
Hace unas semanas apareció publicada una patente asignada a AMD, en ella se explica como van a funcionar sus GPUs divididas en varios chips, lo cual va a ser norma general no solo para ellos sino también para la competencia. Donde sabemos que NVIDIA Hopper y Intel Xe-HP se dividen en varios chips. Pero la solución de AMD es algo distinta que la propuesta por su competencia, os explicamos la patente de los chiplets de AMD.
El motivo por el cual las GPUs duales han desaparecido del ámbito doméstico y es la respuesta a la pregunta de p por el cual ya no vemos tarjetas gráficas compatibles con NVIDIA SLI o AMD Crossfire es el mismo, las aplicaciones que utilizamos en nuestros PCs están programadas para utilizar una sola GPU.

En los videojuegos de PC, a la hora de hacer uso de una GPU dual. se utilizan técnicas como el Alternate Frame Rendering, en la que cada GPU renderiza un fotograma alterno respecto a la otra, o el Split Frame Rendering donde el par GPU se dividen el trabajo de un solo frame.
En computación vía GPU no ocurre este problema, es por ello que en sistemas en los que las tarjetas gráficas no son utilizadas para renderizar gráficos nos encontramos varias de ellas funcionando en paralelo sin problemas. Es más, las aplicaciones que hacen uso de las GPUs como procesadores de datos en paralelo ya están pensadas para aprovechar las GPUs de esa manera.
El aumento del tamaño de las GPUs en los últimos años

Si observamos la evolución de las GPU en los últimos años, veremos ha habido un crecimiento considerable en cuanto al área de las GPU tope de gama de una generación a otra.
¿Lo peor del escenario presente? No hay una GPU que tenga todavía el rendimiento ideal para jugar a 4K. Se ha de tener en cuenta que una imagen a 4K nativo tiene 4 veces más píxeles que una a 1080p y por tanto hablamos de un movimiento de datos que cuadriplica al necesario para Full HD.
En la situación actual en la VRAM, tenemos el caso de la GDDR6, dicha memoria utiliza una interfaz de 32 bits por chip, dividida en dos canales de 16 bits, pero, con una velocidad de reloj que hace su consumo energético se dispare, lo que nos lleva a buscar otras soluciones para ampliar el ancho de banda.
Ampliando el ancho de banda de la VRAM

Si queremos ampliar el ancho de banda existen dos opciones:
- La primera es aumentar la velocidad de reloj de la memoria, pero, se ha de tener en cuenta que el voltaje se eleva al cuadrado al subir los MHz de esta, y con ello el consumo energético.
- La segunda, es aumentar la cantidad de pines, lo que sería pasar de los 32 bits a los 64 bits.
No podemos olvidar tampoco de cosas como el PAM-4 utilizado en la GDDR6X, pero eso ha sido un movimiento por parte de Micron de cara a evitar llegar altas velocidades de reloj. Por lo que un bus de 64 bits por chip de VRAM deberíamos esperarlo para una eventual GDDR7..
No sabemos lo que van a hacer los fabricantes de VRAM, pero aumentar la velocidad de reloj no es la opción que creemos que acaben adoptando dentro de un presupuesto limitado en cuanto al consumo energético.

No sabemos lo que van a hacer los fabricantes de VRAM, pero aumentar la velocidad de reloj no es la opción que creemos que acaben adoptando.
Ahora bien, las interfaces entre la GPU y la VRAM se sitúan en la parte exterior del perímetro de la propia GPU. Por lo que aumentar la cantidad de bits de la misma es expandir la periferia de dicha GPU, y por tanto hacer que sea más grande.
Lo que supone una sería de problemas añadidos debido al alto tamaño en cuanto a coste, esto obligará a los fabricantes de tarjetas gráficas a utilizar varios chips en vez de uno, y es en este punto donde entramos en los llamados chiplets.
Tipos de GPUs basadas en Chiplets

