elementos en cada uno de los sub-núcleos para un total de 64 operaciones por ciclo adicionales por unidad dentro de la GPU. Sin embargo, no ampliaron el número de registros, ni de accesos, dado que las conmutaron con la unidad de enteros. ¿En qué se traduce esto? Tanto las RTX 30 como las RTX 40 alcanzan el doble del rendimiento en coma flotante en ciertas condiciones, no siempre.
AMD, en cambio, ha buscado otra solución a la que han llamado Dual Issue, pero en sus especificaciones técnicas hablan de que la cantidad de unidades en coma flotante no ha aumentado, pero que en ciertas condiciones pueden empaquetar 2 instrucciones al mismo tiempo. Sin embargo, la cantidad de unidades por núcleo o Compute Unit sigue siendo de 64 como máximo, en vez de 128, como en el caso de NVIDIA.
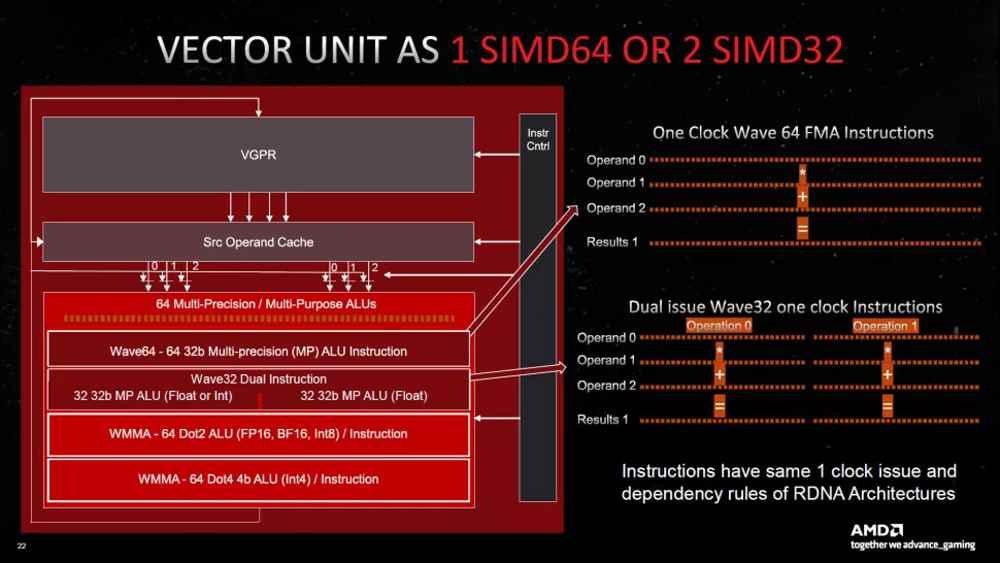
¿Qué quiere decir AMD con «Dual Issue» en RDNA 3?
Sin embargo, si contáis la cantidad de operaciones en coma flotante que dio AMD, las cuales se suelen dar en un máximo teórico realizando el 100% del tiempo la operación FMA o suma con multiplicación en coma flotante, la cual no es realista, ya que no tiene en cuenta accesos a memoria y el hecho que los programas no usan siempre dicha instrucción, pero sí que es la más usada a la hora de generar gráficos. El caso es que la instrucción son 2 operaciones.
Pues bien, lo que ha hecho AMD es que ciertas instrucciones se puedan empaquetar de dos en dos en las unidades de cálculo, permitiendo alcanzar el doble de potencia en coma flotante que con RDNA 2 en ciertas condiciones. Es el mismo caso que con las GPU de NVIDIA. La potencia adicional en coma flotante no se duplica en general, sino solo en ciertas condiciones. Por lo que es un problema común. En todo caso, la medida en TFLOPS no deja de ser a día de hoy un truco de marketing.
¿Entonces por qué es importante de cara al rendimiento de AMD en Ray Tracing? Pues por el hecho que nos sirve para medir la potencia de cálculo de las unidades que se usan en el resto de etapas del trazado de rayos que no son la intersección de rayos. En todo caso, la propia AMD afirma que la mejora intergeneracional es del 18% a igualdad de velocidad de reloj.
