¿Por qué las GPUs consiguen más rendimiento entre generaciones que las CPUs?

Muchas críticas han habido y seguro habrá con el aumento de rendimiento en los procesadores a cada cambio generacional. Con Intel al mando hemos visto cómo las diferencias de rendimiento han sido mínimas durante muchos años, hasta ahora. Entre tanto, las GPUs han multiplicado varias veces su performance, ¿cómo es posible que esto ocurra cuando por ejemplo en el caso de AMD han usado un mismo proceso litográfico para procesadores y tarjetas gráficas? ¿cuáles son los motivos?
Hay muchas explicaciones para esta curiosa disparidad, pero la principal y la base de todo es precisamente el destino de cada tipo de hardware y cómo lo enfoca el software. Con esto en mente el abanico de explicaciones se abre y requiere un estudio más concienzudo, ya que vamos desde el proceso litográfico hasta los desarrolladores de software …
Las GPUs siempre avanzan mucho más que las CPU: estos son los motivos

El primer motivo es lógicamente para qué están fabricados los procesadores y las tarjetas gráficas. Como bien sabemos una CPU es un componente extremadamente complejo, el corazón del sistema, pero cuando hablamos de cargas de trabajo para tener una ganancia de rendimiento en un subproceso y con ello en IPC tenemos que tener en cuenta que un factor limitante es precisamente la frecuencia.
Y con ella llega la limitación del nodo de turno. Las mejoras de una arquitectura potencian un Front-End y un Back-End mucho más optimizado, junto con acceso a las cachés y registros hacen que normalmente el rendimiento aumente, pero no podemos olvidar el paralelismo que estas CPUs modernas requieren.
Si sumamos todo lo anterior tenemos un cuello de botella que viene dado siempre y en primer lugar por el proceso litográfico. Incluir más transistores por mm2 es lo más óptimo si quieres incluir más núcleos y con ello aumentar el rendimiento global, pero a nivel de subproceso tenemos que impulsar un hilo a la mayor frecuencia posible. Actualmente estamos en los 5 GHz con Intel, por lo que si teniendo esta limitación aplicamos la Ley de Amdahl (una carga de trabajo es difícil de acelerar y a mayor complejidad se complica, incluso si se paraleliza) tenemos una dificultad que puede ser exponencial en ciertas tareas.
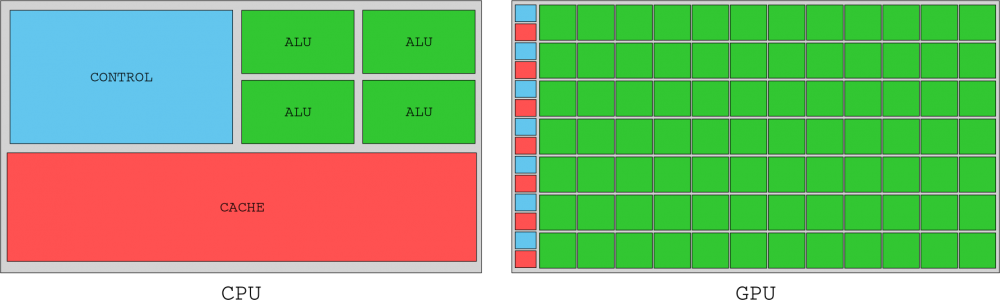
Otro de los puntos a tratar es, como no, las ejecuciones e instrucciones que se añadan a una CPU, donde podemos optimizar y ganar rendimiento de una manera más o menos compleja, pero suelen ser mejoras directas en un subproceso o hilo. Pero claro, una CPU trabaja de manera paralela con tecnologías como la ejecución especulativa o la de orden, por ejemplo, por no hablar del mayor número de núcleos disponibles, cachés y accesos a RAM, o tecnologías como HT o SMT.
Al final todas estas tecnologías lo que intentan es una cosa muy simple: mantener a cada CPU e hilo ocupado el mayor tiempo posible y con un orden lo más perfecto disponible para cada tarea, de manera que no haya delay entre datos. ¿Por qué esto es así y qué diferencia hay con las GPUs?