Hay dos formas de dividir una GPU en Chiplets:
- Dividir una única GPU de tamaño masivo en varios chiplets, la contrapartida de esto es que la comunicación entre las diferentes partes requiere un ancho de banda masivo que puede no ser viable sin uso de intercomunicaciones especiales.
- Utilizar varias GPUS en un mismo espacio que funcionen de manera conjunta como una sola.
En el artículo de HardZone titulado “Así serán las GPUs basadas en Chiplets que veremos en el futuro” podéis leer sobre la configuración de las del primer tipo, en cambio la patente de AMD respecto a su GPU con chiplets hace referencia a las del segundo tipo.
Explorando la patente de los chiplets de AMD:
El primer punto que aparece en toda patente es la utilidad de la invención, la cual viene siempre en su trasfondo, el cual en la que nos ocupa es la siguiente:
Los diseños monolíticos convencionales que están volviendo cada vez más caros de fabricar. Los chiplets se han utilizado con éxito en las arquitecturas de CPU para reducir el coste de fabricación y mejorar los yields. Ya que su naturaleza computacional heterogénea se adapta de forma más natural a los núcleos de la CPU separados en unidades distintas que no requieren mucha intercomunicación entre ellas.
La mención a las CPUs está claro que hace referencia a los AMD Ryzen y es que buena parte del equipo de diseño de las arquitecturas Zen fue desplazado al Radeon Technology Group para trabajar en mejorar la arquitectura RDNA. El concepto de los chiplets no es el primero heredado de los Zen, el otro es la Infinity Cache, la cual hereda el concepto de “Victim Cache” de los Zen.
En segundo lugar, el problema de la intercomunicación al que hace referencia se refiere al enorme ancho de banda que necesitan las GPUs para comunicar sus elementos entre si. Lo cual es el impedimento de cara a la construcción de estas en chiplets, por la energía consumida en la transferencia de datos.
El trabajo de una GPU es en paralelo por su naturaleza. Sin embargo, la geometría que se procesa una GPU no solo incluye secciones de trabajo en paralelo, sino también trabajos que requieren estar sincronizados en un orden concreto entre las diferentes secciones.
¿La consecuencia de ello? Un modelo de programación para una GPU que distribuye el trabajo en diferentes subprocesos suele ser ineficiente, ya que el paralelismo es difícil de distribuir entre múltiples grupos de trabajo y chiplets diferentes, dado que es difícil y costoso sincronizar el contenido de la memoria de los recursos compartidos en todo el sistema.