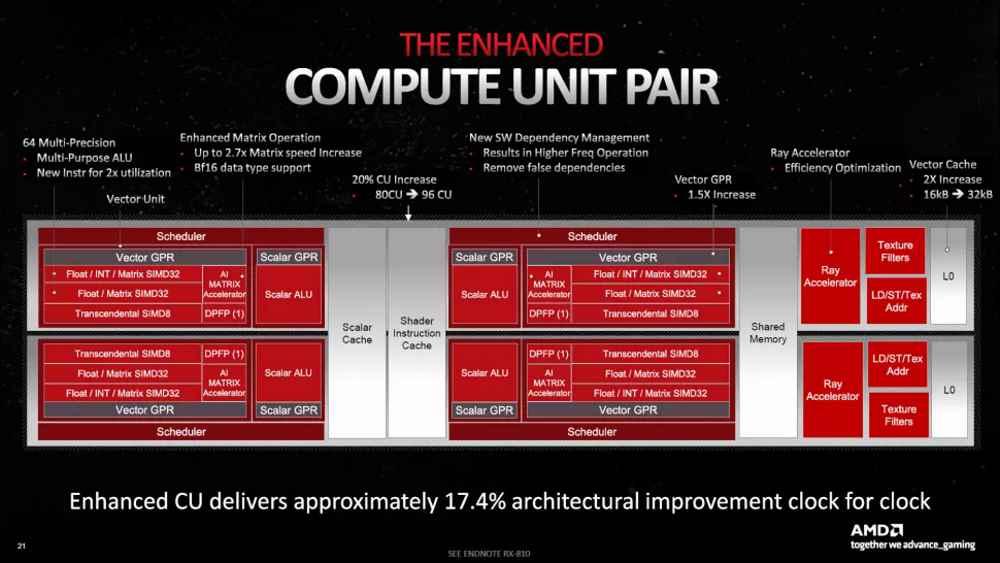
El rendimiento de las GPU de AMD en Ray Tracing: los números
Si comparamos el rendimiento de las diferentes unidades de intersección tanto en las diferentes generaciones de tarjetas gráficas de NVIDIA como de AMD, veremos cuál es el problema.
| GPU | Intersecciones/s (en millones) | Núcleos | MHz | Intersecciones (núcleo y MHz) |
|---|---|---|---|---|
| RTX 2080 Ti | 105600 | 68 | 1545 | 1 |
| RTX 3090 Ti | 312480 | 84 | 1860 | 2 |
| RTX 4090 | 1290240 | 144 | 2520 | 3.6 |
| RX 6950 XT | 184800 | 80 | 2310 | 1 |
| RX 7900 XTX | 360000 | 96 | 2500 | 1.5 |
A primera vista la potencia bruta en ese aspecto es superior a la de una RTX 3090 Ti, eso sí, nos fijamos en la segunda columna. Sin embargo, lo que es importante es la última, ya que nos dice cuántas intersecciones se calculan por núcleo y ciclo de reloj en la GPU. Y la decepción llega por el hecho que si bien no se le pide a AMD que del resultado de 3.6 de la RTX 40, sí que se le pide al menos que llega al 2 de las RTX 30. Este es el motivo principal del pobre rendimiento de las tarjetas gráficas de AMD en Ray Tracing. Y el motivo por el cual creemos que lo podrían haber hecho mucho mejor.
Es más, y ya para terminar, debido a que la Ray Accelerator Unit es una caja negra en sí mismo que puede ser reemplazada sin afectar al resto de la arquitectura. AMD puede coger y hacer una gama RX 7×50 para el futuro año que conserve todas las bondades de las RDNA 3 actuales, pero con la RAU mejorada y ver como el rendimiento de los juegos aumenta en porcentajes de dos cifras en lo que a la tasa de frames se refiere.
¿Cuál es el rendimiento de las juegos AMD con Ray Tracing en RDNA 3?
Ya para terminar nos queda la cereza en el pastel y hablar de como rinde en juegos. Debido a que AMD públicamente afirmo una mejora del 50%, deberíamos esperar un salto igual de grande. Sin embargo, luego descubrimos que se refieren a rendimiento por vatio, a una cantidad de estos determinados y con un juego en concreto, el cual no ha sido especificado. Por lo que lo importante es saber cuál ha sido la mejora respecto a la generación anterior, en este aspecto, en especial por el hecho que parten de un rendimiento más bien pobre en trazado de rayos que es de la RX 6000.