La super escalaridad y la paralelización, claves en las diferencias entre CPU y GPU
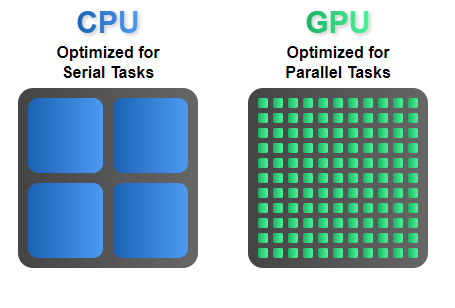
La CPU necesita realizar una gran cantidad de trabajos distintos, simples y complejos, pero además tiene que interconectarse con cualquier componente del PC, lo cual implica recibir información y transmitirla por distintos buses y a una velocidad lo más alta posible. Una GPU en cambio tiene una forma diferente de trabajar, bastante más simple realmente.
El cambio de información, de forma de trabajar, es llamado cambio de contexto y aquí la GPU tiene mucho ganado, ya que por la naturaleza de estas el trabajo que tienen que realizar requiere muy pocos cambios de contexto, ya que es extremadamente paralelizable y las cargas suelen ser homogéneas.
Los desarrolladores trabajan de manera distinta, ya que una GPU tiene tantos núcleos como Shaders integre su silicio, de manera que paralelizar es tremendamente sencillo debido a que pueden integrar hasta 6912 Shaders reales sin demasiado problema (NVIDIA A100) donde cada Shader actúa como un núcleo casi independiente de una CPU.
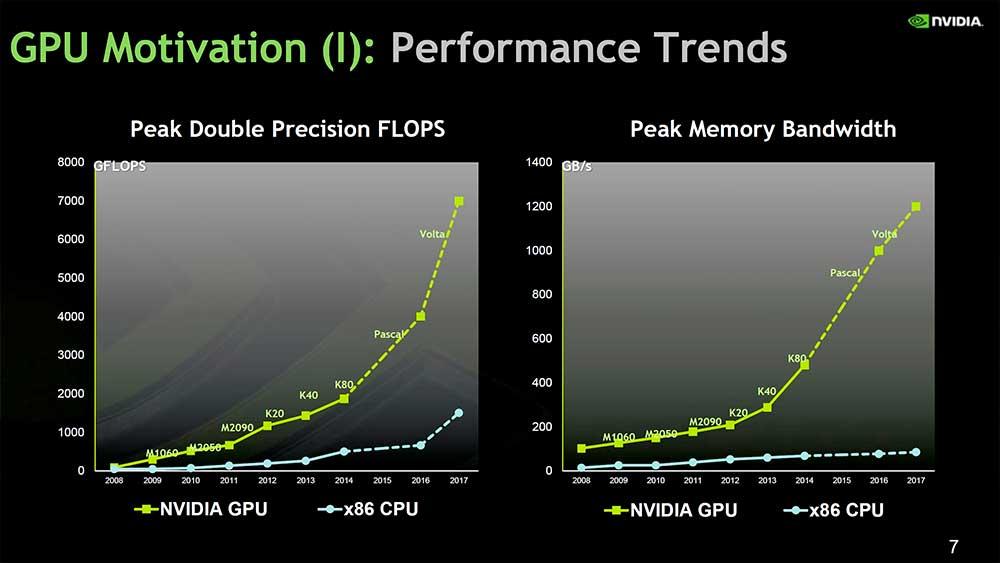
Por ello, disponemos de una gran cantidad de núcleos para trabajar que lógicamente están limitados en rendimiento por la velocidad del nodo para cada chip diseñado y al mismo tiempo por la eficiencia del chip. Hay que tener en cuenta que en GPUs hablamos de dies enormes con consumos impensables para una CPU.
La contrapartida son velocidades menores debido a la naturaleza de la arquitectura, pero en paralelización no tienen rival, por lo que es más fácil escalar rendimiento con ello. Por último, hay que tener en cuenta la Ley de Dennard, de la cual ya hemos hablado más de una vez y que precisamente tiene en cuenta la eficiencia como pilar principal, donde el uso de la energía se mantiene en proporción con el área del chip.
Por lo tanto, si puedes paralelizar una serie de tareas va a ser muy sencillo que añadiendo más núcleos a una GPU logres escalar mucho más el rendimiento, donde además el número de transistores es mucho más grande y con ello el consumo hace lo propio, pero es disipable. Como una GPU no llega al tope de frecuencia de un nodo, no está limitada en este aspecto, sino en la eficiencia, lo cual al tener más margen que una CPU permite ganancias mayores si unimos todo lo explicado.