La parte que os hemos puesto en negrita es la explicación desde la perspectiva del desarrollo de software por el cual no hemos visto GPUs basadas en chiplets. No solo es un problema de hardware sino de software, por lo que es necesario simplificar.
Además, desde un punto de vista lógico, las aplicaciones se escriben con la visión de que el sistema solo tiene una GPU. Es decir, aunque una GPU convencional incluye muchos núcleos de GPU, las aplicaciones se programan para que se dirijan a un solo dispositivo. Por lo tanto, históricamente ha sido un desafío llevar la metodología de diseño de chiplet a las arquitecturas de GPU.
Esta parte es clave para entender la patente, AMD no esta hablando de dividir una sola GPU en chiplets que es lo que hace en sus CPUs, sino que habla de utilizar varias GPUs en la que cada una es un chiplet, es importante tener en cuenta esta diferencia, ya que la solución de AMD parece más enfocada a crear un Crossfire en el que no sea necesario que los programadores adapten sus programas para varias GPUs.
Definido el problema, el siguiente punto es hablar de la solución que ofrece la patente.
Explorando la patente de los chiplets de AMD: La solución
La solución al problema expuesto que propone AMD es la siguiente:
Para mejorar el rendimiento del sistema utilizando chiplets de GPU mientras se mantiene el actual modelo de programación, la patente ilustra sistemas y métodos que utilizan crosslinks pasivos de alto ancho de banda para conectar entre si los chiplets de la GPU.
La parte importante de la patente son esos Crosslinks, de los cuales hablaremos más adelante en este mismo artículo, estos son la interfaz de comunicación entre los diferentes chiplets, es decir, como se transmiten la información entre ellos.
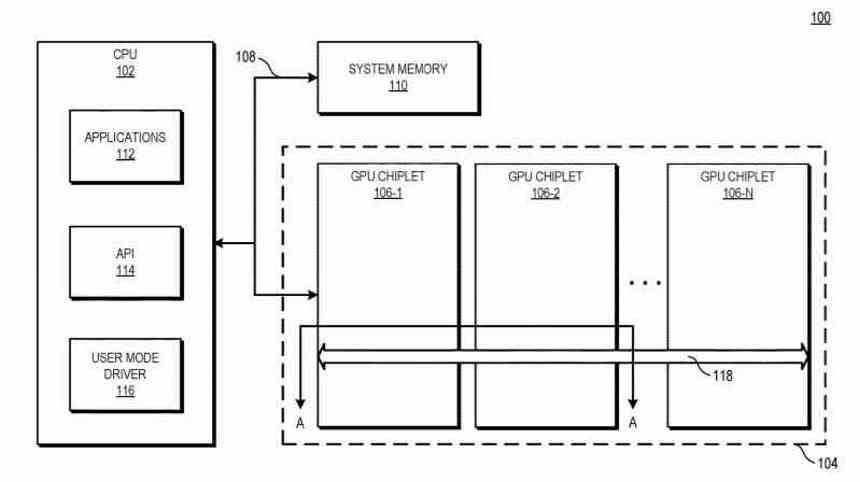
En varias implementaciones, un sistema incluye la unidad central de proceso (CPU) que esta conectada al primer chiplet GPU de la cadena, el cual esta conectado a un segundo chiplet a través del crosslink pasivo. En algunas implementaciones el crosslink pasivo es un interposer pasivo que se encarga de la comunicación entre chiplets.
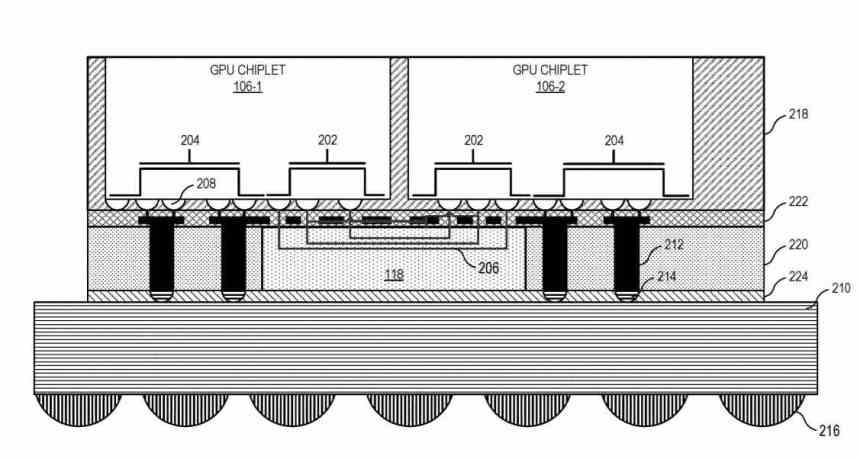
Básicamente, se resume en que pasamos a tener una GPU dual funcionando como una sola, la cual esta compuesta de dos chips interconectados a través de un interposer que estaría situado debajo.
Crosslinks pasivos de alto ancho de banda
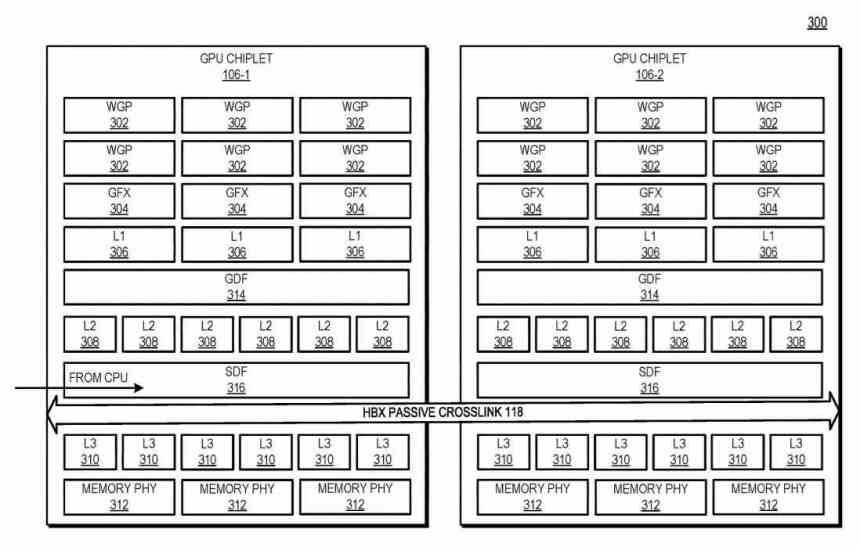
¿Cómo se comunican los chiplets con el interposer? Utilizando un tipo de interfaz que comunica el Scalable Data Fabric (SDF) de cada uno de los chiplets entre si, el SDF en las GPUs de AMD es la parte que se sitúa normalmente entre entre la caché de último nivel de la GPU y la interfaz de memoria, pero en este caso existe una caché L3 entre el SDF de cada chiplet GPU y el SDF y antes de ello una interfaz que intercomunica los ambos chiplets entre si.
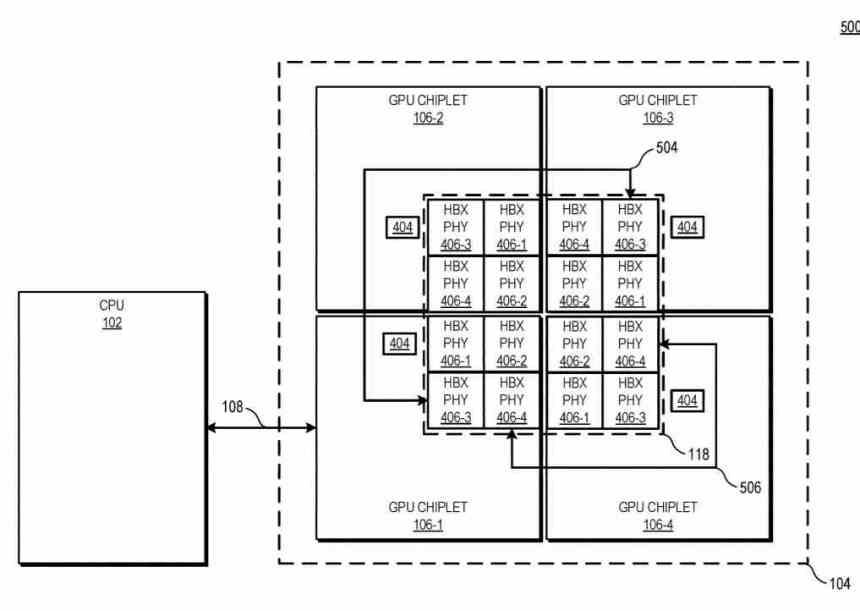
En este diagrama se puede ver el ejemplo con 4 GPUs chiplets, la cantidad de interfaces HBX es siempre 22 en el que n es la cantidad de chiplets existentes en el interposer. De cara al nivel de la jerarquía de cachés, la L0 (no descrita en la patente) es local de cada Compute Unit, la L1 de cada Shader Array, la L2 de cada chiplet GPU, mientras que la cache L3 sería una novedad, esta es descrita como la cache de último nivel o LCC del conjunto de toda la GPU al completo
Actualmente, varias arquitecturas tienen al menos un nivel de caché que es coherente para toda la GPU al completo. Aquí, en una arquitectura de GPU basada en chiplets coloca esos recursos físicos en chips distintos y los comunica de tal manera que dicha caché de último nivel se mantenga coherente para todos los chiplets de la GPU. Así pues, pese a operar en un entorno masivamente paralelizado, la caché L3 ha de ser coherente.
Durante una operación, la petición a una dirección de memoria de la CPU a la GPU es transmitida a un solo chiplet de la GPU, la cual se comunica con el crosslink pasivo de alto ancho de anda para localizar los datos. Desde el punto de la CPU, parece que se esta dirigiendo a una GPU monolítica de un solo chip. Esto permite el uso de una GPU de alta capacidad, compuesta por varios chiplets como si si fuese una sola GPU para la aplicación.
Es por esto que la solución de AMD no es la división de una GPU en varios chiplets distintos, sino el uso de varias GPUs como si fuese una sola, solucionando con ello uno de los problemas que traía consigo el AMD Crossfire y permitiendo que cualquier software pueda utilizar varias GPUs al mismo tiempo como si fuesen una sola y sin necesidad de tener que adaptar el código.
La otra clave de los crosslinks pasivos es el hecho que al contrario de lo que muchos especulábamos, estos no se comunican con la GPU haciendo uso de vías a través de silicio o TSV, sino que AMD ha creado una intercomunicación propietaria para la construcción de SoCs, CPUs y GPUs, tanto en 2.5DIC como 3DIC, lo que nos lleva a preguntarnos si la interfaz X3D que ha de reemplazar a su Infinity Fabric.
Los chiplets de AMD son para RDNA 3 en adelante

