
Con las RTX 3000 en el mercado y con pocas unidades disponibles en las tiendas por la minería el hecho de pensar en la siguiente generación de NVIDIA es bastante precipitado, especialmente cuando no se espera hasta finales de 2022, pero lo que sabemos es suficiente para hacernos una idea de lo que nos podríamos encontrar con las NVIDIA Lovelace.
La arquitectura NVIDIA Lovelace no va a ser lanzada hasta el año 2022, haciendo uso del nodo de 5 nm de TSMC, aunque este último detalle no podemos asegurarlo todavía, ya que también se especuló con el nodo de 7 nm de TSMC para las actuales RTX 3000 y al final NVIDIA ha hecho uso del nodo de 8 nm de Samsung. En todo caso por el momento es una gran incógnita y lo poco que sabemos crea ciertas dudas que no se han tenido en cuenta, en especial en cuanto a configuración de algunas partes y ancho de banda.
Lo que sabemos de la arquitectura NVIDIA Lovelace

De todo lo poco que sabemos de las futuras NVIDIA Lovelace, lo que sorprende es su configuración, la cual sabemos gracias al insider de NVIDIA Kopite7kimi, quien recordemos es una de las fuentes más fiables tras haber adelantado las especificaciones de las RTX 3000 basadas en la arquitectura GeForce Ampere con un año de antelación. ¿Su información sobre GeForce Lovelace? El chip tope de gama, AD102, tendrá una configuración de 12 GPC en vez de los 7 GPC de la TU102.
| GPU | Núcleos CUDA |
|---|---|
| GM200 | 2816 |
| GP102 | 3584 |
| TU102 | 4608 |
| GA102 | 10752 |
| ¿AD102? | 18432 |
A lo que Kopite hace referencia es a la cantidad de GPCs y la cantidad de TPC por GPC. Hay 2 SM o Compute Unit por GPC y un total de 128 núcleos CUDA en el caso de las GeForce Ampere, que debería heredar Lovelace. Esto hizo que aparecieran noticias acerca de una configuración de 18.432 núcleos CUDA o ALUs en FP32, una cantidad que resultaría el salto más grande en ese aspecto de las últimas generaciones de GPUs de NVIDIA.
¿Qué problema tienen estas especificaciones? En especial de cara al ancho de banda, el cual tiene relación con el consumo energético, y es que el aumento en la cantidad de GPCs supone un aumento en la cantidad de ciertas unidades que tendrán que ser recortadas para hacer posible esta configuración.
Una suposición con pies de barro

Lo primero que tenemos que tener en cuenta es que la configuración de una GPU escala con la memoria VRAM que tiene asignada y no tenemos referencia que NVIDIA vaya a utilizar ningún tipo de memoria especial para poder alimentar un total de 12 GPC de Lovelace. Es cierto que a nivel de tamaño de la GPU no pueden ir mucho más allá con la GA102, la cual está casi rozando el límite del tamaño aceptado por el nodo de 8 nm de Samsung y que el nodo de 5 nm podría duplicar los transistores, pero la pregunta es: ¿existe la memoria para alimentar tal cantidad de GPCs? Estamos hablando de casi duplicar el ancho de banda, cosa que no podemos hacer con la GDDR6X.
Es posible que NVIDIA haga uso de la FG-DRAM que ha estado desarrollando, pero este tipo de memoria parece estar más enfocada de cara al mercado HPC que no al mercado doméstico, si es que NVIDIA alguna vez la desarrolla. Por lo que NVIDIA tendrá que conformarse con la GDDR6X, la cual se puede convertir en un enorme cuello de botella.
Continuar con una organización como la las GeForce Ampere, supone que la carga sobre la VRAM aumentará considerablemente, no solo por parte de los SM, sino también de unidades de función fija, especialmente unidades de texturas y los ROPS que son las unidades de este tipo que más datos leen y escriben desde la VRAM, las cuales en la nueva configuración aumentarían considerablemente.
Posibles cambios en ROPS y unidades de texturas en Lovelace
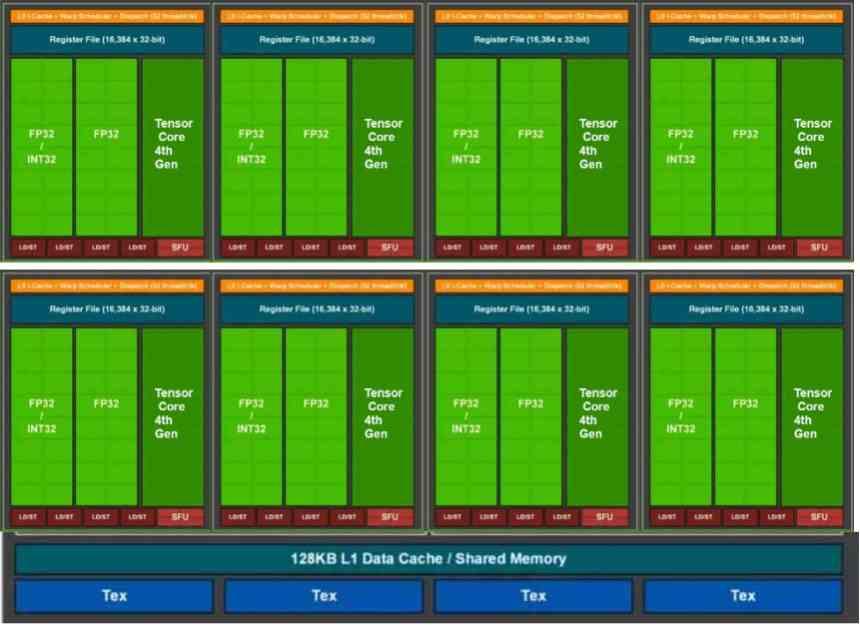
Si contamos la cantidad de ROPS en la actual GA102 veremos que hay un total de 112 ROPS, habiendo 7 GPC en dicha GPU esto son 16 ROPS por GPU, una configuración de 12 GPC con 16 ROPS elevaría la cantidad hasta los 192 ROPS. Desde el momento que los ROPS son los que escriben los píxeles ya finalizados en la VRAM el ancho de banda necesario se duplica. ¿La solución? Reducir la cantidad de ROPS por GPC de 16 a 8, lo que hacen un total 96 ROPS, una cifra más de acorde para un bus de 384 bits GDDR6X.
El otro punto son las unidades de texturas, en Maxwell el ratio de ALUs en FP32 por unidad de texturas era 16 ALUs. Dado que las unidades de texturas van de 4 en 4 en las SM, esto hacen un total de 64 ALUs en FP32 dentro de las SM de dichas arquitecturas. Ratio que se ha roto en Ampere en su configuración, ya que en ciertos momentos puede ser de 128 ALUs por SM. ¿Lo que creemos? Pensamos que lo vamos a pasar es de una configuración de 4 Sub-Cores por SM a 8 Sub-Cores por SM, de esta manera la carga sobre la VRAM será mucho menor de parte de las unidades de texturas que hay en la GPU, pero el ratio volverá a aumentar a 64 ALUs en FP32 o nucleos CUDA por unidad de texturas.
La conclusión que sacamos, en cuanto a los cambios necesarios es que la potencia RTX 3090 o RTX 3080 Ti aumentará considerablemente su tasa de FLOPS, pero no de igual manera su tasa de relleno de texturas o de píxeles, lo cual tiene sentido en la transición a GPUs cada vez más centradas en el Ray Tracing.