El hecho que el problema a la hora de utilizar varias GPUs no sea un problema de las aplicaciones pensadas para la computación a través de GPU deja muy claro que la solución planteada por AMD en su patente esta dirigida al mercado doméstico, en concreto a las GPUs de las arquitecturas RDNA, hay varias pistas acerca de ello:
- En los diagramas de los chiplets de la patente aparece el termino WGP, el cual es propia de la arquitectura RDNA y no de CDNA y/o GCN.
- La mención en una parte de la patente del uso de memoria GDDR, lo cual es típico de las GPUs domésticas.
La patente no nos describe una GPU en concreto, pero podemos suponer que AMD lanzará la primera GPU dual basada en chiplets cuando lance RDNA 3 al mercado. Esto le permitirá a AMD crear una sola GPU en vez de diferentes variaciones de una arquitectura en forma de diferentes chips como ha ido ocurriendo esta la actualidad.

La solución de AMD contrasta además con lo que se rumorea de NVIDIA e Intel. De la primera sabemos que Hopper será su primera arquitectura basada en chiplets, pero desconocemos su mercado objetivo, por lo que bien puede estar dirigida al mercado de la computación de alto rendimiento como el gaming.
En cuanto a Intel, sabemos que Intel Xe-HP es una GPU compuesta también por chiplets, pero sin la necesidad de una solución como la de AMD, ya que el objetivo de Intel para dicha GPU no es el mercado doméstico.